Understanding Discrete Denoising Diffusion Models
A Survey and a Gap in the Theory
7/15/2025
Today’s Contents
- 1 Mathematical Introduction (-2020)
- 2 Developments in Continuous Diffusion Models (2021-2023)
- 3 Discrete Diffusion Models (2024-)

D3PM (Discrete Denoising Diffusion Probabilistic Model) example from (Ryu, 2024)
1.1 Problem: Bayesian / Generative Modeling
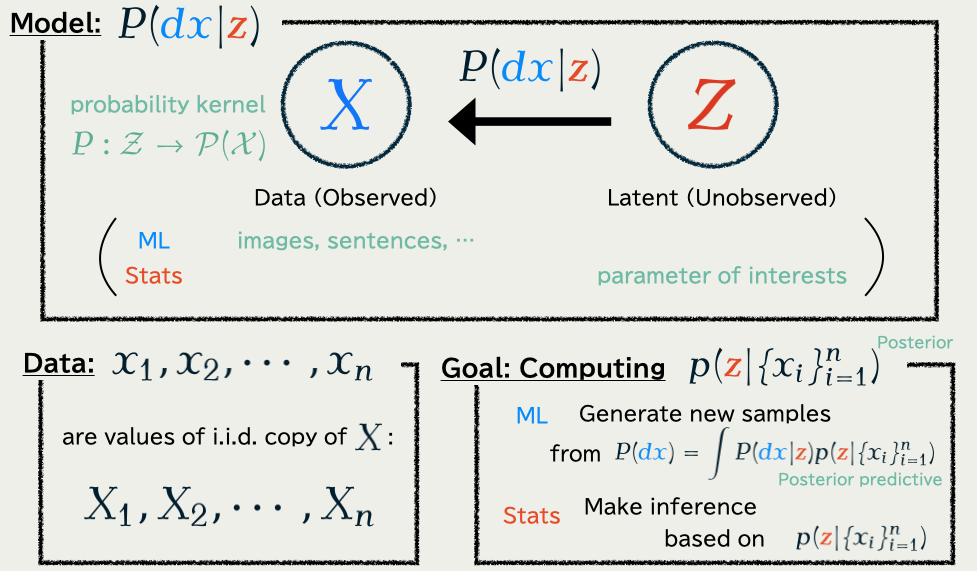
1.3 Markov Chain Monte Carlo

This approach is feasible because …
\text{score function}\quad\nabla\log p(\textcolor{#E95420}{z}|\{x_i\}_{i=1}^n)
is evaluatable.
1.4 Piecewise Deterministic Monte Carlo

- Better convergence
(Andrieu and Livingstone, 2021) - Better scalability
(Bierkens et al., 2019) - Numerical stability
(Chevallier et al., 2025)
Available in our package PDMPFlux.jl
1.6 Variational Auto-Encoder (VAE)
In generative modeling, we also have to learn p\in\{p_{\textcolor{#2780e3}{\theta}}\}_{\textcolor{#2780e3}{\theta}\in\R^e}
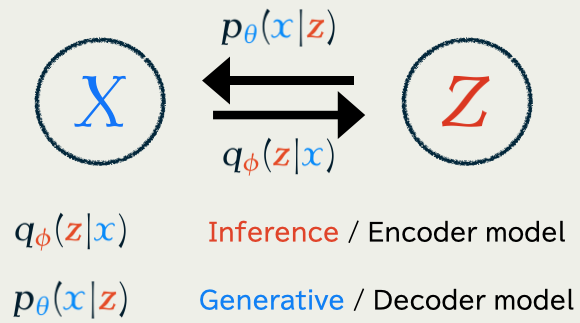
Jointly trained to minimize the KL divergence \operatorname{KL}\bigg(q_{\textcolor{#E95420}{\phi}}(\textcolor{#E95420}{z}|\textcolor{#2780e3}{x}),p_{\textcolor{#2780e3}{\theta}}(\textcolor{#E95420}{z}|\textcolor{#2780e3}{x})\bigg).
1.7 Denoising Diffusion Models (DDM)
Concentrating on learning p_{\textcolor{#2780e3}{\theta}}, we fix q_{\textcolor{#E95420}{\phi}}(\textcolor{#E95420}{z}|\textcolor{#2780e3}{x})=q(\textcolor{#E95420}{z}|\textcolor{#2780e3}{x})=q^{t_1}(\textcolor{#E95420}{z_1}|\textcolor{#2780e3}{x})\prod_{i=1}^T q^{t_{i+1}-t_i}(\textcolor{#E95420}{z_{i+1}}|\textcolor{#E95420}{z_{i}}), as a path measure of a Langevin diffusion on \textcolor{#E95420}{\mathcal{Z}}=(\R^d)^{T+1}.
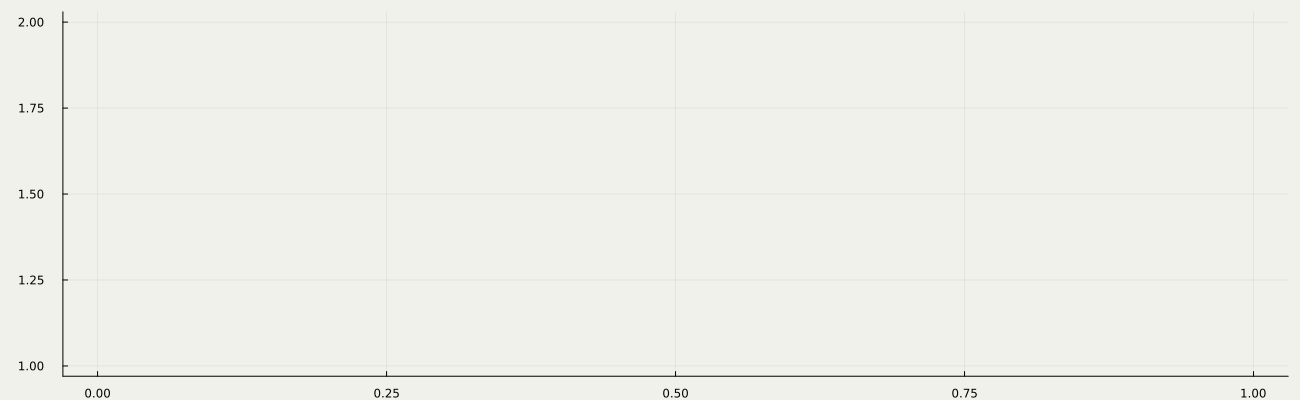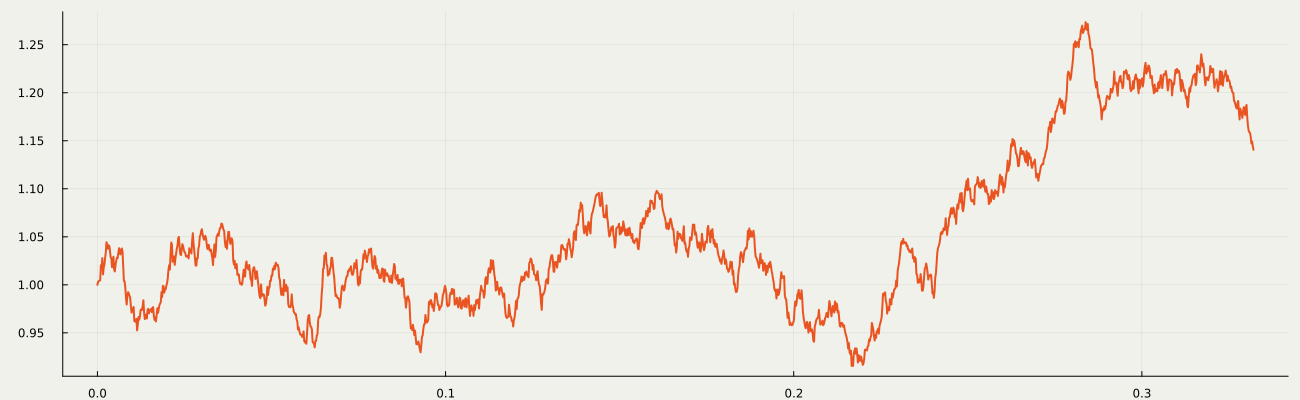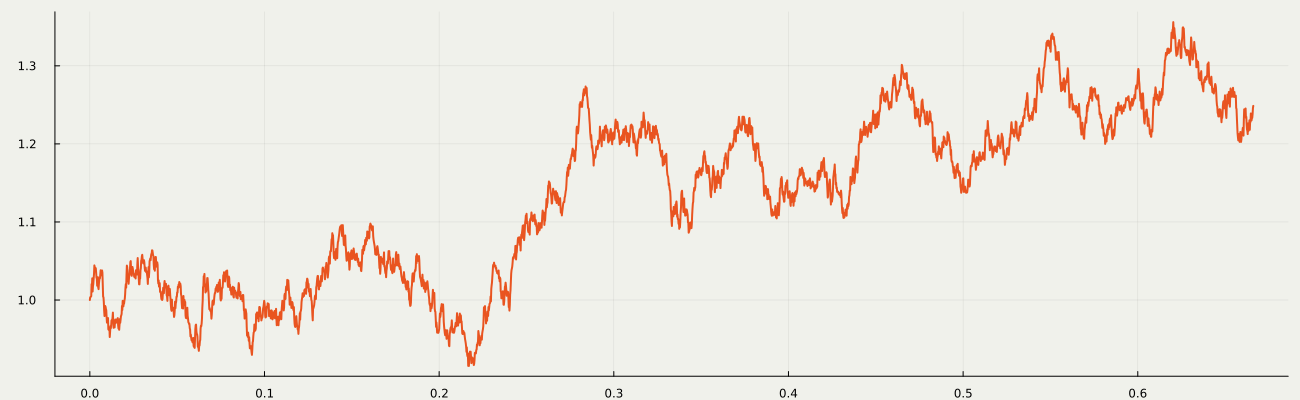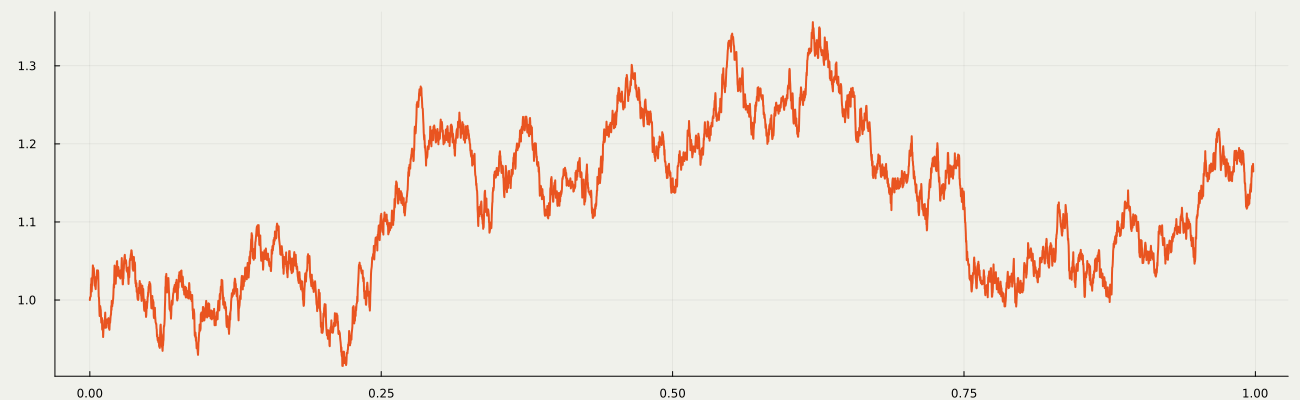
1.7 Denoising Diffusion Models (DDM)
It is because DDM learns how to denoise a noisy data. DDM …
× constrains the posterior to be \operatorname{N}(0,I_d),
○ the whole training objective is devoted to learn the generator p_{\textcolor{#2780e3}{\theta}}
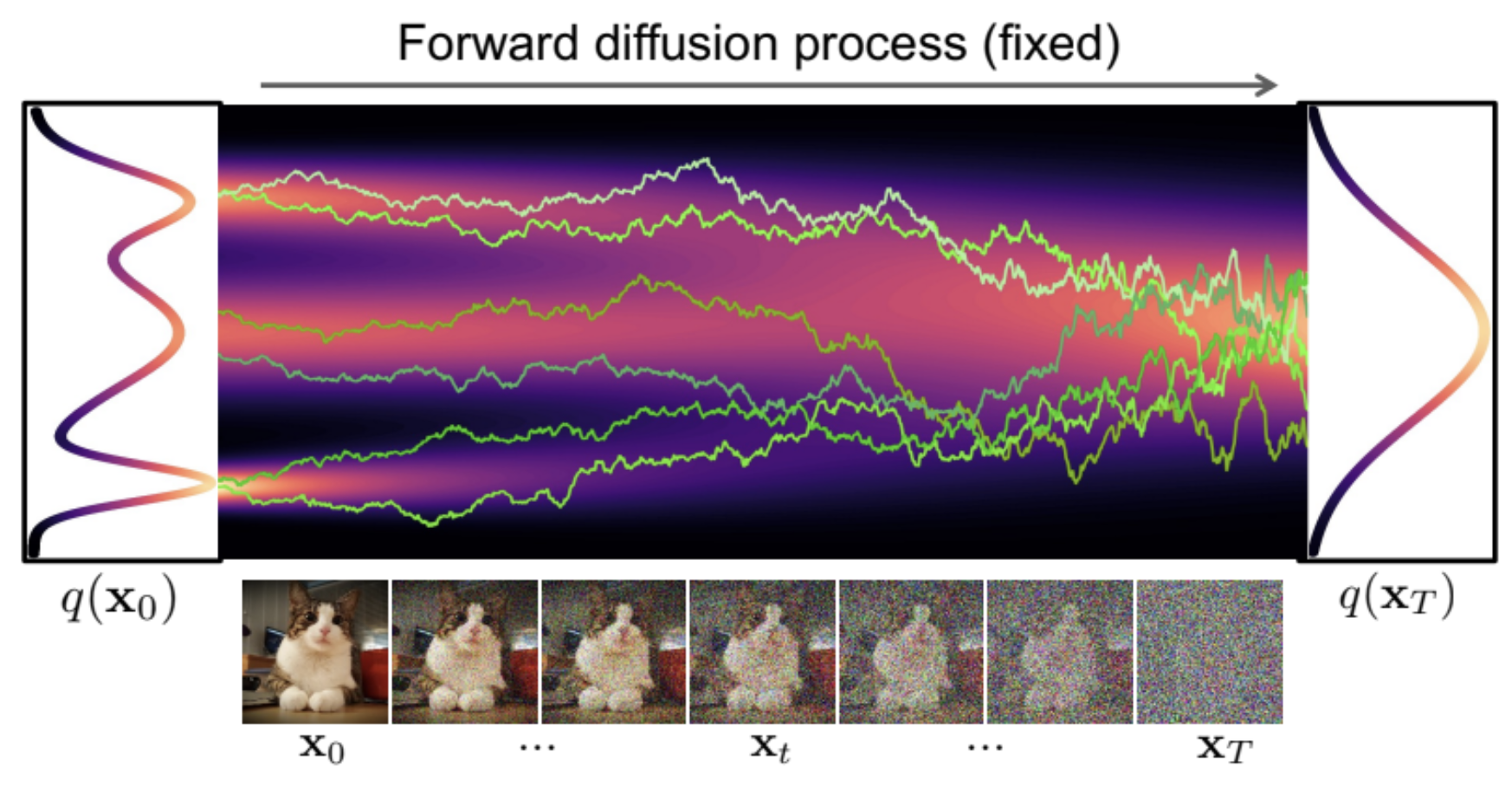
A very famous figure from (Kreis et al., 2022)
2.1 Limit in T\to\infty leads to SDE formulation
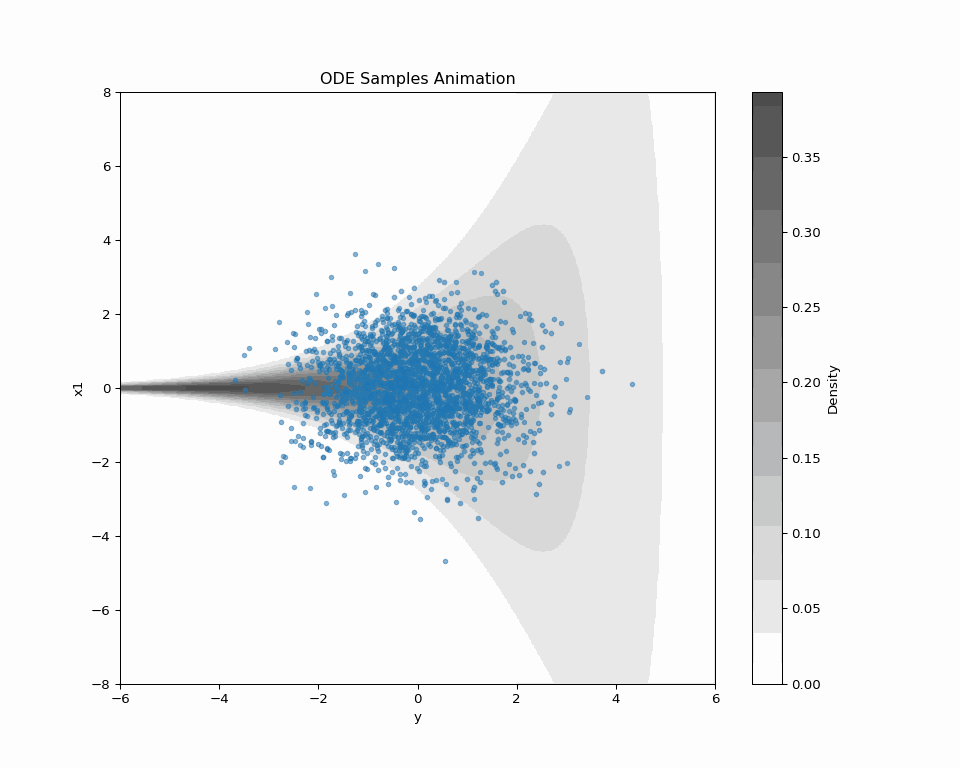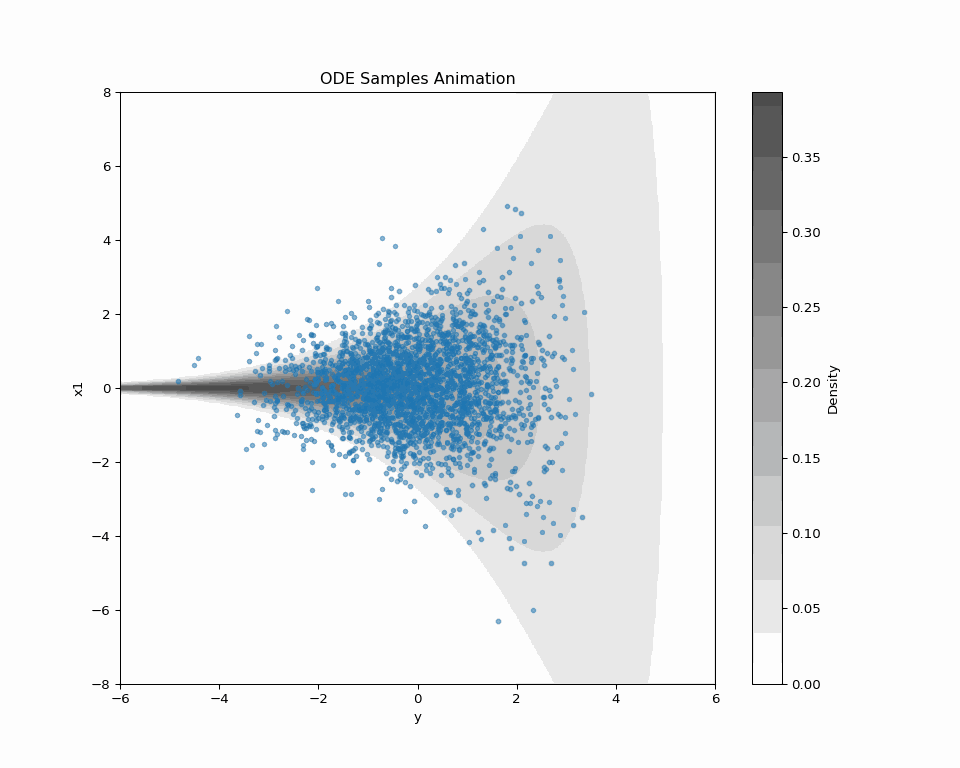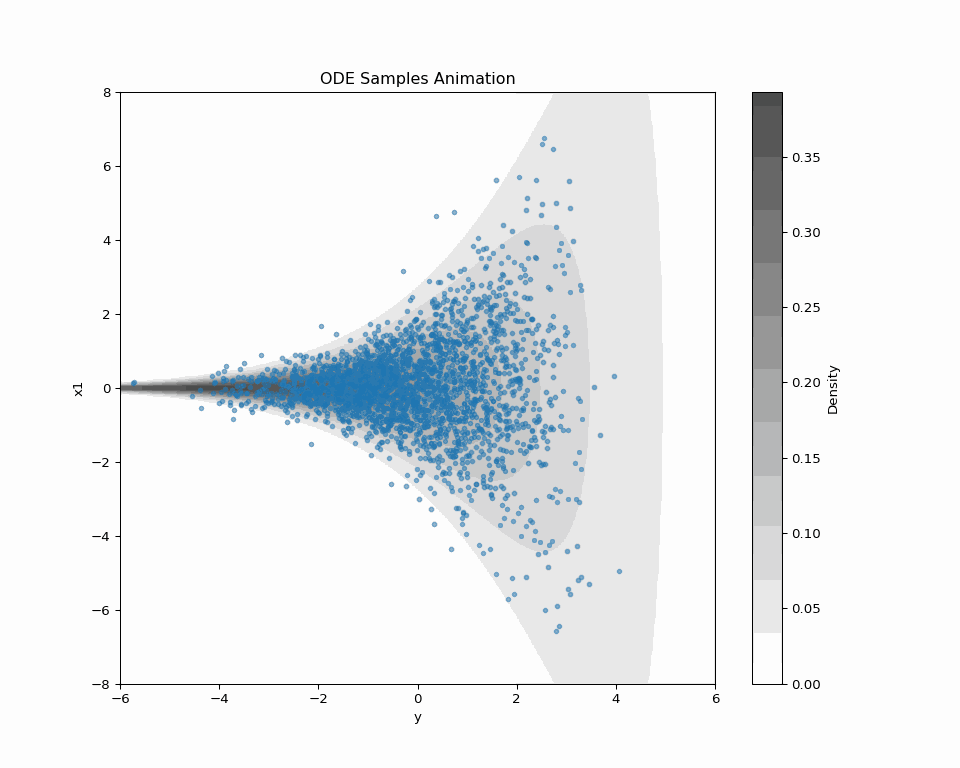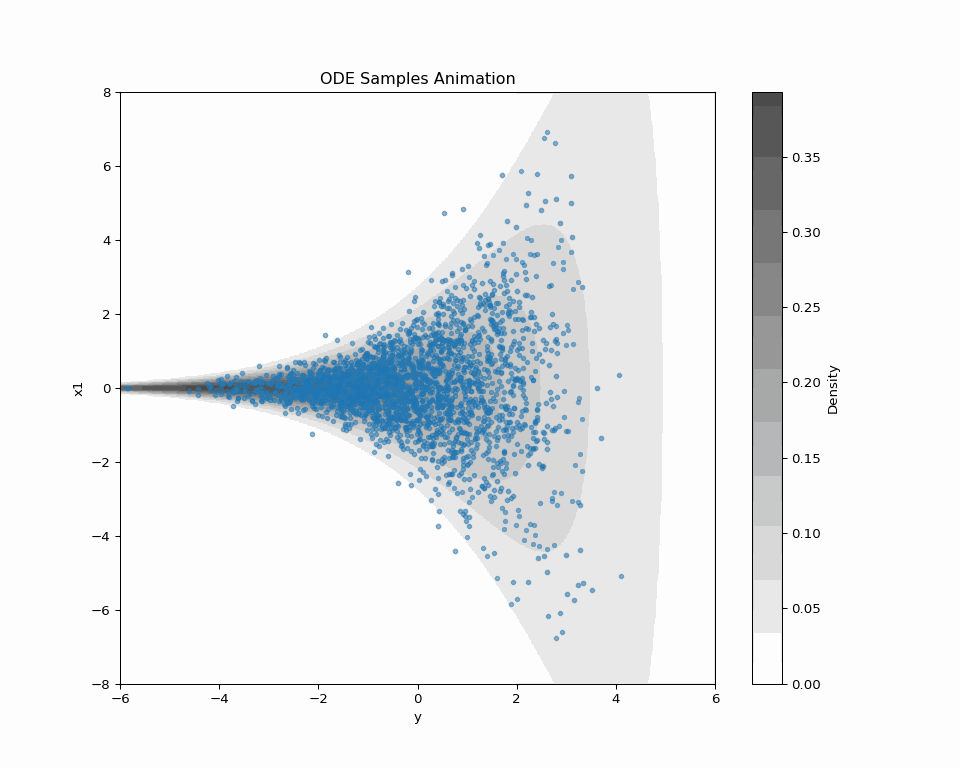
2.3 ODE Sampling of Score-based DDM
\text{ODE:}\qquad\frac{d\textcolor{#2780e3}{X}_t}{dt}=-b_t(\textcolor{#2780e3}{X_t})+\frac{1}{2}s_{\textcolor{#2780e3}{\theta}}^t(\textcolor{#2780e3}{X_t})=:v^t_\theta(\textcolor{#2780e3}{X_t}) \tag{1} has the same 1d marginal distributions as \text{\textcolor{#2780e3}{Denoising diffusion} SDE:}\quad d\textcolor{#2780e3}{X_t}=\bigg(-b_{t}(\textcolor{#2780e3}{X_t})+s_{\textcolor{#2780e3}{\theta}}^{t}(\textcolor{#2780e3}{X_t})\bigg)\,dt+dB_t.
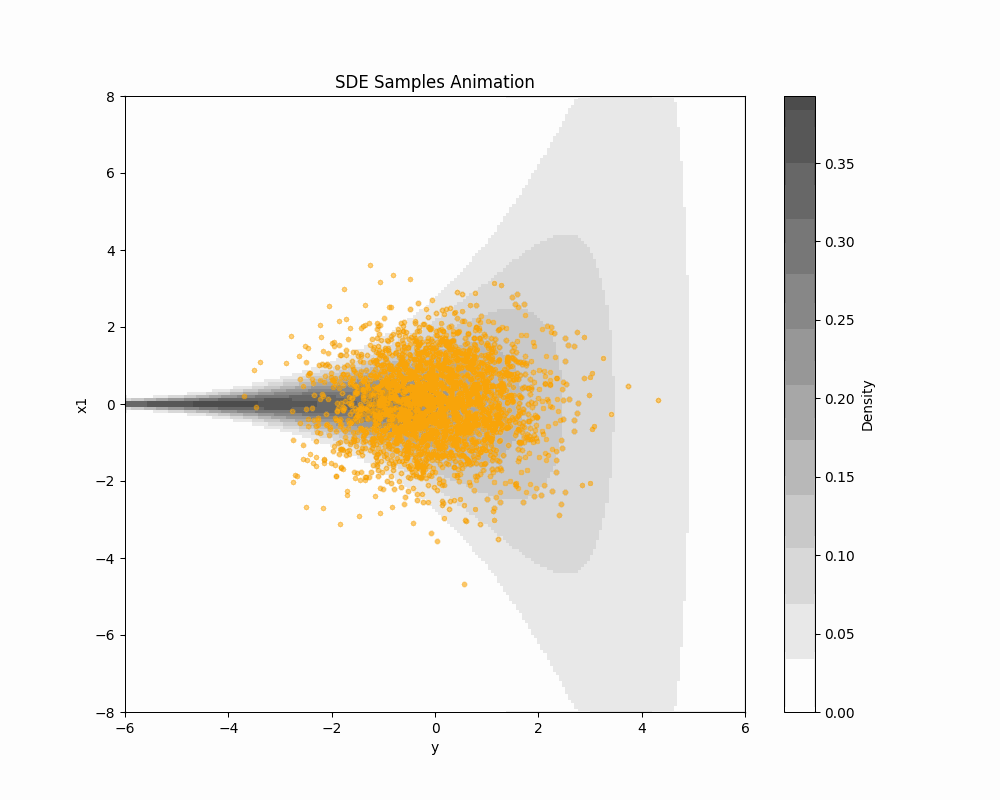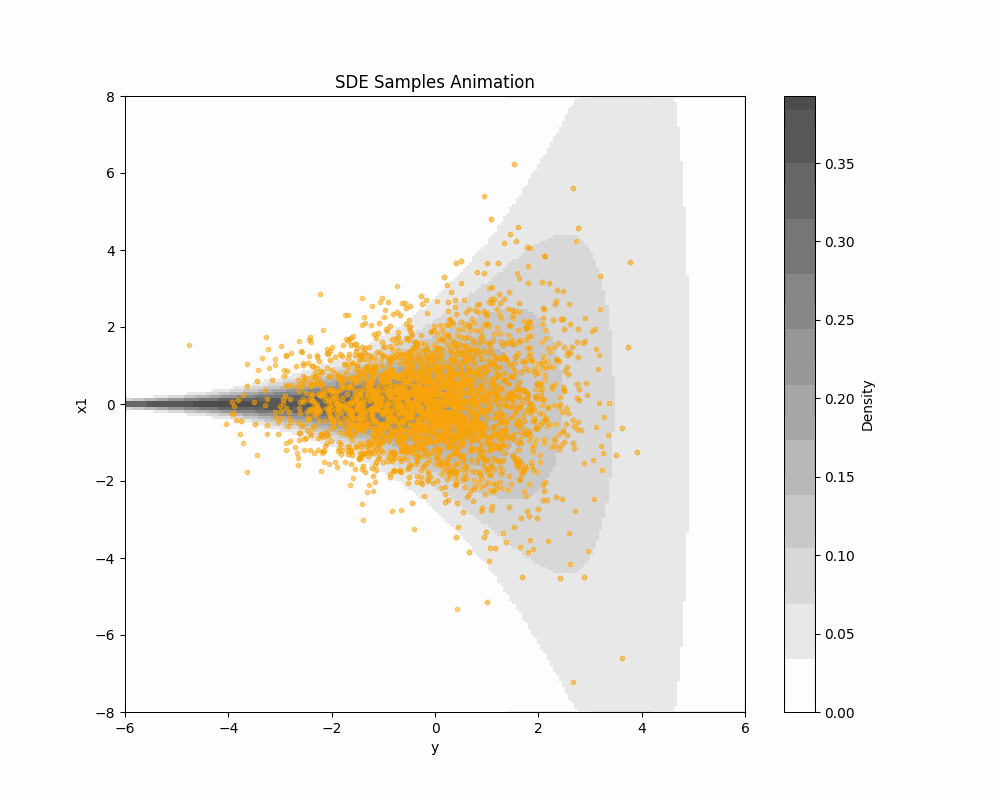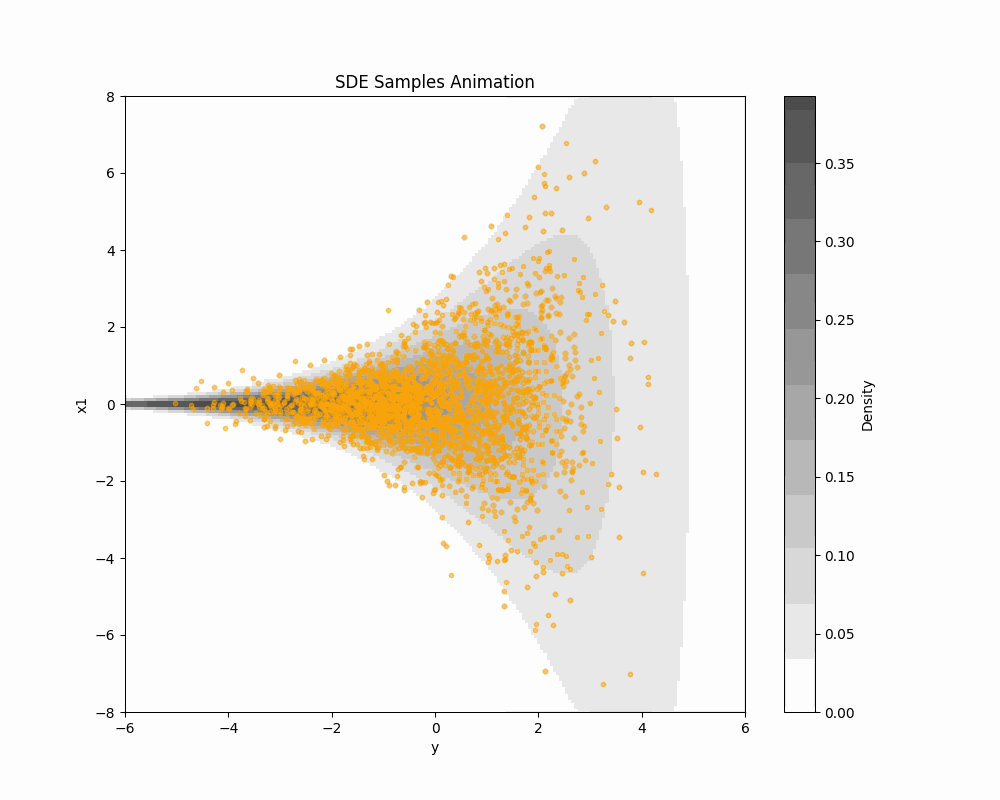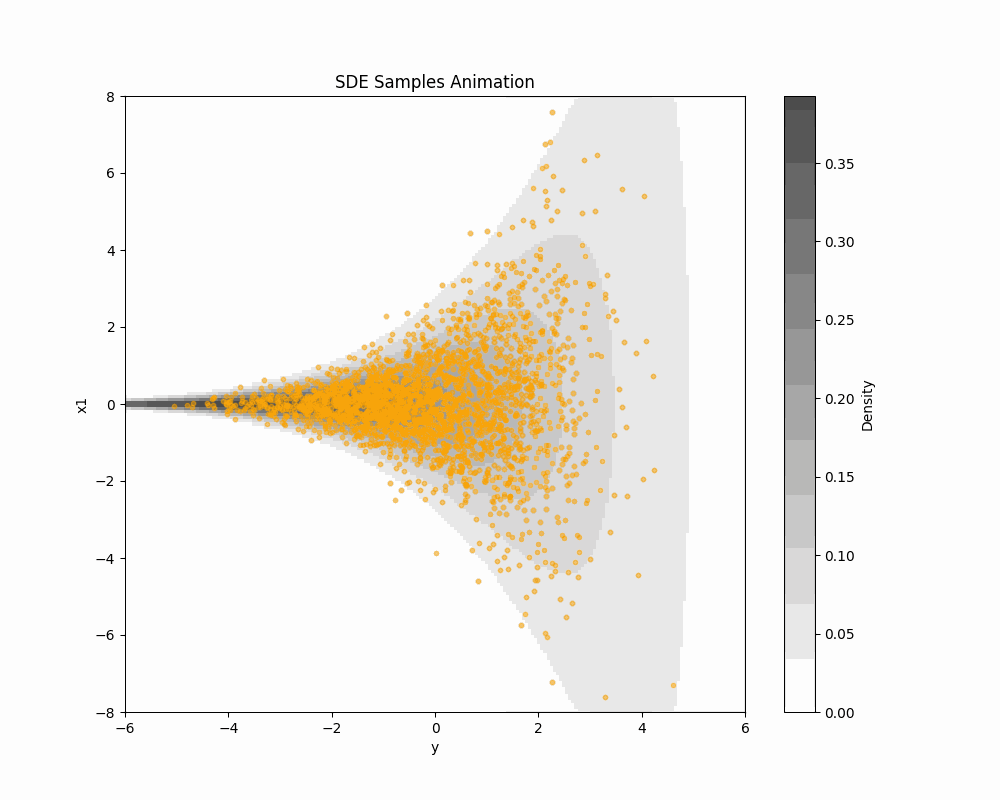
2.5 In Search of Better Forward Path
2.7 From Path to Flow
Diffusion Path
p_{\textcolor{#2780e3}{\theta}}^t(-|\textcolor{#2780e3}{x})=\operatorname{N}\bigg(\alpha_{1-t}\textcolor{#2780e3}{x},(1-\alpha_{1-t}^2)I_d\bigg) corresponds to u_t(\textcolor{#E95420}{z}|\textcolor{#2780e3}{x})=\frac{\alpha_{1-t}}{1-\alpha_{1-t}^2}(\alpha_{1-t}\textcolor{#E95420}{z}-\textcolor{#2780e3}{x})

Optimal Transport Path
p_{\textcolor{#2780e3}{\theta}}^t(-|\textcolor{#2780e3}{x})=\operatorname{N}\bigg(t\textcolor{#2780e3}{x},(1-t)I_d\bigg) corresponds to u_t(\textcolor{#E95420}{z}|\textcolor{#2780e3}{x})=\frac{\textcolor{#2780e3}{x}-\textcolor{#E95420}{z}}{1-t}
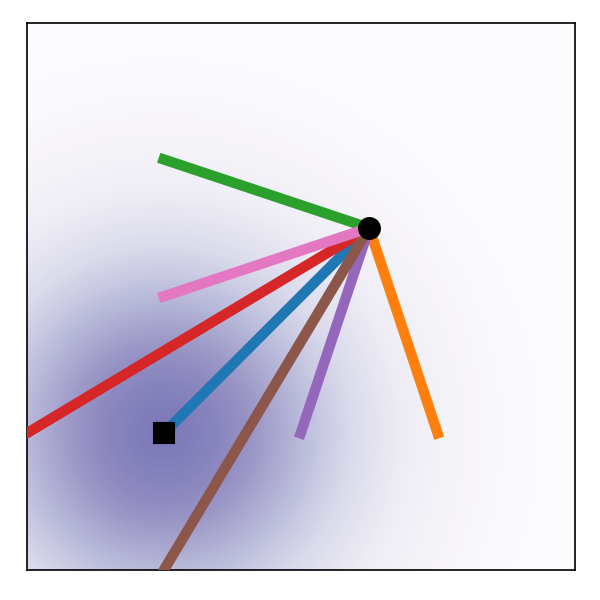
OT paths result in straight trajectries with constant speed, which is more suitable for stable generation.
Figures are from (Lipman et al., 2023).
Summary: Towards Straighter Paths
- SDE formulation enables faster ODE sampling
- ODE sampling is possible to other choices of q_{\textcolor{#E95420}{\phi}}
\because\quad Only 1d marginals matter (= Flow-based Modeling)- Langevin path ← the Diffusion Model
- Optimal Transport path
- more in discrete settings!
3 Discrete Diffusion Models

Block Diffusion proposed in (Arriola et al., 2025)
3.1 Masking Processes
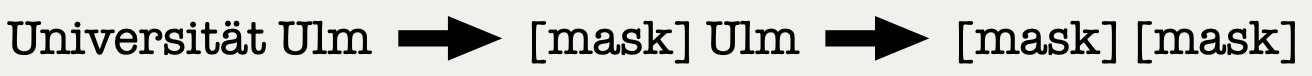
with some rate R_t(\texttt{mask}|x)>0 of masking x\ne\texttt{mask}.
The reverse process is characterized by the rate \textstyle\hat{R}_t(x|y)=R_t(y|x)\underbrace{\frac{q^t(x)}{q^t(y)}.}_{\text{learn this part using NN}}
| Forward process | Uniform | Masking |
|---|---|---|
| Number of steps needed in backward process | \tilde{O}(d^2/\epsilon) | \tilde{O}(d/\epsilon) |
Algorithmic Stability
The Score of DDM (Y. Song et al., 2021)




The Vector Field of FM (Lipman et al., 2023)




One hidden theme was algorithmic stability, which plays a crucial role in the successful methods.
