High-Dimensional Behaviour of Piecewise Deterministic Monte Carlo
Efficiency Comparison & Asymptotic Variance Estimation
6/16/2026
1 PDMPs: A New Frontier of Monte Carlo
(1953–)
(1978–)
(2008–)
A Blog Entry on Bayesian Computation by an Applied Mathematician
$$
$$
1.1 PDMP: Mathematical Definition

1.2 Markov Chain Monte Carlo
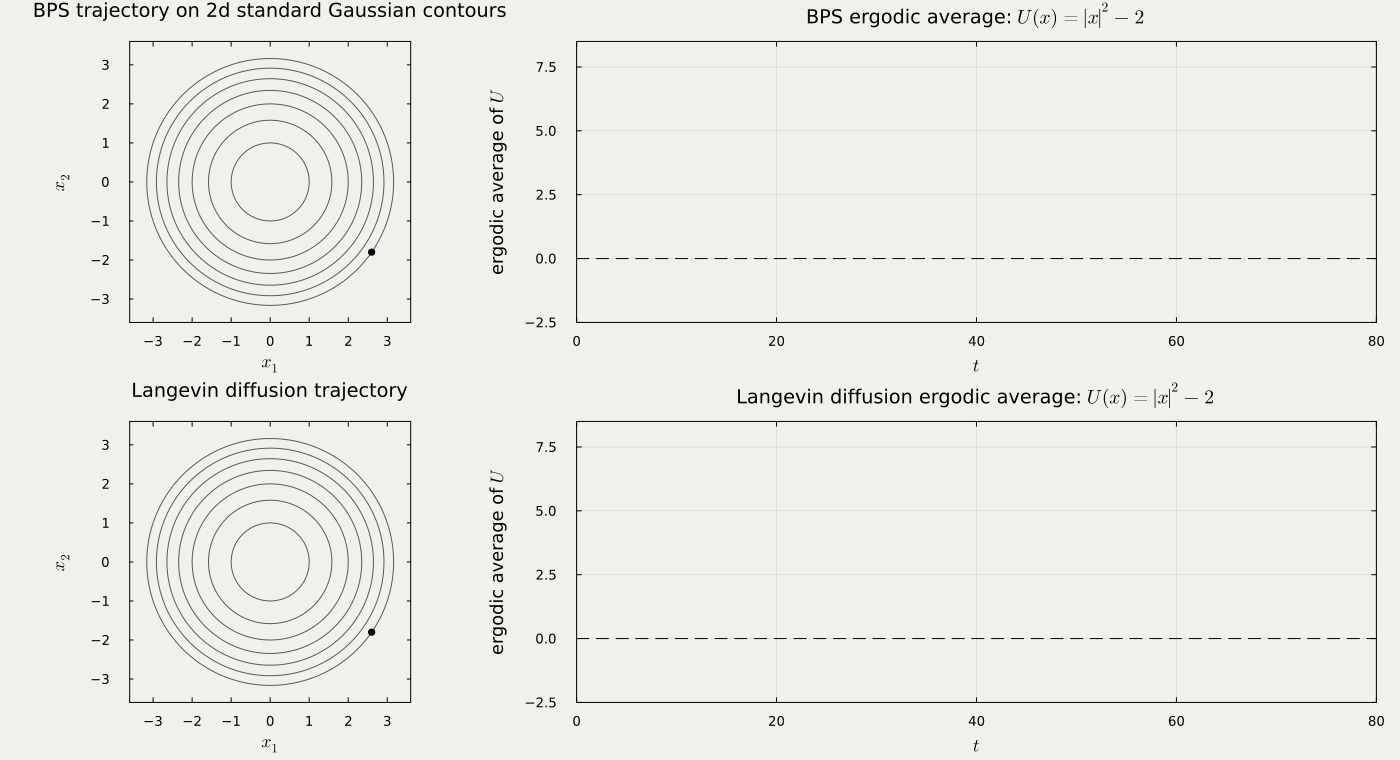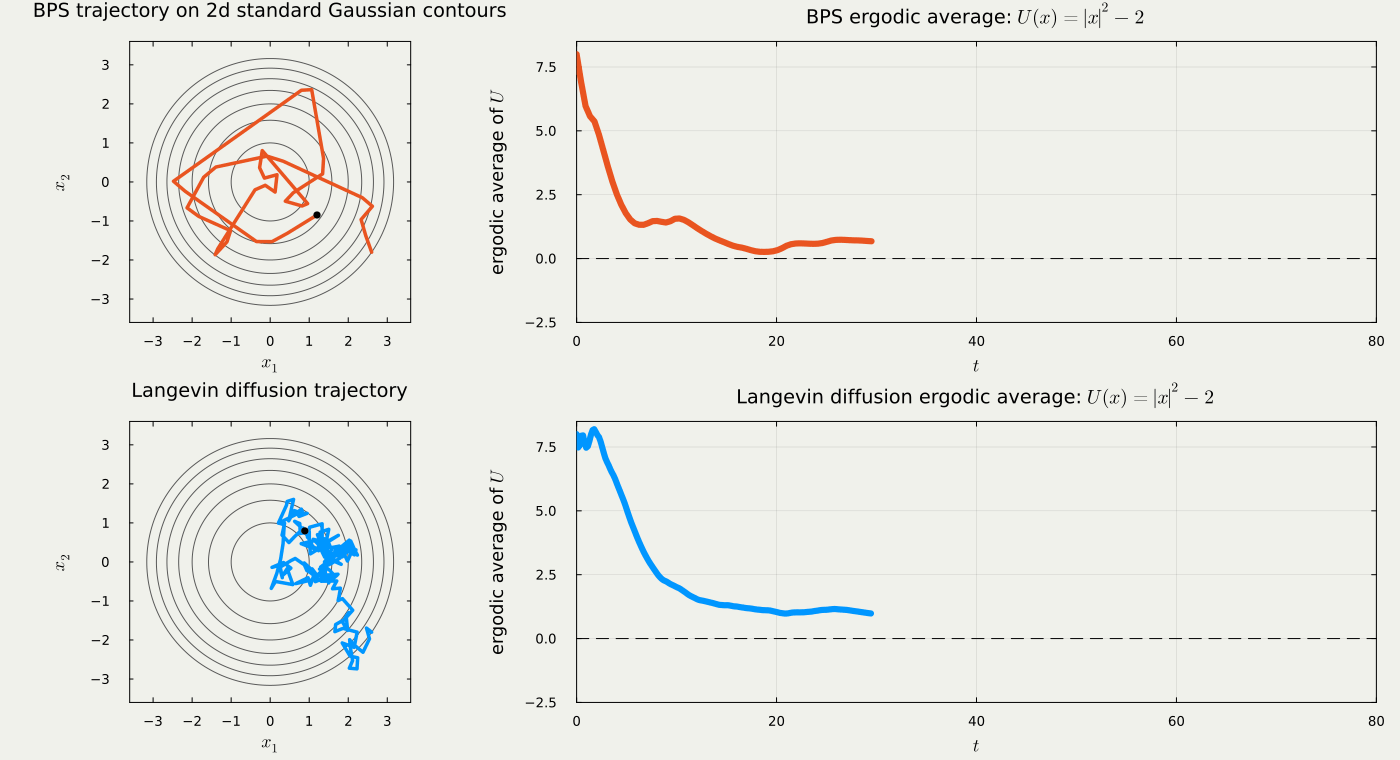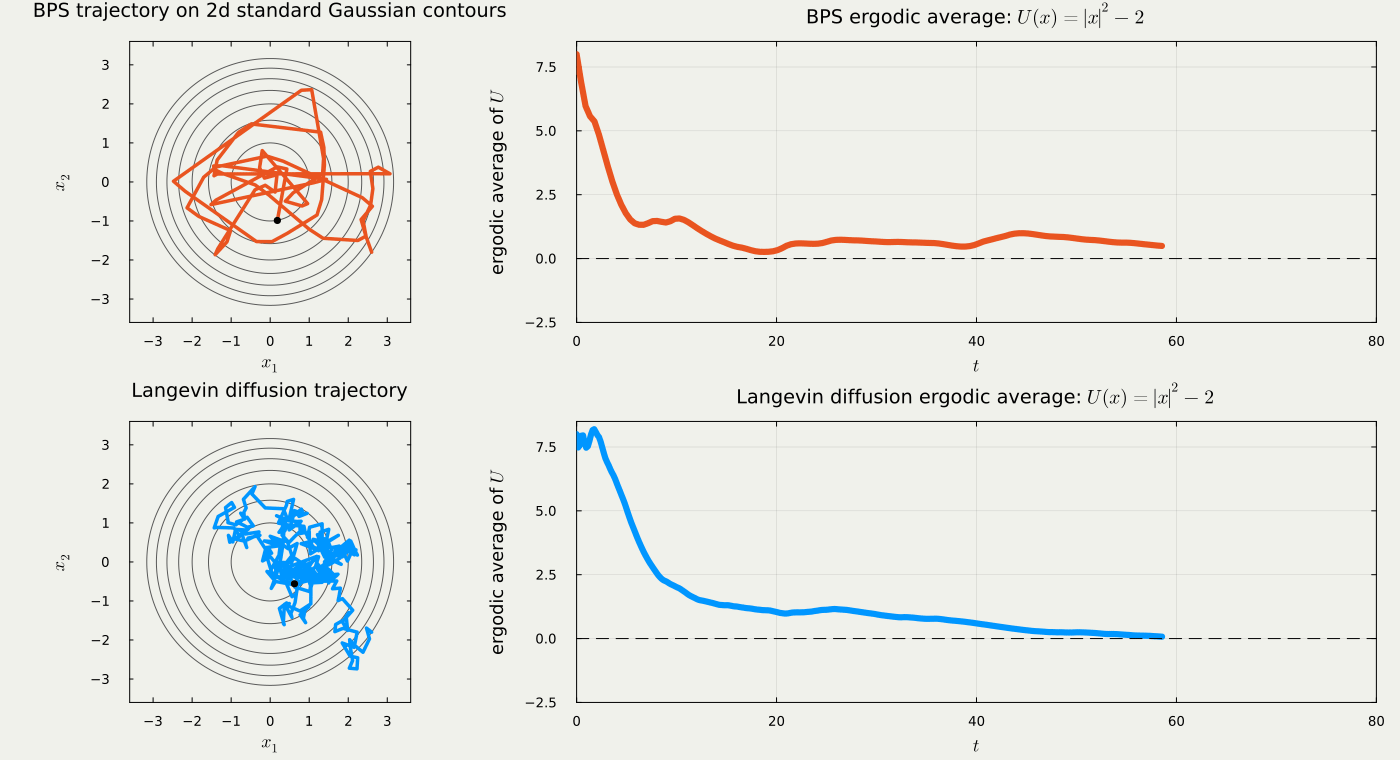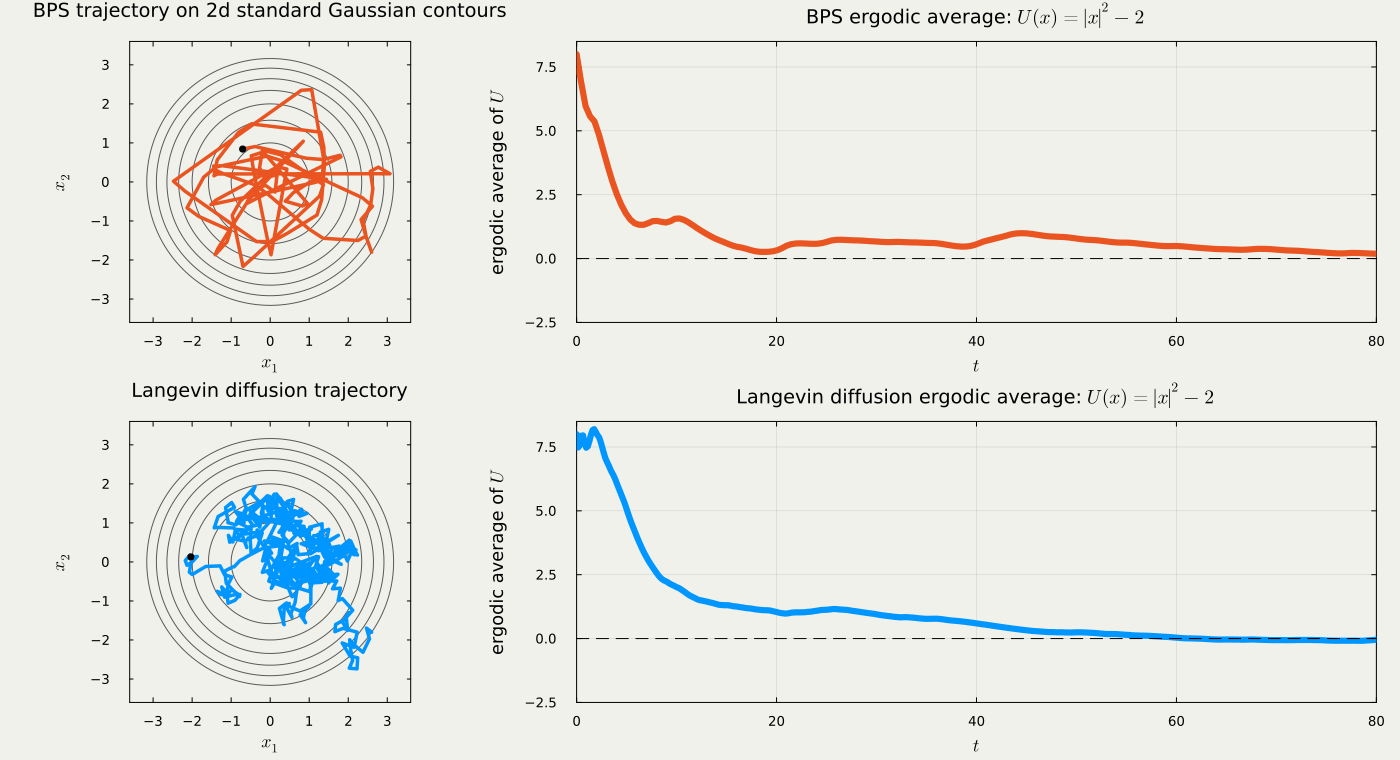
1.3 Classical Methods Turn Out to Be PDMPs in Disguise
Many PDMPs behave similarly in high dimensions.
discretized by a symplectic integrator
e.g. HMC has O(d^{1.25}) complexity

simulate piecewise linear trajectory
e.g. BPS with normal velocity has O(d^{1.5}) complexity
1.4 Digression: Killer Applications of PDMP
Sparse Markov Random Field with d=10
O(d^1) Local Implementation
Exploiting sparsity, BPS atteins better scaling than HMC (MSE/sec.)
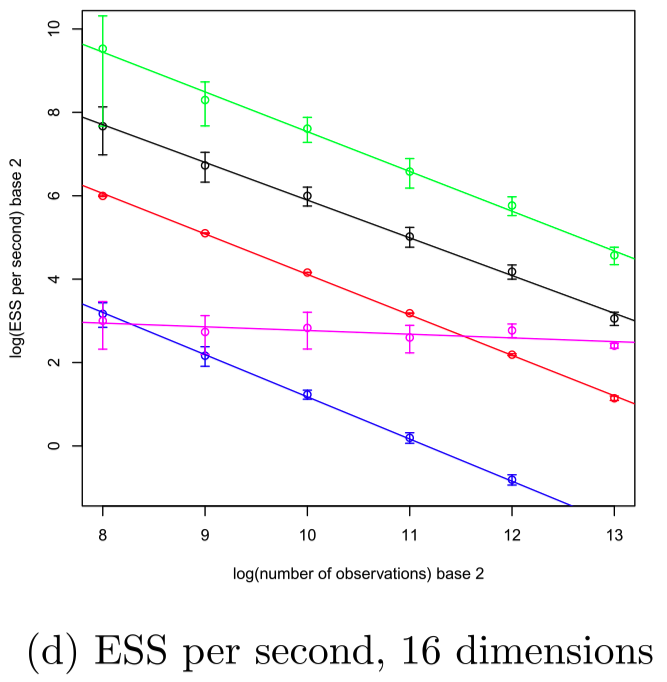
Stochastic Gradient O(n^0)
x: sample size n, y: log ESS
Logistic regression with d=16
Using an appropriate control variate, the efficiency of Zig-Zag is O(1)
in the limit of n\to\infty, it outperforms Langevin.
2 Towards Better Jump Strategy: A Scaling Analysis
We compare two famous PDMP methods under the following condition:
- ODE: Fixed
- Jump: Reflection + Refreshment vs. Combination
- Target: High dimensional standard Gaussian U(x):=-\log\pi(x)=\|x\|^2/2.

2.1 BPS vs. FECMC
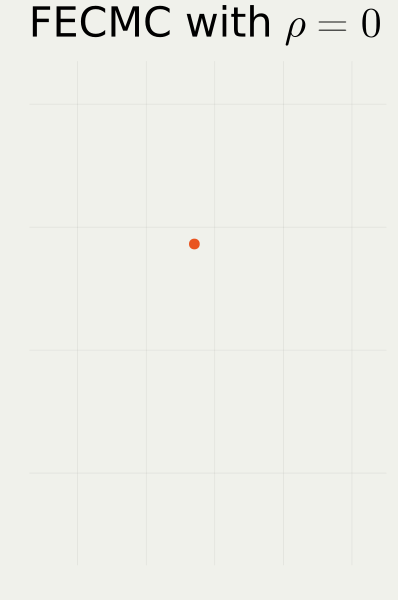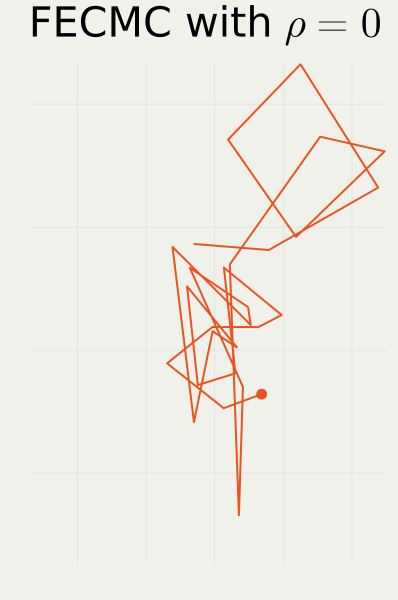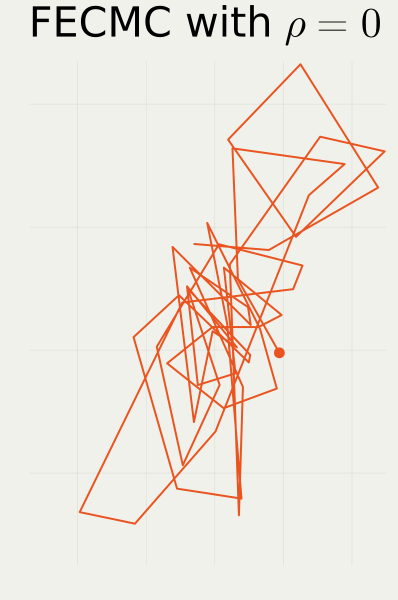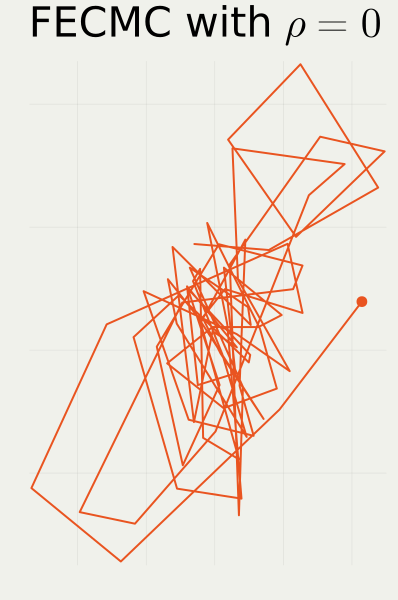
2.2 Jump Strategy in BPS vs. FECMC
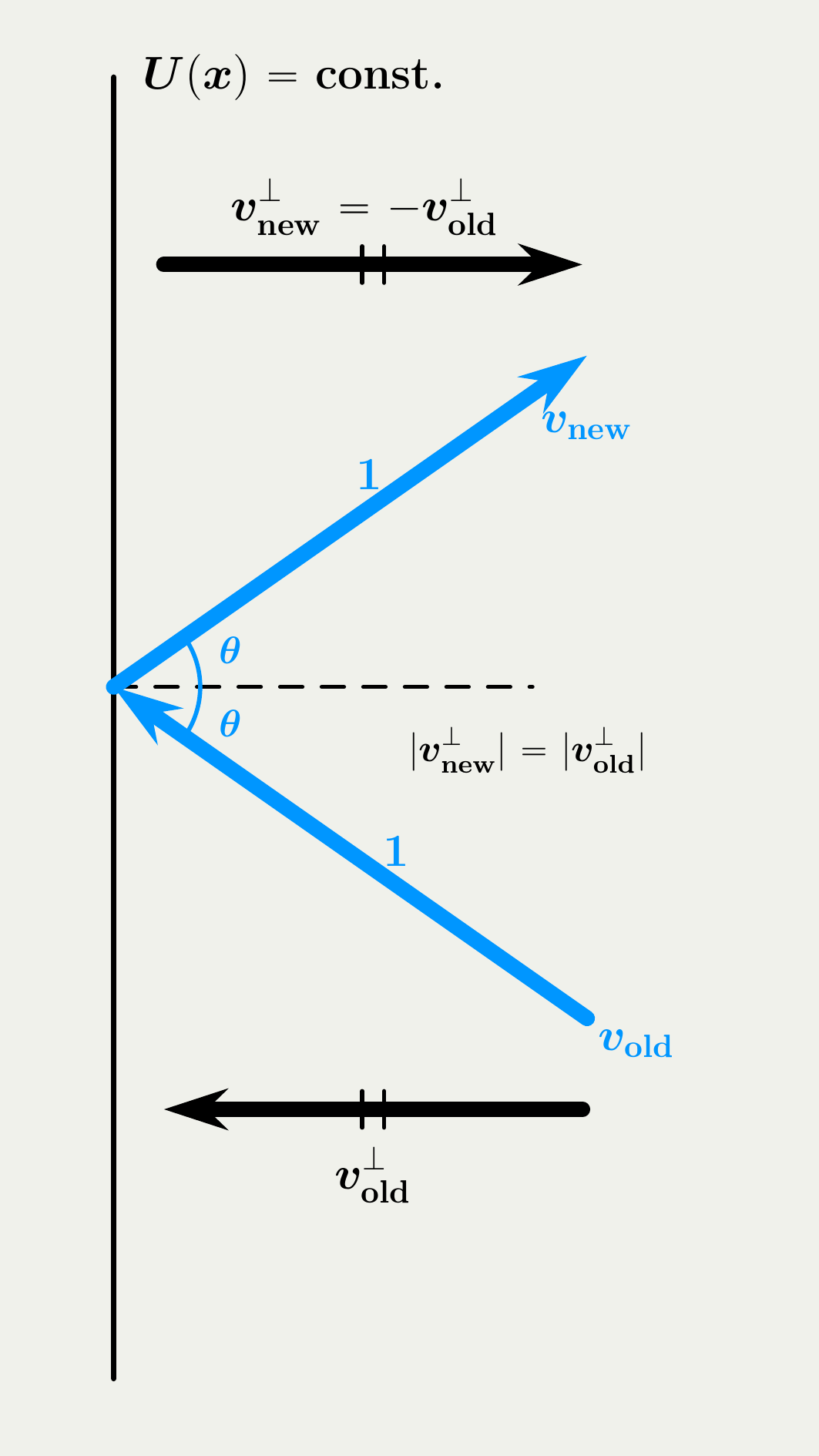
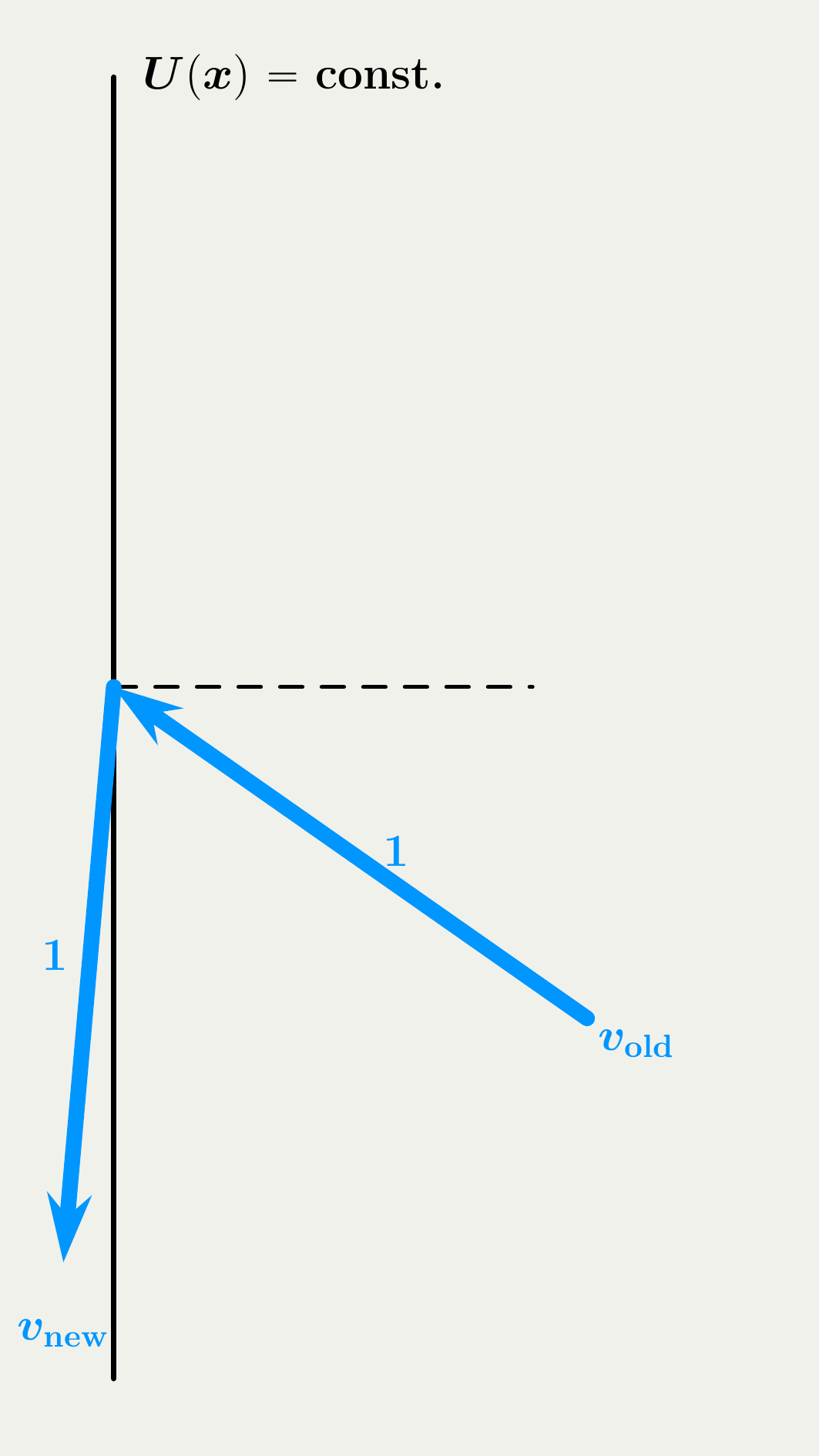
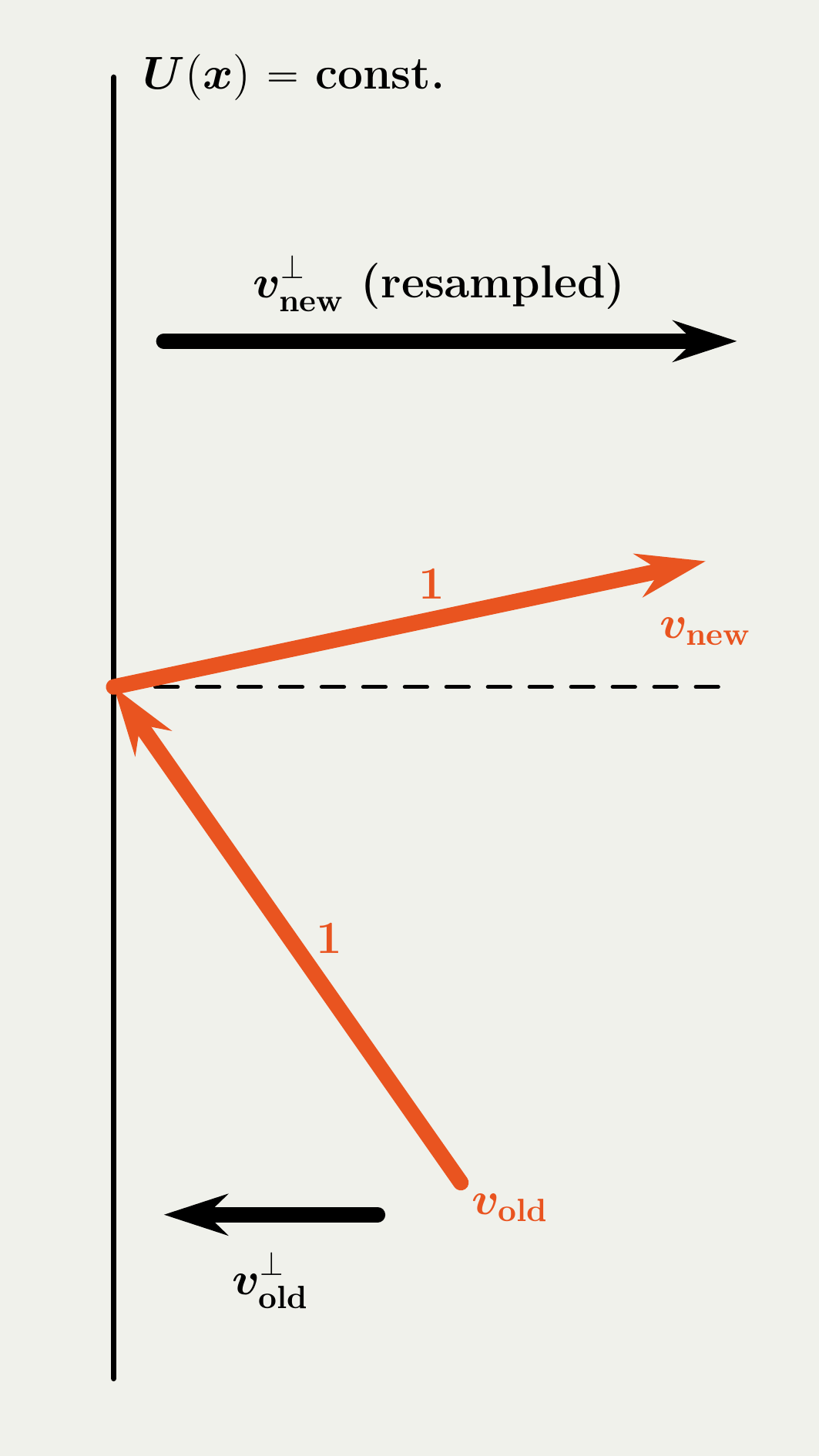
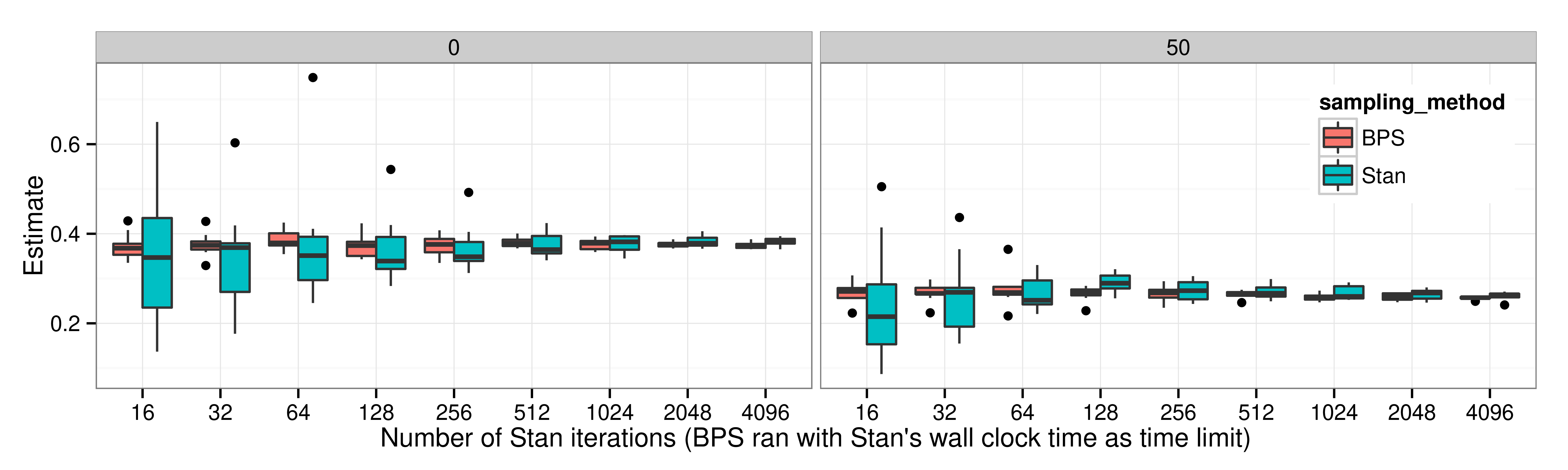
2.3 Empirical Comparison: BPS vs. FECMC

Effective Sample Size of U(x)=\|x\|^2, the negative log-density of 100 dimensional standard Gaussian, estimated over 1000 runs
2.4 Scaling Analysis = Deriving a Diffusion Limit
\text{Plotting } \textcolor{#0096FF}{Y_t^{(d)}}=\frac{\lvert\textcolor{#0096FF}{X}_{d\textcolor{#0096FF}{t}}^{\textcolor{#0096FF}{(d)}}\rvert^2-d}{\sqrt{d}} \text{ with } d=10^2,10^3,10^4:

2.5 Theorem 1: Diffusion Limits of FECMC & BPS

dY_t^{\textcolor{#0096FF}{\text{B}}}=-\frac{\sigma^2_{\textcolor{#0096FF}{\text{B}}}(\rho)}{4}Y_t^{\textcolor{#0096FF}{\text{B}}}\,dt+\sigma_{\textcolor{#0096FF}{\text{B}}}(\rho)\,dB_t \sigma^2_{\textcolor{#0096FF}{\text{B}}}(\rho)=8\int^\infty_0e^{-\rho s}\operatorname{E}[R_0^{\textcolor{#0096FF}{\text{B}}}R_s^{\textcolor{#0096FF}{\text{B}}}]\,ds

dY_t^{\textcolor{#E95420}{\text{F}}}=-\frac{\sigma^2_{\textcolor{#E95420}{\text{F}}}(\rho)}{4}Y_t^{\textcolor{#E95420}{\text{F}}}\,dt+\sigma_{\textcolor{#E95420}{\text{F}}}(\rho)\,dB_t \sigma^2_{\textcolor{#E95420}{\text{F}}}(\rho)=8\int^\infty_0e^{-\rho s}\operatorname{E}[R_0^{\textcolor{#E95420}{\text{F}}}R_s^{\textcolor{#E95420}{\text{F}}}]\,ds
2.6 Theorem 2: Analytic Expression of \sigma^2’s

While BPS atteins maximum at non-trivial value of \rho, FECMC achieves maximum at \rho=0
2.8 Asymptotic Equivalence to a Skeleton Process

Difficult to see how C_t=\sigma^2t emerges.
3.2 Theory Matches Practice: FECMC vs. BPS

ESS for U estimated over 1000 runs. Every bootstrap CI contains the theoretical limiting value {8}/{\sigma^2}.
3.3 Asymptotic Variance Estimation for MCMC

A practical issue: Does this trajectory suffice for mean estimation? → A solution: asymptotic variance estimation
\text{Markov Chain CLT: }\quad\frac{1}{\sqrt{N}}\sum_{n=1}^NX_n\Rightarrow N(0,\sigma^2_{\text{asym}})\quad(N\to\infty). For mini-batches b=1,\cdots,B with length m:=N/B, \operatorname*{{Batch\; Means\; Estimator:}}_{\text{(for mean estimation)}} \text{ }\quad\widehat{\sigma^2}_\text{asym}:=\frac{m}{B-1}\sum_{b=1}^B\left(\textcolor{#0096FF}{\overline{{X}}^{(b)}}-\textcolor{#0096FF}{\overline{{X}}}\right)^2, where \textcolor{#0096FF}{\overline{{X}}^{(b)}}=\frac{1}{m}\sum_{n=1}^m\textcolor{#0096FF}{X_{n+(b-1)m}} is the mean over the b-th batch.
3.4 Optimal Batch Size for Classical MCMC & PDMP

Due to the continuous-time nature, batch size selection becomes a nontrivial problem for PDMPs.
3.5 Diffusivity Estimation for High-dimensional PDMPs
= Quadratic Variation (QV) Estimation under Misspecification

Plot of Y_t^d:=(|\textcolor{#E95420}{X^d}_{d\textcolor{#E95420}{t}}|^2-d)/\sqrt{d} when d=10^4. The trajectory converges to dY_t=-\frac{\sigma^2}{4} Y_t\,dt+\sigma\,dB_t as d\to\infty
The Realized Volatility estimator (Barndorff-Nielsen and Shephard, 2002) \widehat{Q}^d:=\frac{1}{T}\sum_{n=1}^N\biggr(Y_{\Delta n}^d-Y_{\Delta(n-1)}^d\biggl)^2,\quad T=\Delta N, converges to \sigma^2 under the conditions \Delta\to0,\quad d\to\infty,\quad\Delta d\to\infty.
3.6 Experiment: QV Estimation Improves with Dimension

slow corresponds to the Batch Means estimator, fast corresponds to the Realized Variation estimator
3.6 Experiment: QV Estimation Improves with Dimension

slow corresponds to the Batch Means estimator, fast corresponds to the Realized Variation estimator
3.7 Batch Size Selection for the QV Estimator
\fallingdotseq selecting the sampling step size \Delta under Misspecification (Aït-Sahalia et al., 2011)

For too small / large \Delta, \widehat{Q}^{d}(\Delta)\approx0. The optimal choice seems to be \Delta=O(d^{1/2}).

