import numpy as npfrom numba import jit@jit(nopython=True)def inverse_cdf(su, W):"""Inverse CDF algorithm for a finite distribution. su: (M,) ndarray of sorted uniform variables W: (N,) ndarray of normalized weights""" j =0 s = W[0] M = su.shape[0] A = np.empty(M, dtype=np.int64)for n inrange(M):while su[n] > s: j +=1 s += W[j] A[n] = jreturn Adef systematic(W, M):"""Systematic resampling W: (N,) ndarray of normalized weights M : number of resampled points""" su = (random.rand(1) + np.arange(M)) / Mreturn inverse_cdf(su, W)
class Weights:"""A class to hold the N weights of the particles"""def__init__(self, lw=None):self.lw = lw # t=0で呼ばれた際はNoneであるif lw isnotNone:self.lw[np.isnan(self.lw)] =-np.inf # 欠損値処理 m =self.lw.max() w = np.exp(self.lw - m) # 大きすぎる値にならないように s = w.sum()self.W = w / s # 正規化荷重self.ESS =1.0/ np.sum(self.W **2)self.log_mean = m + np.log(s /self.N)@propertydef N(self):"""Number of particles"""return0ifself.lw isNoneelseself.lw.shape[0]def add(self, delta):"""Add increment weights delta to the log weights"""ifself.lw isNone:returnself.__class__(lw=delta)else:returnself.__class__(lw=self.lw + delta)
class Summaries:"""A class to hold the summaries of the SMC algorithm"""def__init__(self, cols):self._collectors = [cls() for cls in default_collector_cls]if cols isnotNone:self._collectors.extend(col() for col in cols)for col inself._collectors:setattr(self, col.summary_name, col.summary)def collect(self, smc):for col inself._collectors: col.collect(smc)
class ParticleHistory:"""History of the particles Full history that keeps all the particle systems based on lists. """def__init__(self, fk):self.X, self.A, self.wgts = [], [], []self.fk = fkdef save(self, smc):self.X.append(smc.X)self.A.append(smc.A)self.wgts.append(smc.wgts)
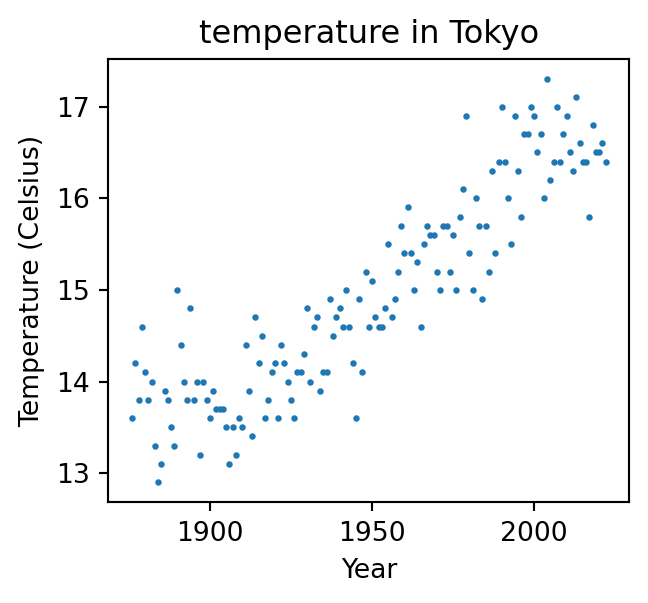
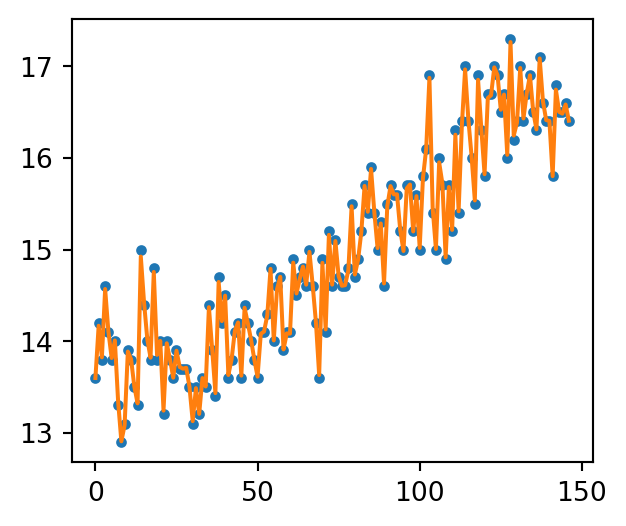
import matplotlib.pyplot as pltplt.figure(figsize=(3.5, 3))plt.title("temperature in Tokyo")plt.xlabel("Year")plt.ylabel("Temperature (Celsius)")plt.scatter(data['年度'], data['日平均'], s=2)plt.show()
from numpy import randomfrom scipy import statsclass Bootstrap:"""Abstract base class for Feynman-Kac models derived from State Space Model (1). """def__init__(self, data, T, R, Q):self.data = dataself.T = Tself.R = Rself.Q = Qdef M0(self, N):"""Sample N times from initial distribution M0 of the FK model"""return random.normal(loc=13.6, scale=self.Q, size=N)def M(self, t, xp): # xp: resampled previous state"""Sample Xt from kernel Mt conditioned on Xt-1=xp"""return random.normal(loc=xp, scale=self.Q, size=xp.shape[0])def logG(self, t, xp, x): # x: current state"""Evaluate the log potential Gt(xt-1,xt)"""return stats.norm.logpdf(self.data[t], loc=x, scale=self.R)def time_to_resample(self, smc):"""Return True if resampling is needed"""return smc.wgts.ESS < smc.N * smc.ESSrmindef done(self, smc):"""Return True if the algorithm is done"""return smc.t >=self.T
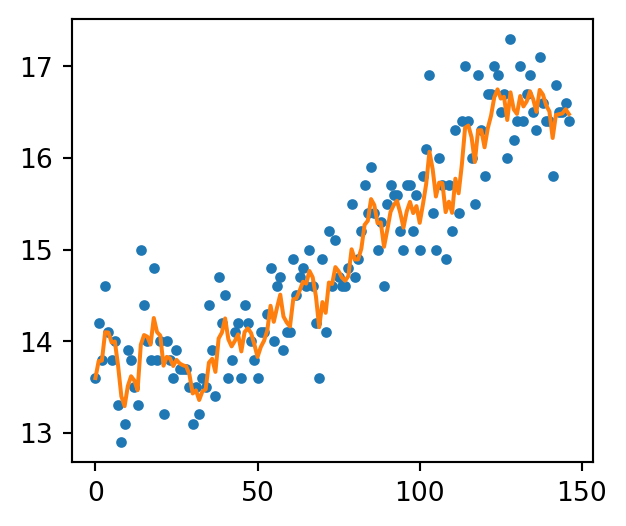
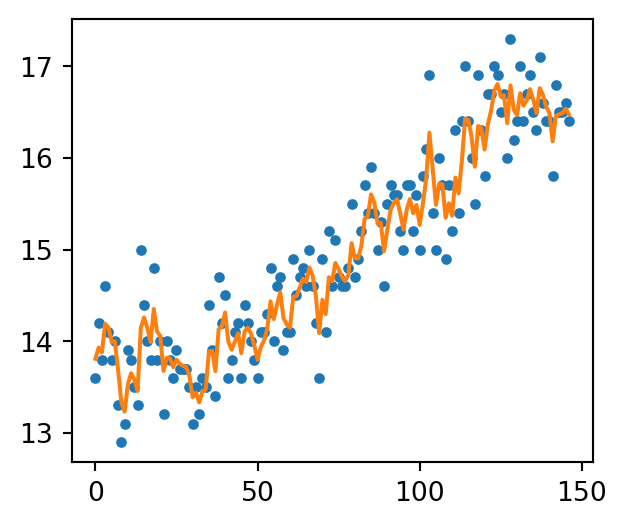
plt.figure(figsize=(3.5, 3))plt.plot(data['日平均'], label='data', linestyle='', marker='.')plt.plot([m['mean'] for m in PF1.summaries.Moments], label='filtered temperature trend')plt.show()
plt.figure(figsize=(3.5, 3))plt.plot(data['日平均'], label='data', linestyle='', marker='.')plt.plot([m['mean'] for m in PF4.summaries.Moments], label='filtered temperature trend')plt.show()
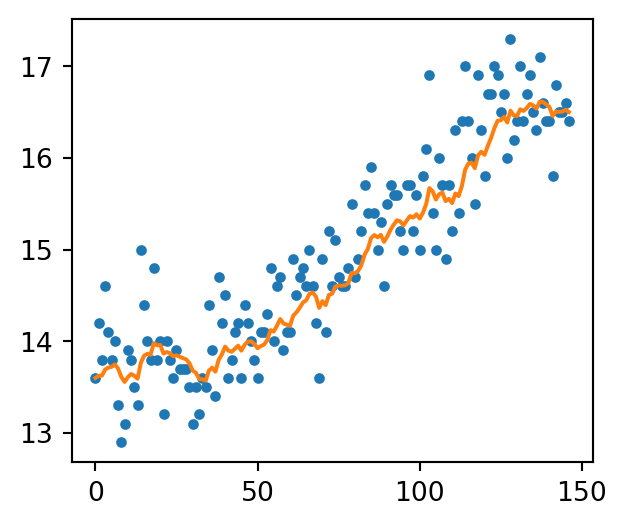
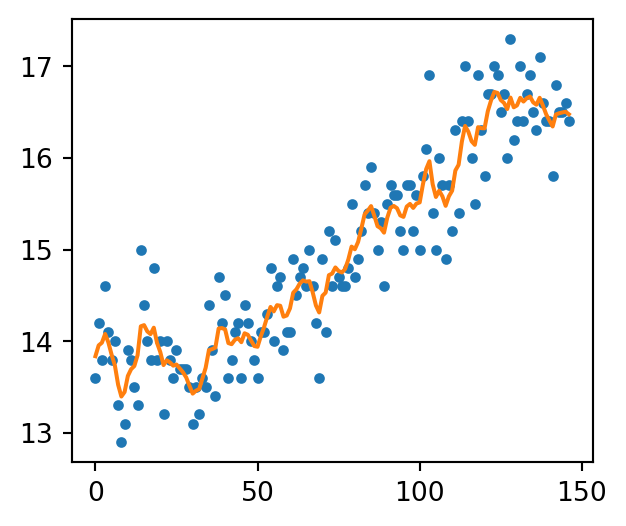
plt.figure(figsize=(3.5, 3))plt.plot(data['日平均'], label='data', linestyle='', marker='.')plt.plot([m['mean'] for m in PF2.summaries.Moments], label='filtered temperature trend')plt.show()
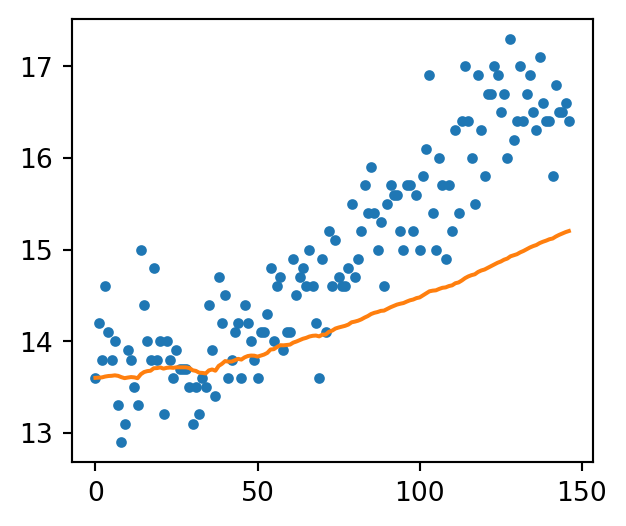
plt.figure(figsize=(3.5, 3))plt.plot(data['日平均'], label='data', linestyle='', marker='.')plt.plot([m['mean'] for m in PF3.summaries.Moments], label='filtered temperature trend')plt.show()