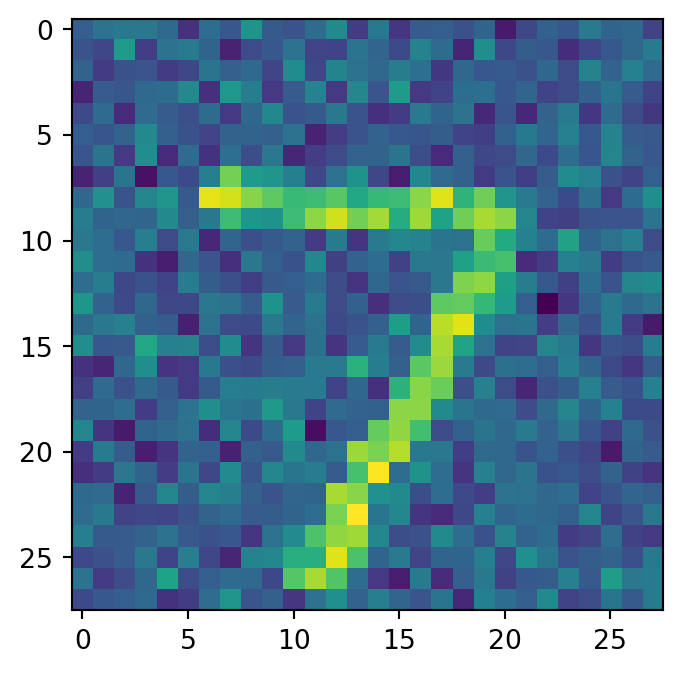
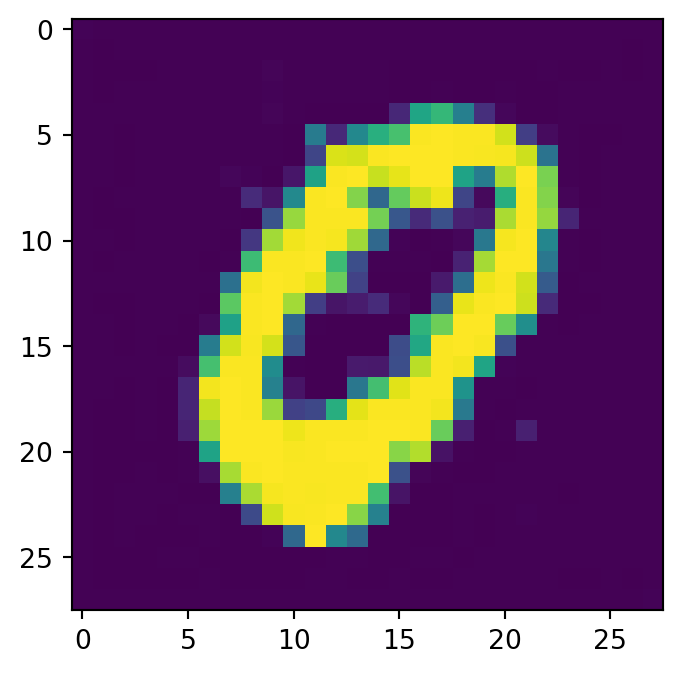
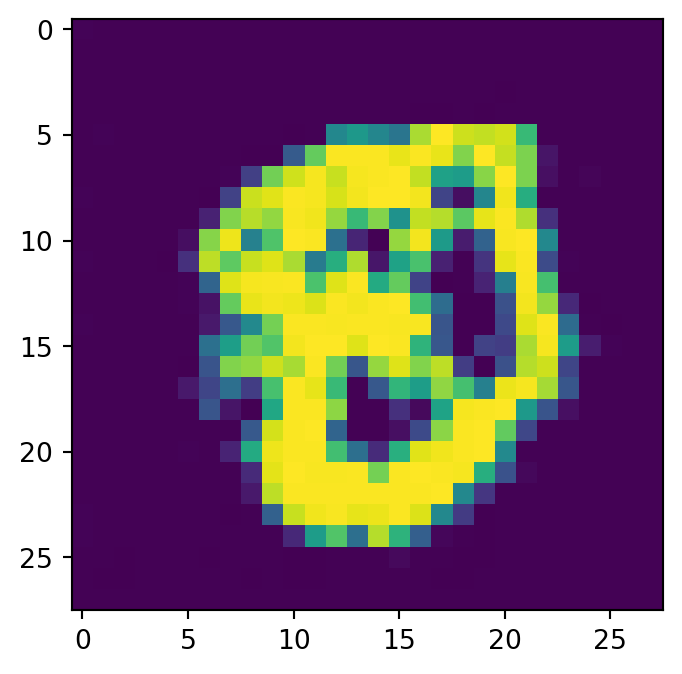
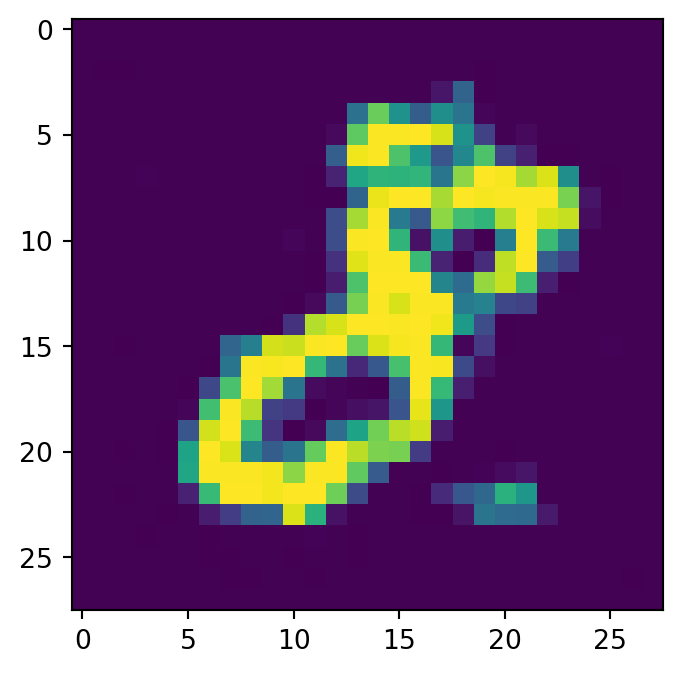
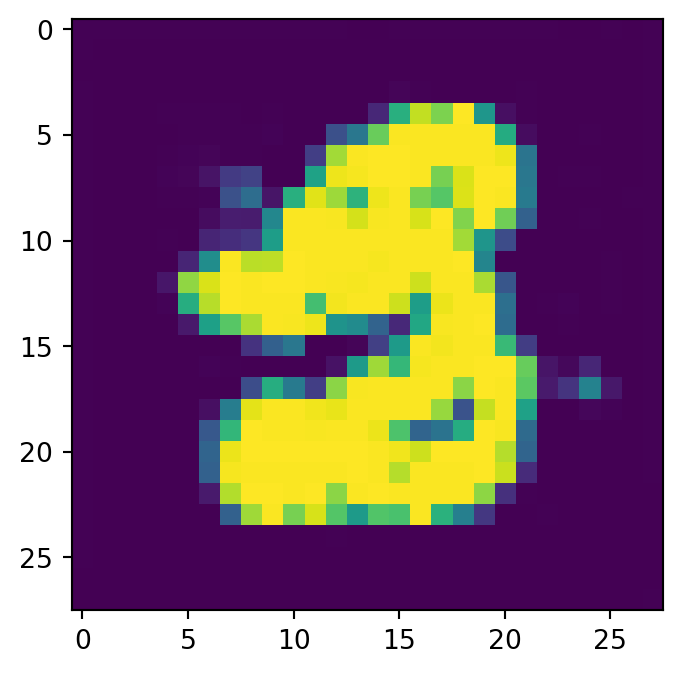
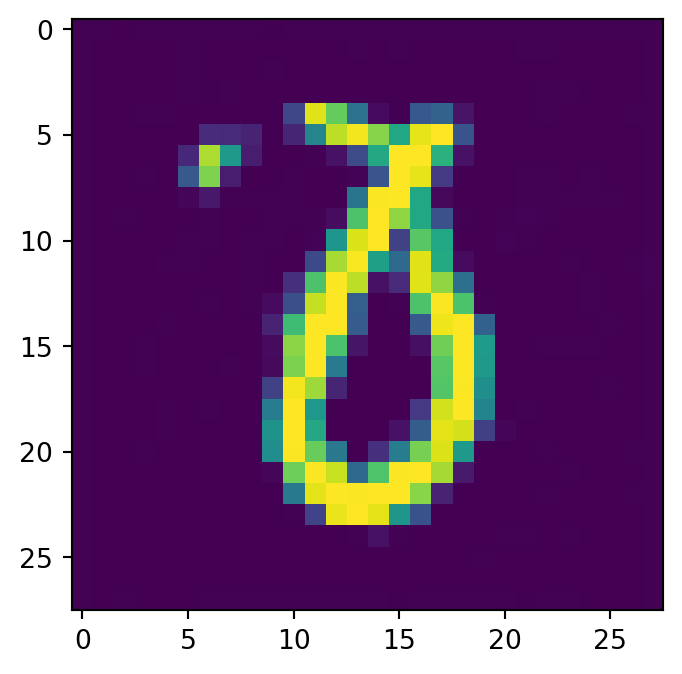
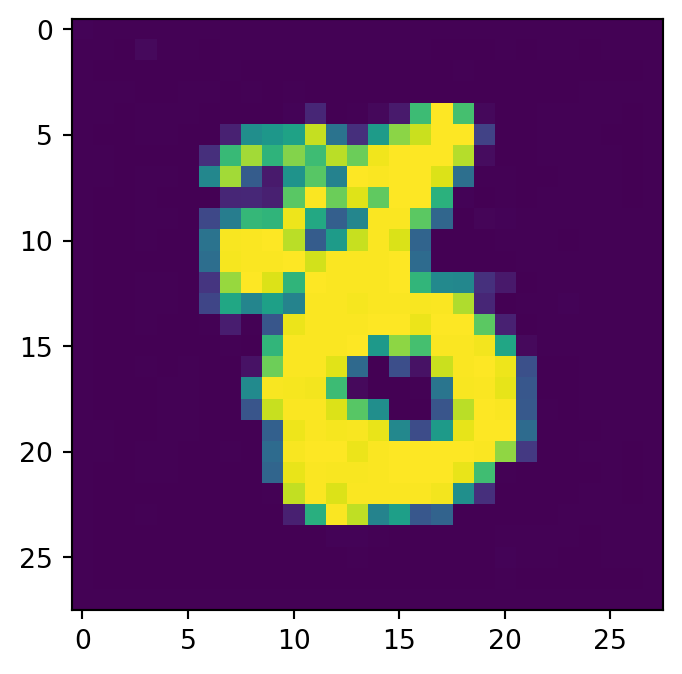
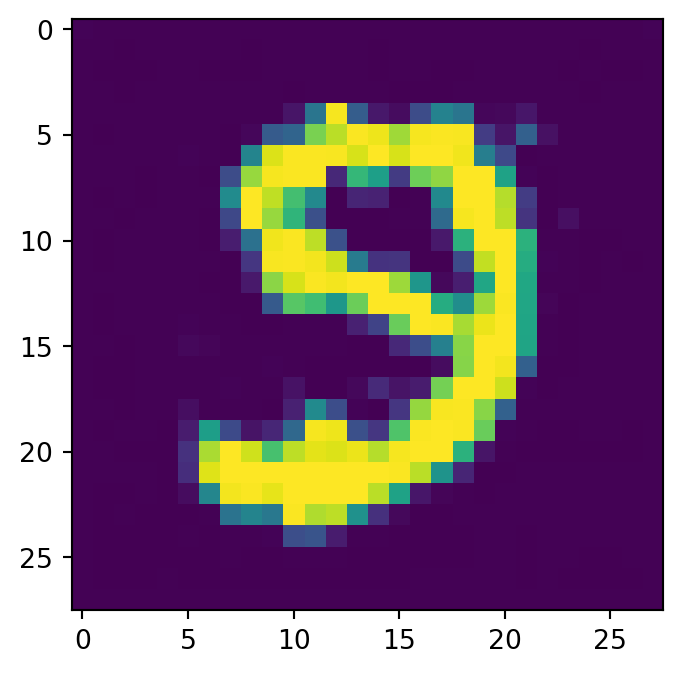
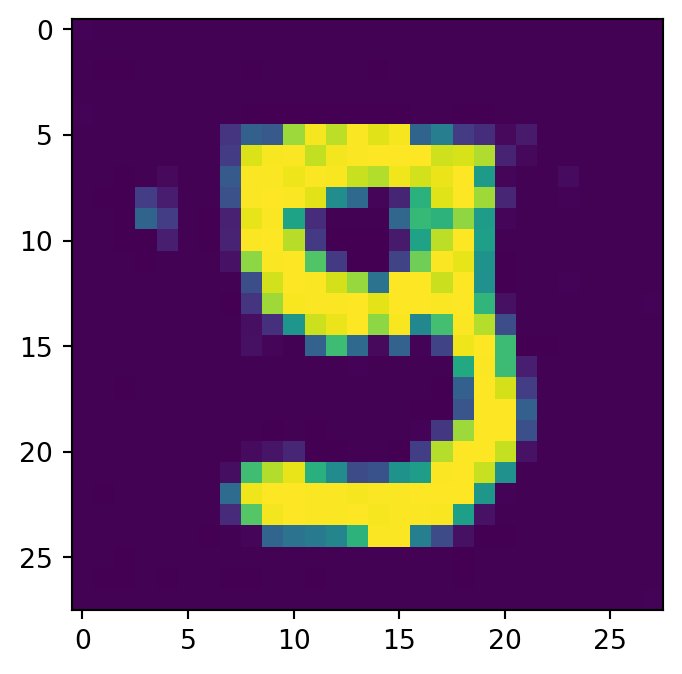
class Diffusion(nn.Module):
def __init__(self, model, image_resolution=[32, 32, 3], n_times=1000, beta_minmax=[1e-4, 2e-2], device='cuda'):
super(Diffusion, self).__init__()
self.n_times = n_times
self.img_H, self.img_W, self.img_C = image_resolution
self.model = model
# define linear variance schedule(betas)
beta_1, beta_T = beta_minmax
betas = torch.linspace(start=beta_1, end=beta_T, steps=n_times).to(device) # follows DDPM paper
self.sqrt_betas = torch.sqrt(betas)
# define alpha for forward diffusion kernel
self.alphas = 1 - betas
self.sqrt_alphas = torch.sqrt(self.alphas)
alpha_bars = torch.cumprod(self.alphas, dim=0)
self.sqrt_one_minus_alpha_bars = torch.sqrt(1-alpha_bars)
self.sqrt_alpha_bars = torch.sqrt(alpha_bars)
self.device = device
def extract(self, a, t, x_shape):
"""
from lucidrains' implementation
https://github.com/lucidrains/denoising-diffusion-pytorch/blob/beb2f2d8dd9b4f2bd5be4719f37082fe061ee450/denoising_diffusion_pytorch/denoising_diffusion_pytorch.py#L376
"""
b, *_ = t.shape
out = a.gather(-1, t)
return out.reshape(b, *((1,) * (len(x_shape) - 1)))
def scale_to_minus_one_to_one(self, x):
# according to the DDPMs paper, normalization seems to be crucial to train reverse process network
return x * 2 - 1
def reverse_scale_to_zero_to_one(self, x):
return (x + 1) * 0.5
def make_noisy(self, x_zeros, t):
# perturb x_0 into x_t (i.e., take x_0 samples into forward diffusion kernels)
epsilon = torch.randn_like(x_zeros).to(self.device)
sqrt_alpha_bar = self.extract(self.sqrt_alpha_bars, t, x_zeros.shape)
sqrt_one_minus_alpha_bar = self.extract(self.sqrt_one_minus_alpha_bars, t, x_zeros.shape)
# Let's make noisy sample!: i.e., Forward process with fixed variance schedule
# i.e., sqrt(alpha_bar_t) * x_zero + sqrt(1-alpha_bar_t) * epsilon
noisy_sample = x_zeros * sqrt_alpha_bar + epsilon * sqrt_one_minus_alpha_bar
return noisy_sample.detach(), epsilon
def forward(self, x_zeros):
x_zeros = self.scale_to_minus_one_to_one(x_zeros)
B, _, _, _ = x_zeros.shape
# (1) randomly choose diffusion time-step
t = torch.randint(low=0, high=self.n_times, size=(B,)).long().to(self.device)
# (2) forward diffusion process: perturb x_zeros with fixed variance schedule
perturbed_images, epsilon = self.make_noisy(x_zeros, t)
# (3) predict epsilon(noise) given perturbed data at diffusion-timestep t.
pred_epsilon = self.model(perturbed_images, t)
return perturbed_images, epsilon, pred_epsilon
def denoise_at_t(self, x_t, timestep, t):
B, _, _, _ = x_t.shape
if t > 1:
z = torch.randn_like(x_t).to(self.device)
else:
z = torch.zeros_like(x_t).to(self.device)
# at inference, we use predicted noise(epsilon) to restore perturbed data sample.
epsilon_pred = self.model(x_t, timestep)
alpha = self.extract(self.alphas, timestep, x_t.shape)
sqrt_alpha = self.extract(self.sqrt_alphas, timestep, x_t.shape)
sqrt_one_minus_alpha_bar = self.extract(self.sqrt_one_minus_alpha_bars, timestep, x_t.shape)
sqrt_beta = self.extract(self.sqrt_betas, timestep, x_t.shape)
# denoise at time t, utilizing predicted noise
x_t_minus_1 = 1 / sqrt_alpha * (x_t - (1-alpha)/sqrt_one_minus_alpha_bar*epsilon_pred) + sqrt_beta*z
return x_t_minus_1.clamp(-1., 1)
def sample(self, N):
# start from random noise vector, x_0 (for simplicity, x_T declared as x_t instead of x_T)
x_t = torch.randn((N, self.img_C, self.img_H, self.img_W)).to(self.device)
# autoregressively denoise from x_T to x_0
# i.e., generate image from noise, x_T
for t in range(self.n_times-1, -1, -1):
timestep = torch.tensor([t]).repeat_interleave(N, dim=0).long().to(self.device)
x_t = self.denoise_at_t(x_t, timestep, t)
# denormalize x_0 into 0 ~ 1 ranged values.
x_0 = self.reverse_scale_to_zero_to_one(x_t)
return x_0
diffusion = Diffusion(model, image_resolution=img_size, n_times=n_timesteps,
beta_minmax=beta_minmax, device=DEVICE).to(DEVICE)
optimizer = Adam(diffusion.parameters(), lr=lr)
denoising_loss = nn.MSELoss()