理論パート (Section 3)
ランダム行列の経験スペクトル分布の極限に対するスケーリング解析
ランダム行列のスペクトル分布解析への帰着 (3.3 )
ランダム行列の Stieltjes Transform Method (3.4 )
主定理 :平均レゾルベントの満たす自己無撞着方程式 (3.6 )主補題 :Gaussian Equivalence Principle (3.7 )証明方針2つ:Replica Method v. Free Probability (3.8 )
主な系 :Two-Bulk 構造 (3.9 )結論・ダイナミクスへの示唆:Separation of Timescales (3.10 )
設定
データ : \mathbb{R}^d\ni x^\nu\overset{\text{i.i.d.}}{\sim}P_x\;(\nu=1,\cdots,n) . あとで d\to\infty の極限を考える.スコア学習に使うNN :Random Feature W\in\mathbb{R}^{p\times d} with i.i.d. Gaussian
s_A(x):=\frac{A}{\sqrt{p}}\sigma^{\otimes p}\left(\frac{Wx}{\sqrt{d}}\right)\qquad A\in\mathbb{R}^{d\times p},
損失関数 : 固定した時刻 t>0 での DSM loss
\mathcal{L}_t(A;\{x^\nu\}_{\nu=1}^n):=\frac{1}{dn}\sum_{\nu=1}^n\operatorname{E}\left[\|\sqrt{\Delta_t} s_A(x_t^\nu(\xi))+\xi\|^2\right].
訓練 : GD の連続時間極限
\dot{A}_\tau=-d^2\nabla_A\mathcal{L}_t(A_\tau)=-2\Delta_t\frac{d}{p}AU_\tau-\frac{2d\sqrt{\Delta_t}}{\sqrt{p}}V_\tau^\top,\qquad\tau\ge0.
GD の連続時間極限
DSM loss での勾配降下法:
A^{(k+1)}\gets A^{(k)}-\eta\nabla_A\mathcal{L}_t(A^{(k)}),\qquad k=0,1,2,\cdots
\mathcal{L}_t(A)=\frac{1}{d}\left(\frac{\Delta_t}{p}\operatorname{Tr}(A^\top AU)+\frac{2\sqrt{\Delta_t}}{\sqrt{p}}\operatorname{Tr}(AV)+d\right)
時間変換 \tau(k):=k\eta/d^2 を施して,\eta\to0 の極限を取ると
\dot{A}_\tau=-d^2\nabla_A\mathcal{L}_t(A_\tau)=-2\Delta_t\frac{d}{p}A_\tau U-\frac{2d\sqrt{\Delta_t}}{\sqrt{p}}V^\top,\qquad\tau\ge0,
%:=\frac{1}{n}\sum_{\nu=1}^n\E[y^\nu (y^\nu)^\top]
U:=\frac{1}{n}\sum_{\nu=1}^n\operatorname{E}_\xi\left[\sigma^{\otimes p}\left(\frac{Wx^\nu_t(\xi)}{\sqrt{d}}\right)\sigma^{\otimes p}\left(\frac{Wx^\nu_t(\xi)}{\sqrt{d}}\right)^\top\right],
V:=\frac{1}{n}\sum_{\nu=1}^n\operatorname{E}_\xi\left[\sigma^{\otimes p}\left(\frac{Wx^\nu_t(\xi)}{\sqrt{d}}\right)\xi^\top\right].
U のスペクトルの分布への帰着
訓練ダイナミクス (A_\tau)_{\tau\ge0} のスケール分離は,U のスペクトルの分布のスケール分離からくる. 特に,典型的な緩和時間は \Delta_tU/\psi_p の固有値の逆数が与える.
\dot{\textcolor{#E95420}{A}}_{\textcolor{#E95420}{\tau}}=-d^2\nabla_A\mathcal{L}_t(\textcolor{#E95420}{A_\tau})=-2\Delta_t\frac{d}{p}\textcolor{#E95420}{A_\tau} U-\frac{2d\sqrt{\Delta_t}}{\sqrt{p}}V^\top,\qquad\tau\ge0,
は行列 A\in\mathbb{R}^{d\times p} に関する線型 ODE.U\in\mathrm{GL}_p(\mathbb{R}) なら Duhamel の公式から
\frac{\textcolor{#E95420}{A_\tau}}{\sqrt{p}}=-\frac{1}{\sqrt{\Delta_t}}V^\top U^{-1}+\left(\frac{1}{\sqrt{\Delta_t}}V^\top U^{-1}+\frac{A_0}{\sqrt{p}}\right)\exp\left(-\frac{2\Delta_t}{\psi_p}U\textcolor{#E95420}{\tau}\right),
\psi_p:=\frac{p}{d},\qquad\psi_n:=\frac{n}{d}.
Stieltjes Transform Method (1/2)
U の経験スペクトル分布 \mu_U の Stieltjes transform は,resolvent R(z):=(U-zI_p)^{-1} の平均固有値が与える:
q(z):=\frac{\operatorname{Tr}(R(z))}{p}=\frac{1}{p}\sum_{i=1}^pR(z)_{ii}=\int_{-\infty}^\infty\frac{1}{\lambda-z}\mu_U(d\lambda)\quad(z\in\mathbb{C}\setminus\mathbb{R}).
U を Hilbert 空間 H 上の正規作用素とする.このとき,ただ一つのスペクトル測度 E:\mathrm{Sp}(U)\to B(H) が存在して,
U=\int_{\mathrm{Sp}(U)} \lambda E(d\lambda).
主定理:平均レゾルベント q(z) の極限の特徴付け
q を記述するための補助的な量(R(z) と W,\Sigma^{-1}W との overlap)を導入:
\scriptstyle
r(z):=\frac{1}{p}\operatorname{Tr}(\Sigma^{1/2}W^\top(U-zI_p)^{-1}W\Sigma^{1/2}),\quad
s(z):=\frac{1}{p}\operatorname{Tr}(W^\top(U-zI_p)^{-1}W),\quad z\in\mathbb{C}
q(z)=\operatorname{Tr}(R(z))/p はランダム行列極限 d,p,n\to\infty で大数の法則が性質するとする.このとき,後述の仮定の下で,q は次の鞍点方程式の解が与える:
\begin{align*}
\scriptstyle
\widehat{s}(q)&\scriptstyle=b^2_t\psi_p+\frac{1}{q},\quad\hat{r}(r,q)=\frac{\psi_pa_t^2e^{-2t}}{1+\frac{a_t^2e^{-2t}\psi_p}{\psi_n}r+\frac{\psi_pv_t^2}{\psi_n}q},\quad
s(z)=\int\frac{1}{\hat{s}(q)+\lambda\hat{r}(r,q)}\rho_\Sigma(d\lambda),\\
\scriptstyle r(z)&\scriptstyle=\int\frac{\lambda}{\hat{s}(q)+\lambda\hat{r}(r,q)}\,\rho_\Sigma(d\lambda),\quad\psi_p(s_t^2-z)+\frac{\psi_pv_t^2}{\scriptscriptstyle 1+\frac{a_t^2e^{-2t}\psi_p}{\psi_n}r+\frac{\psi_pv_t^2}{\psi_n}q}+\frac{1-\psi_p}{q}-\frac{s}{q^2}=0.
\end{align*}
\sigma=\mathrm{id}_{\mathbb{R}},P_x=N_d(0,I_d) のとき,r=s で s,\hat{s} を消去すると (Marčenko and Pastur, 1967 ) の自己無撞着方程式を得る:
q(z)=\frac{1}{-z+\frac{\psi_p}{1+q(z)}}.
Gaussian Equivalence Principle
ランダム行列 X\in\mathbb{R}^{d\times n},W\in\mathbb{R}^{p\times d} の成分はそれぞれ i.i.d. で,指数より軽い裾を持ち,(0,1) に正規化されているとする. f:\mathbb{R}\to\mathbb{R} が Schwartz 急減少関数ならば, 次の2つの行列 M,M' の経験スペクトル分布は漸近同等:
M:=\frac{1}{d}f^{\otimes(p\times n)}\left(\frac{WX}{\sqrt{d}}\right)f^{\otimes(p\times n)}\left(\frac{WX}{\sqrt{d}}\right)^\top
\scriptstyle
M':=\frac{1}{n}\left(\sqrt{\theta_2(f)}\frac{WX}{\sqrt{d}}+\sqrt{\theta_1(f)-\theta_2(f)}Z\right)\left(\sqrt{\theta_2(f)}\frac{WX}{\sqrt{d}}+\sqrt{\theta_1(f)-\theta_2(f)}Z\right)^\top
ただし,Z\in\mathbb{R}^{p\times n} は Gaussian random matrix で,
\theta_1(f)=\operatorname{E}[f(Z_{11})^2],\quad\theta_2(f)=\operatorname{E}[f'(Z_{11})]^2=\operatorname{E}[Z_{11}f(Z_{11})]^2.
3.7 Gaussian Equivalence Principle
\begin{align*}
U&:=\frac{1}{n}\sum_{\nu=1}^n\operatorname{E}_\xi\left[\sigma^{\otimes p}\left(\frac{Wx^\nu_t(\xi)}{\sqrt{d}}\right)\sigma^{\otimes p}\left(\frac{Wx^\nu_t(\xi)}{\sqrt{d}}\right)^\top\right]\\
U'&:=\frac{GG^\top}{n}+b_t^2\frac{WW^\top}{d}+s_t^2I_p,\qquad G:=e^{-t}a_t\frac{W}{\sqrt{d}}X'+v_t\Omega
\end{align*}
\sigma^2_x:=\operatorname{Tr}(\Sigma)/d,\;f_t(\xi,\eta):=\sigma(e^{-t}\sigma_x\eta+\sqrt{\Delta_t}\xi)\;\xi,\eta,\zeta\sim\operatorname{N}_1(0,1) とすると
\begin{align*}
b_t&:=\operatorname{E}[\xi f_t(\xi,\eta)],\qquad a_t:=\operatorname{E}\left[\frac{\eta}{e^{-t}\sigma_x} f_t(\xi,\eta)\right],\\
v_t^2&:=\operatorname{E}[f_t(\xi,\eta)f_t(\xi,\zeta)]-a_t^2e^{-2t}\sigma^2_x,\\
s^2_t&:=\operatorname{E}[\sigma(\Gamma_t\eta)^2]-a_t^2e^{-2t}\sigma^2_x-v_t^2-b_t^2,\qquad\Gamma_t:=e^{-2t}\sigma^2_x+\Delta_t.
\end{align*}
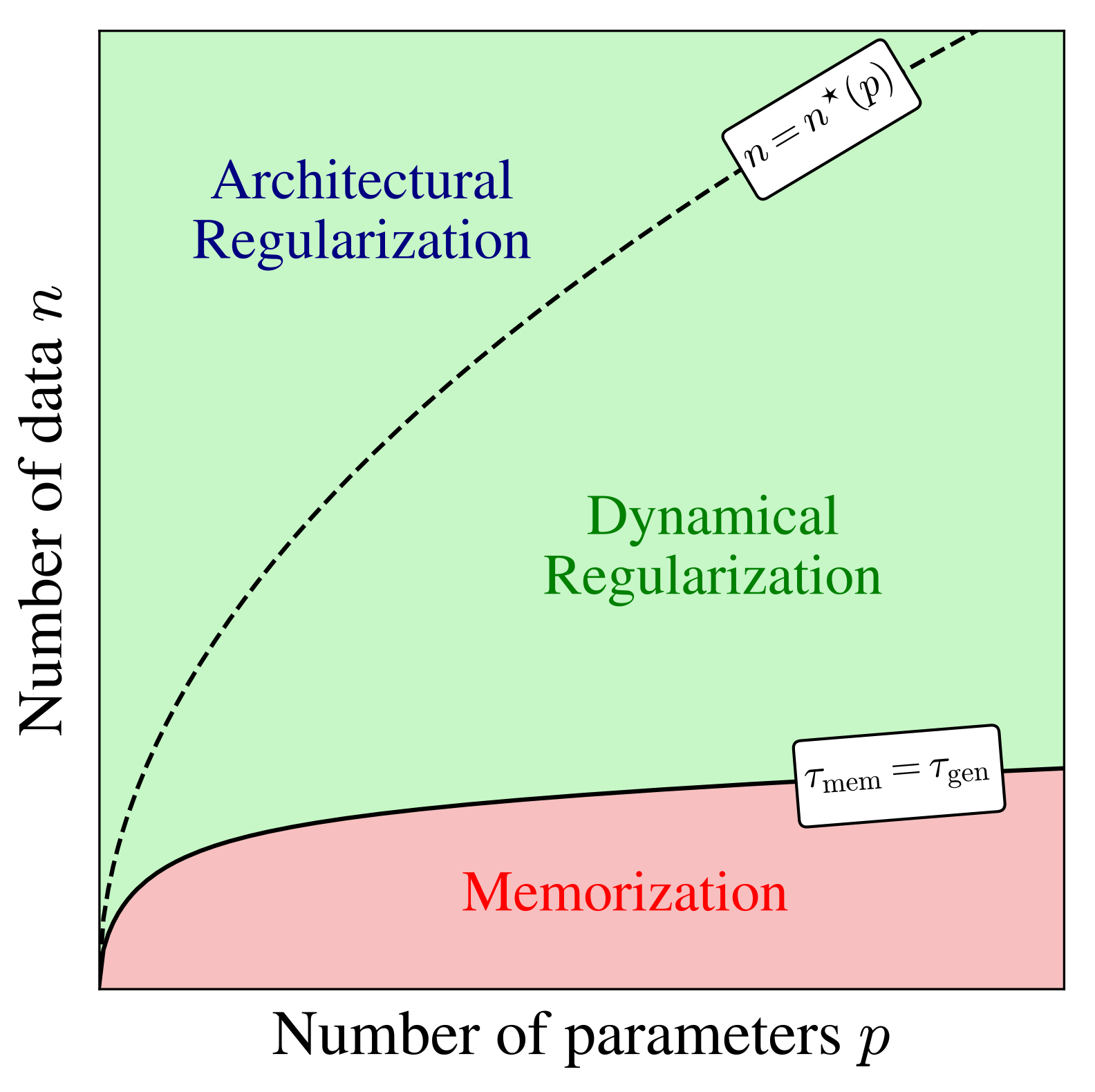
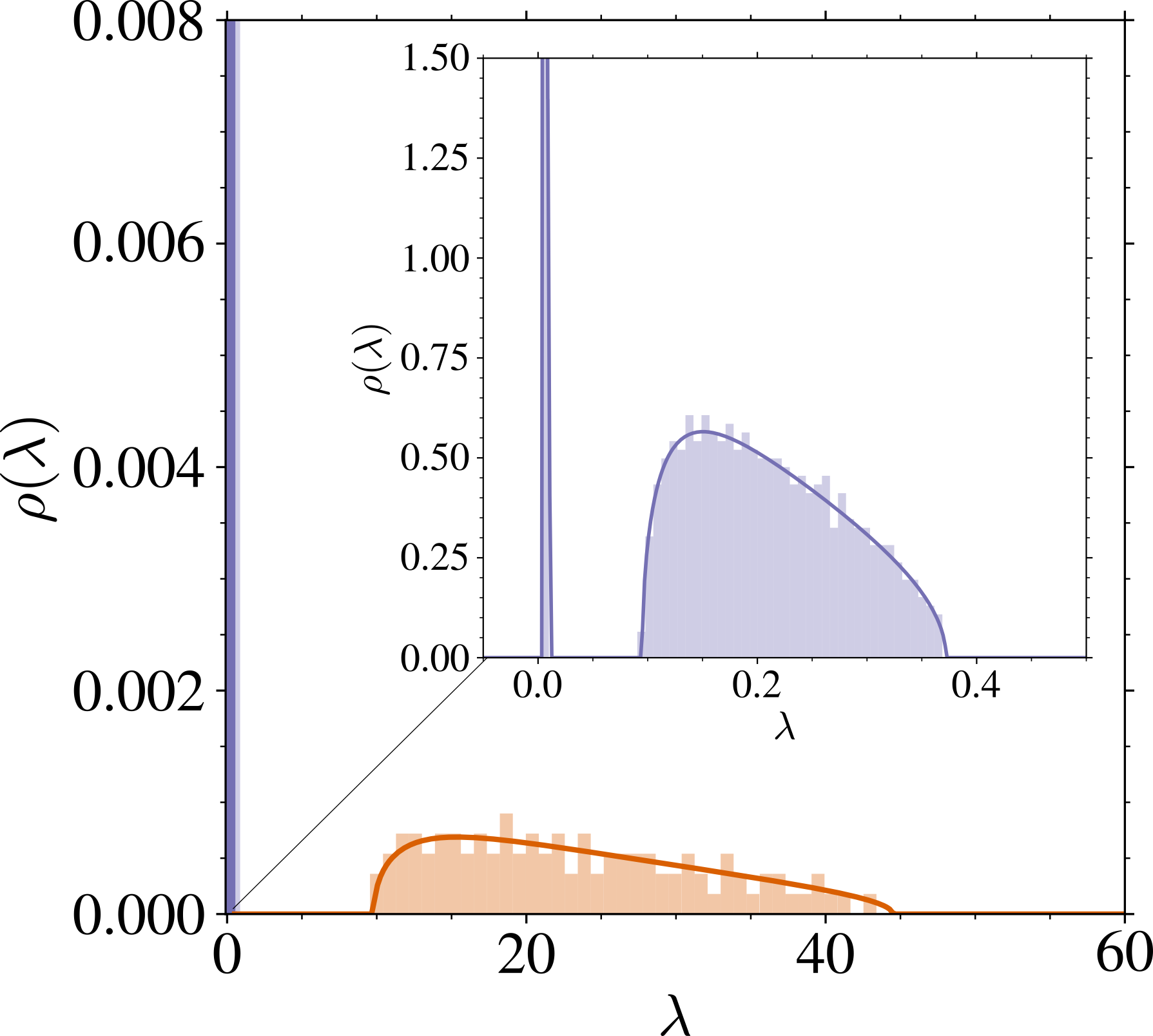
3.9 主な系:スペクトルの two-bulk 構造
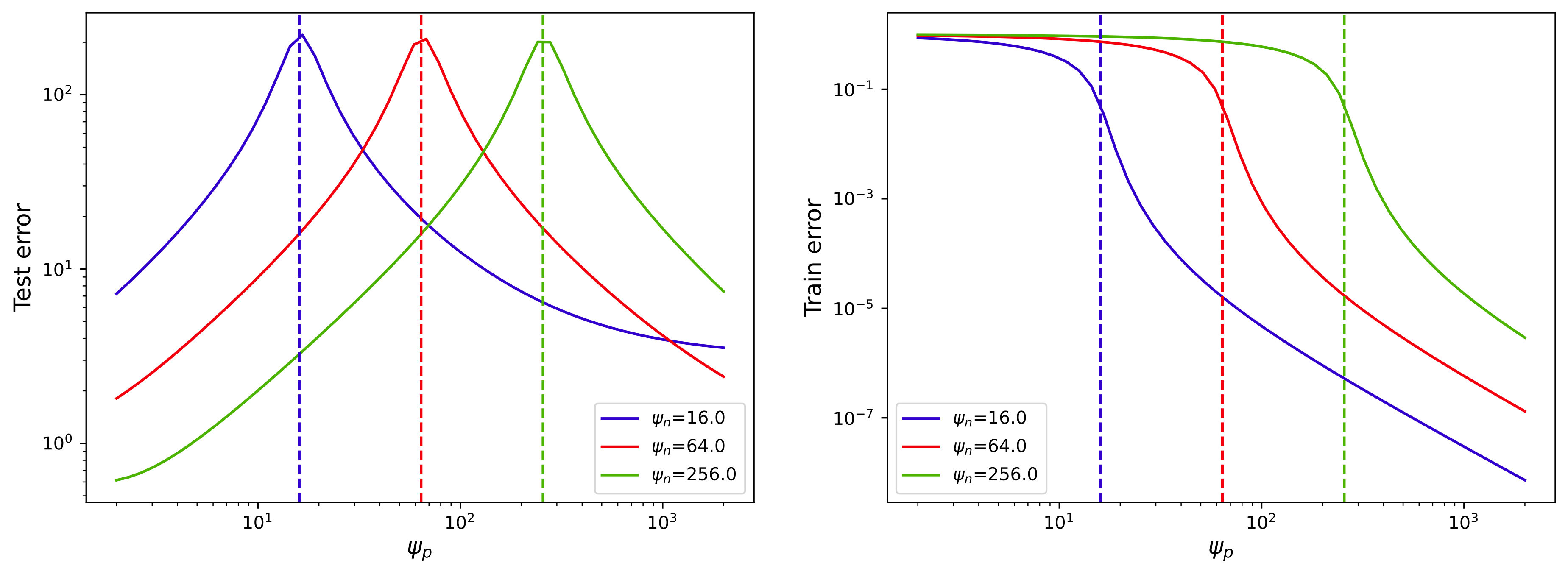
過剰パラメータ領域:\psi_p>\psi_n\gg1 のとき
\rho(\lambda)=\left(1-\frac{1+\psi_n}{\psi_p}\right)\delta_{\{s_t^2\}}(\lambda)+\frac{\psi_n}{\psi_p}\rho_1(\lambda)+\frac{1}{\psi_p}\mu_{\widetilde{U}}(\lambda).
s_t^2 に属する固有ベクトルは \mathrm{Ker}\;(A_\tau) に入り,訓練/テスト誤差の値を変えない.\rho_1 は atom を持たず,
\mathrm{supp}\;(\rho_1)=\left[s_t^2+v_t^2\left(1-\sqrt{\psi_p/\psi_n}\right)^2,s_t^2+v_t^2\left(1+\sqrt{\psi_p/\psi_n}\right)^2\right]
\mu_{\widetilde{U}} は atom を持つかもしれないが,絶対連続部分は
\inf\mathrm{supp}\;(\mu_{\widetilde{U}})=O(\psi_p)\qquad(\psi_n,\psi_p\to\infty).
特に,\psi_p/\psi_n\to\infty も仮定すると,\sup\mathrm{supp}\;(\rho_1)=O(\psi_p/\psi_n) .
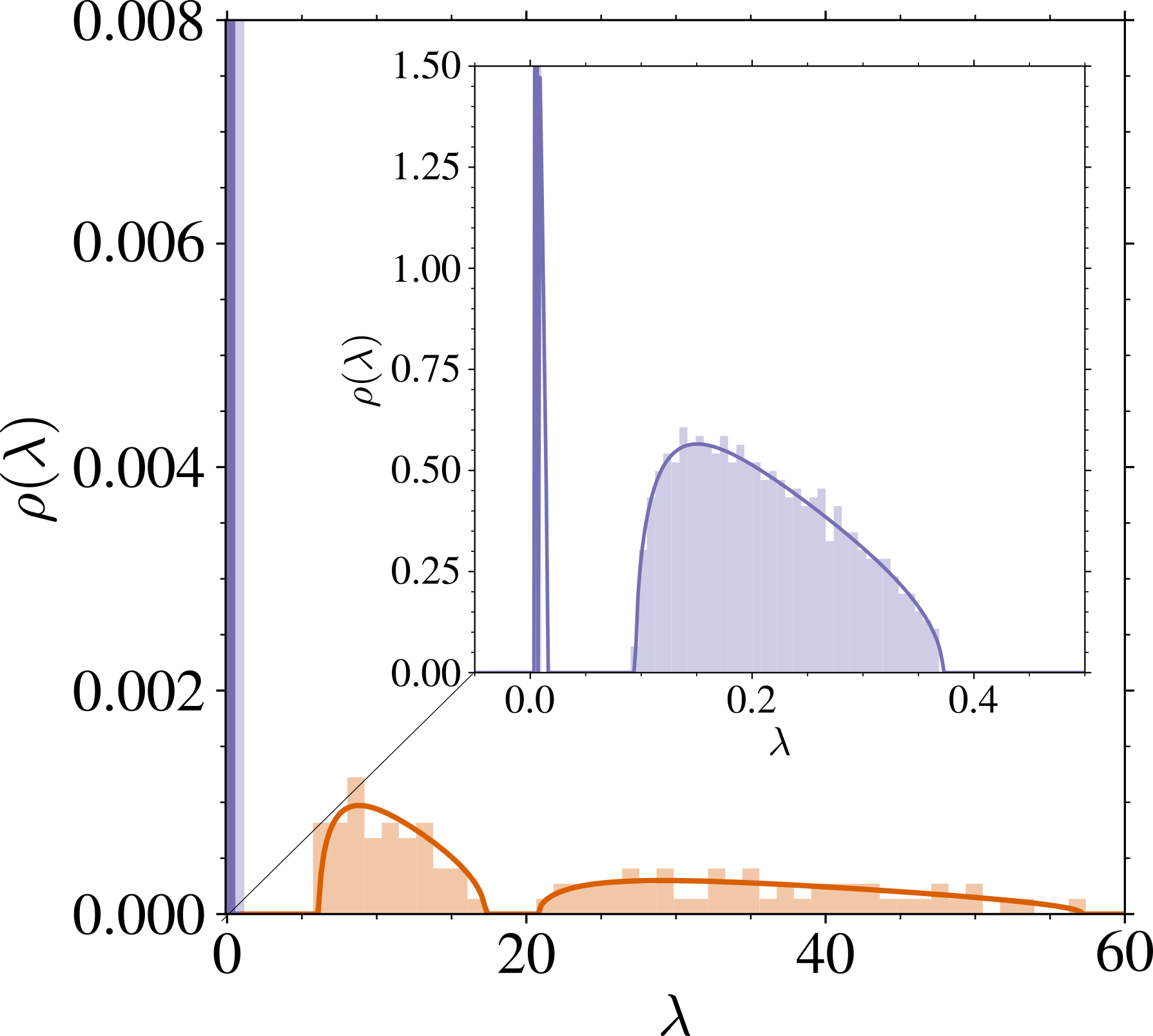
3.9 主な系:スペクトルの two-bulk 構造
過剰パラメータ領域:\psi_n,\psi_p/\psi_n\to\infty のとき
\rho(\lambda)=\left(1-\frac{1+\psi_n}{\psi_p}\right)\delta_{\{s_t^2\}}(\lambda)+\frac{\psi_n}{\psi_p}\rho_1(\lambda)+\frac{1}{\psi_p}\mu_{\widetilde{U}}(\lambda).
\sup\mathrm{supp}\;(\textcolor{#928EC3}{\rho_1})=O(\psi_p/\psi_n),\qquad\inf\mathrm{supp}\;(\textcolor{#E69252}{\mu_{\widetilde{U}}})=O(\psi_p/\psi_n\cdot\psi_n).
\rho_1 は \sigma^2_x:=\operatorname{Tr}(\Sigma)/d を通じてしかデータに依存しないので,2つの図で変わらない.
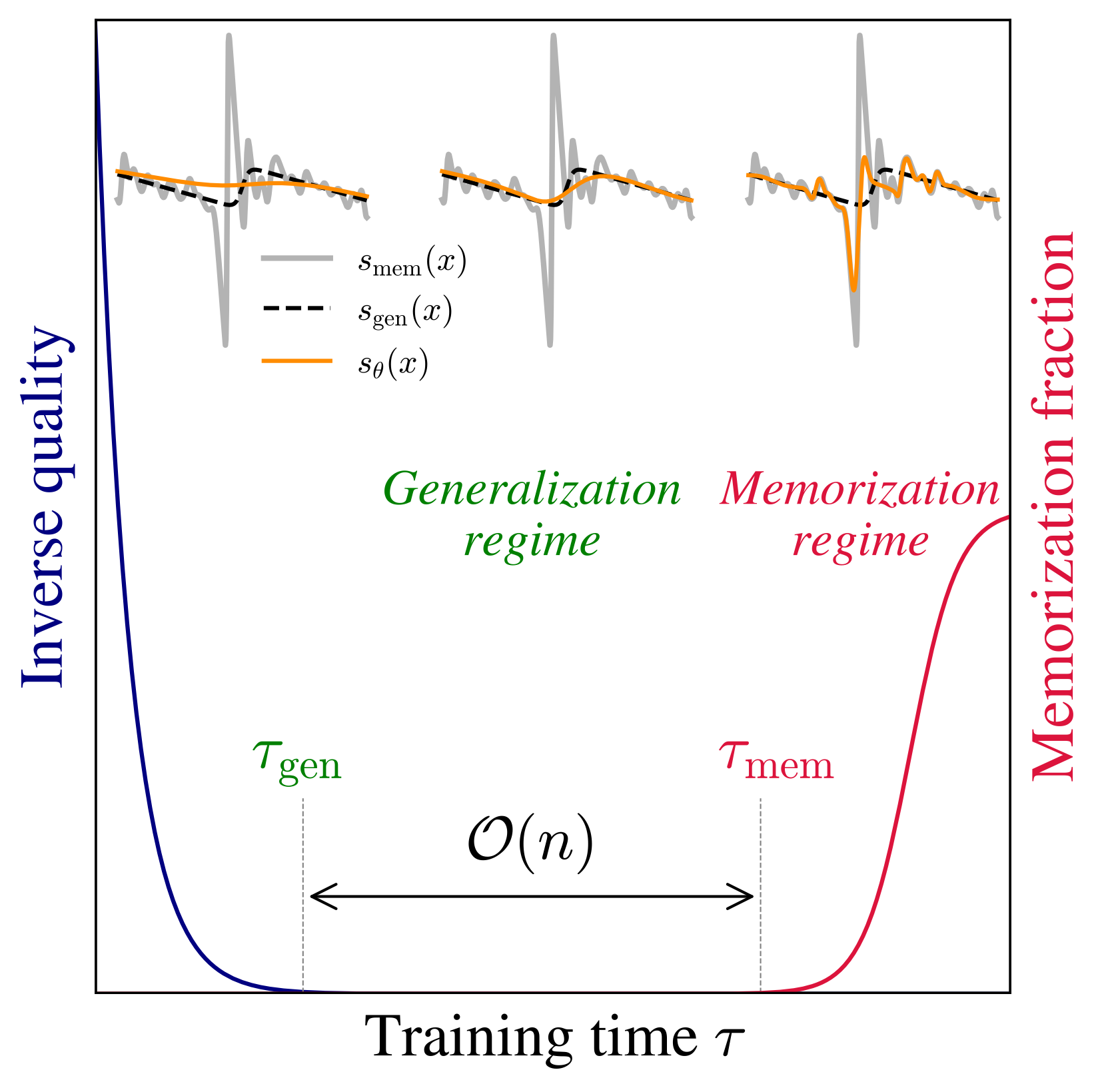
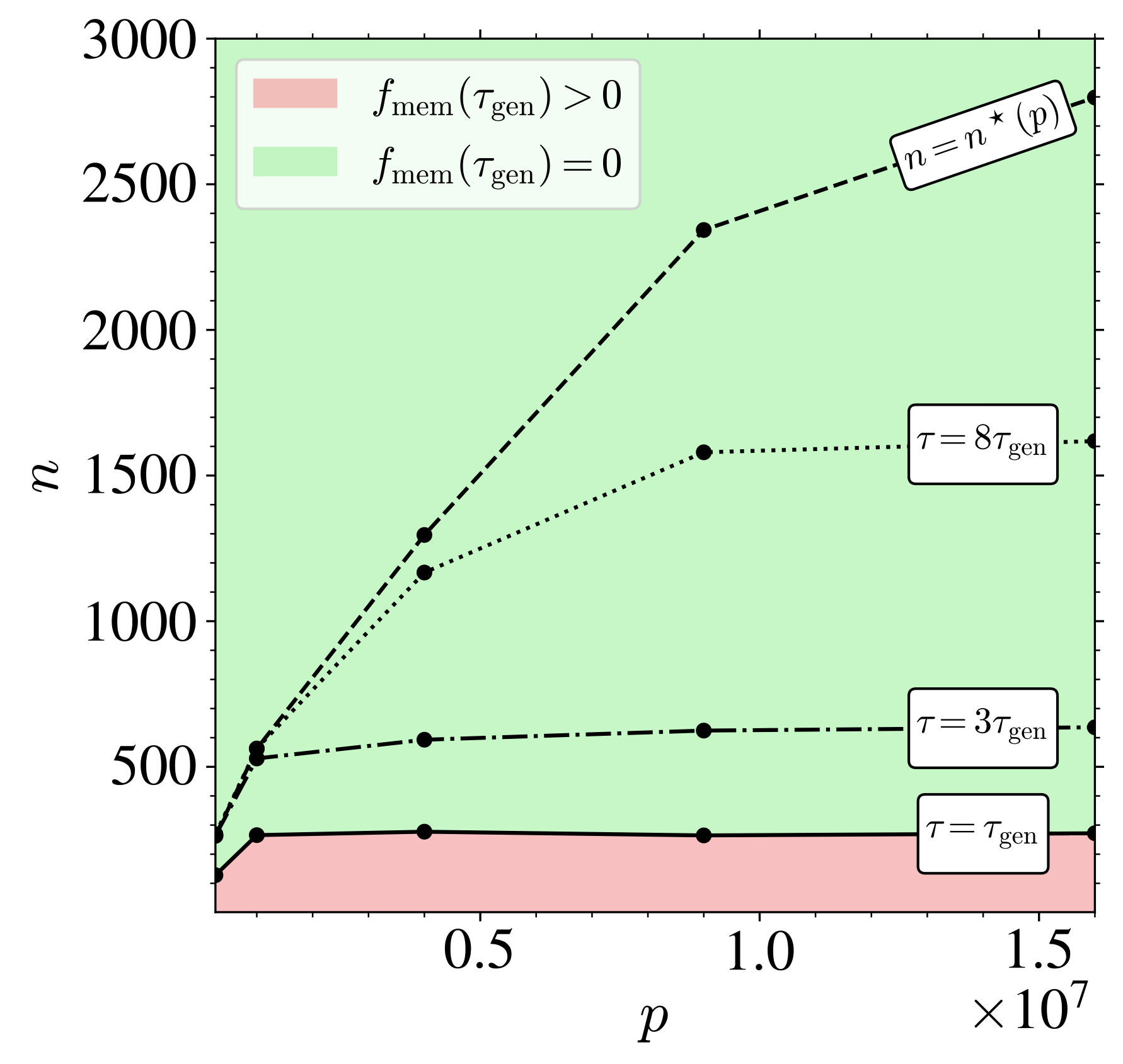
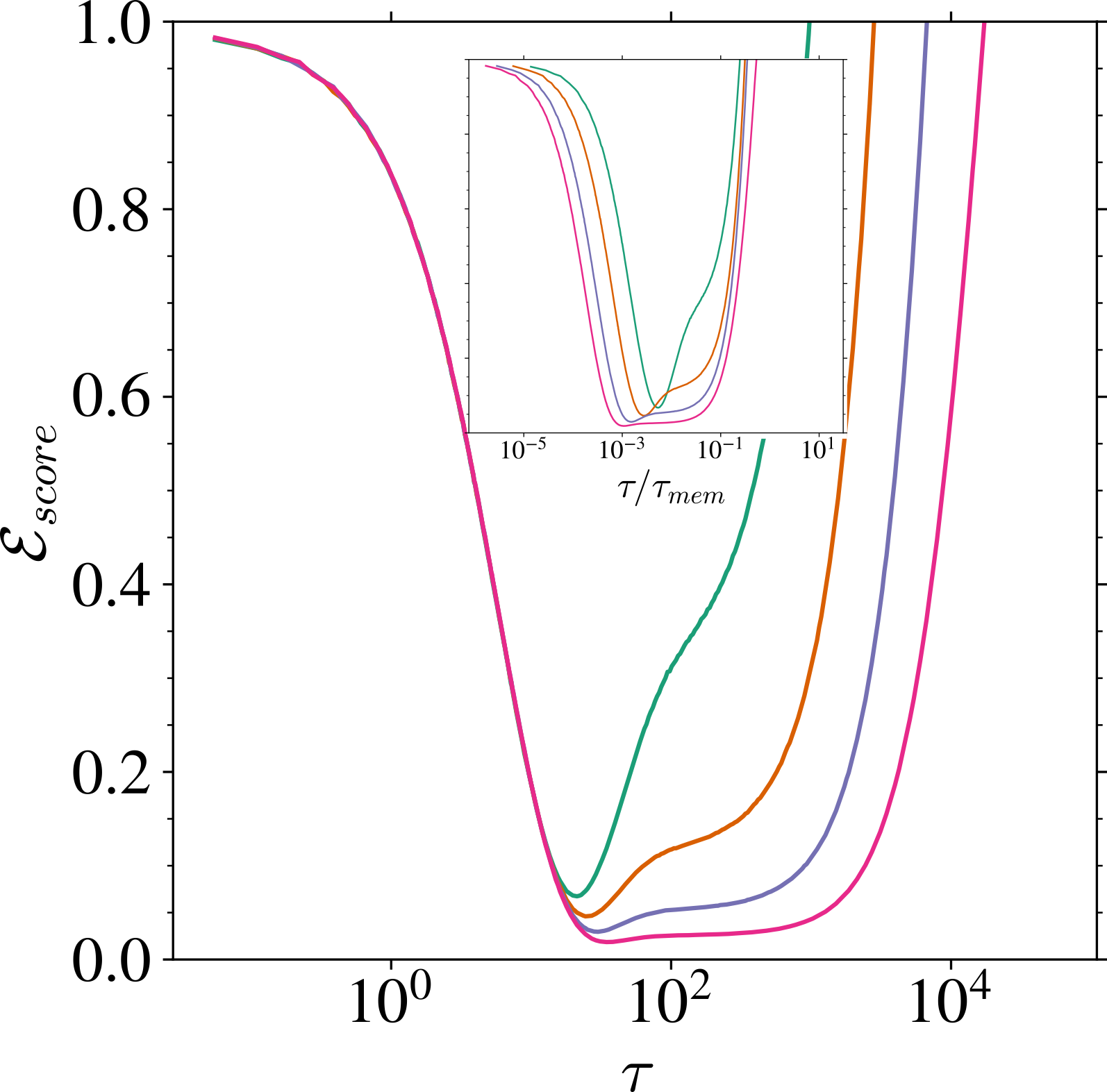
過剰パラメータ領域での訓練ダイナミクス
\tau_{\text{gen}}:=\frac{\psi_p}{\Delta_t}\inf\mathrm{supp}\;(\textcolor{#E69252}{\mu_{\widetilde{U}}})=O(1/\Delta_t).
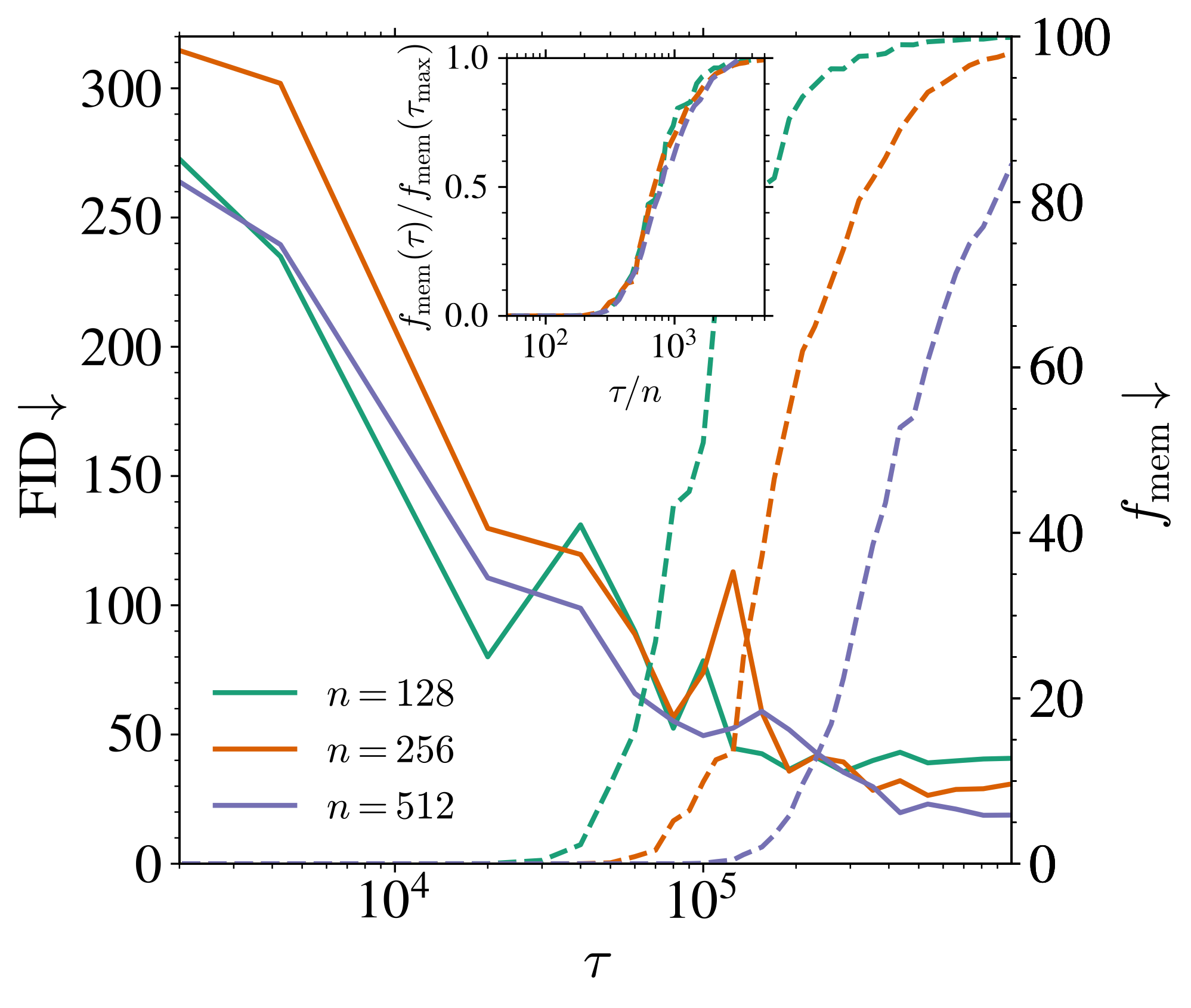
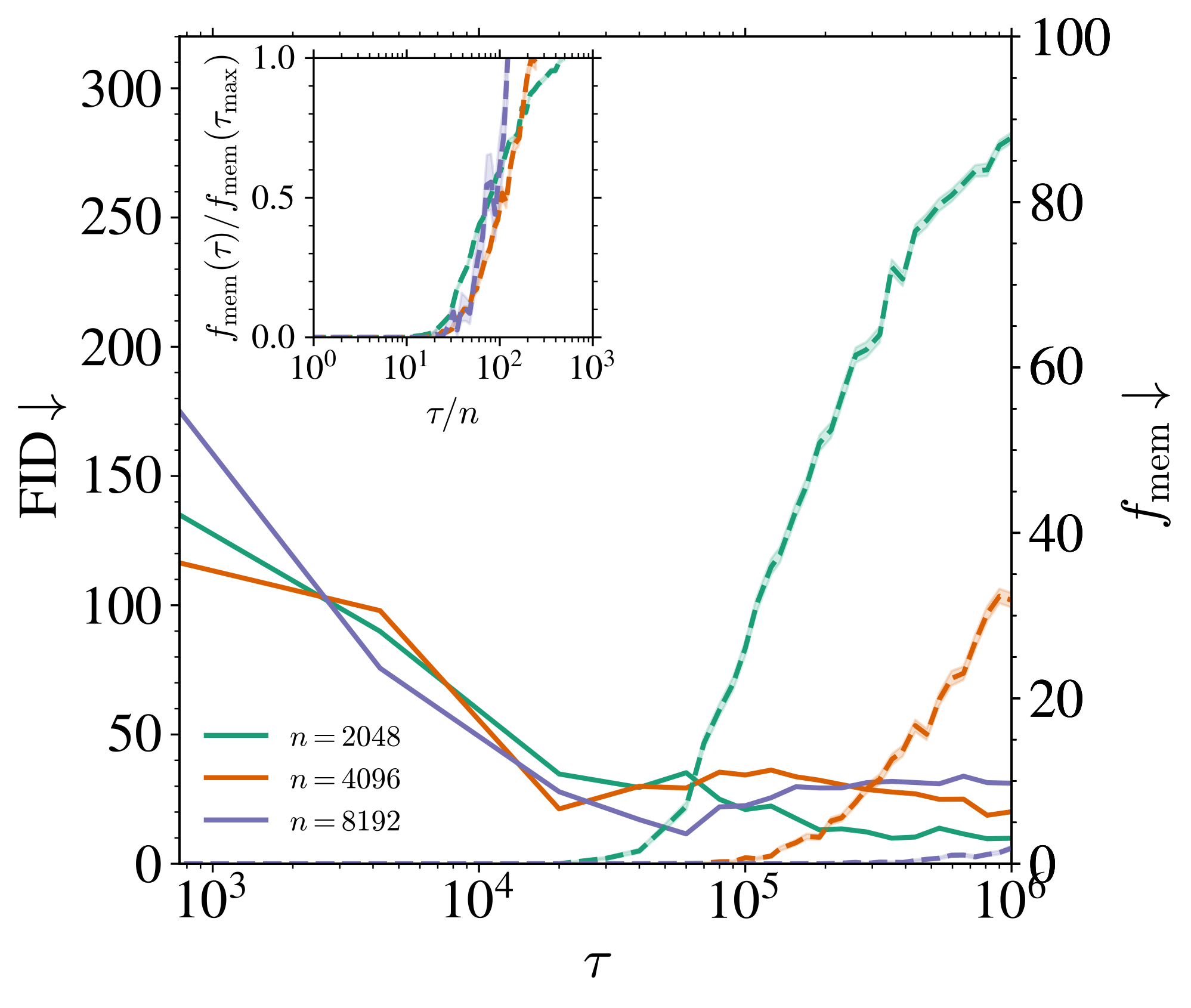
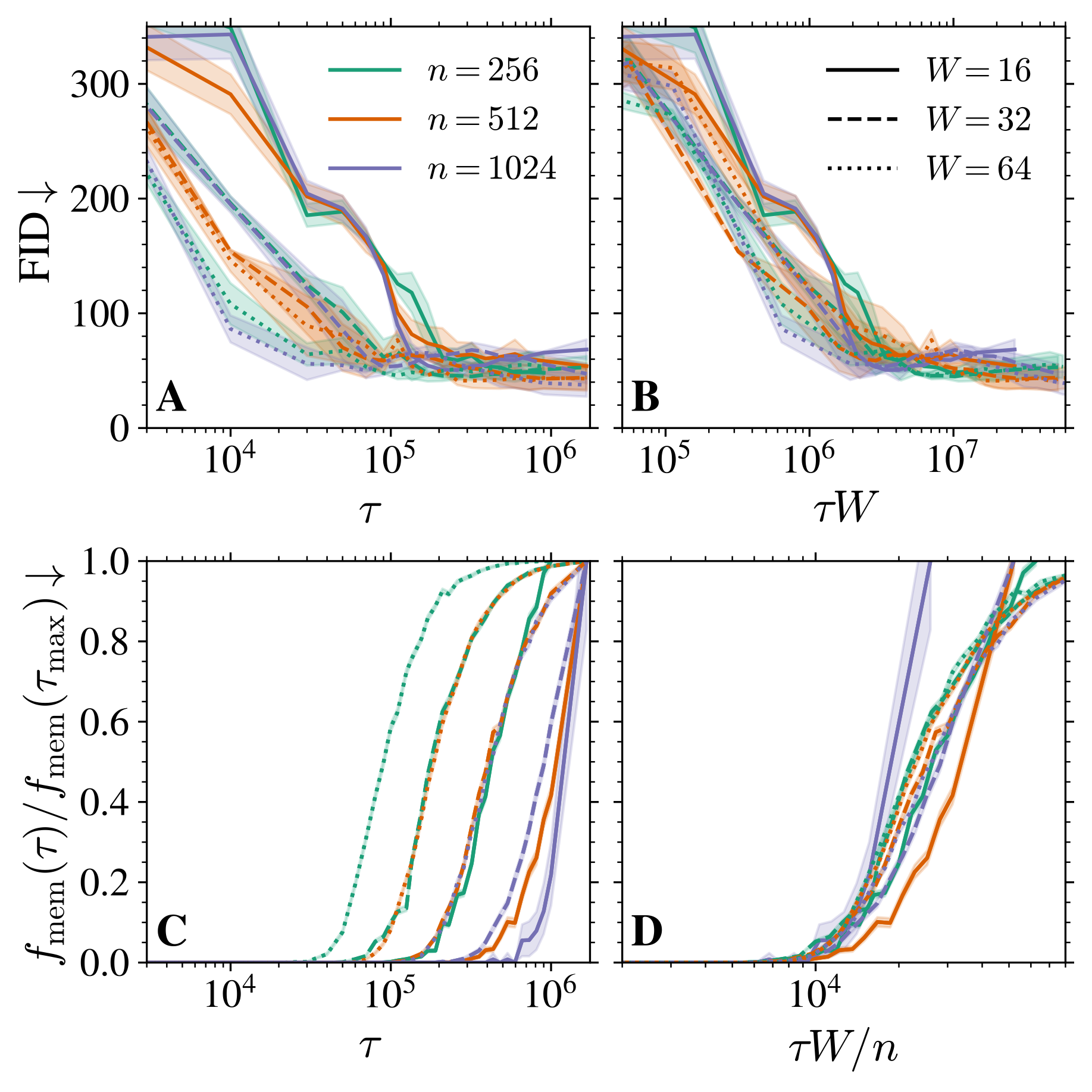
\tau_{\text{mem}}:=\frac{\psi_p}{\Delta_t}\inf\mathrm{supp}\;(\textcolor{#928EC3}{\rho_1})=O(\psi_n/\Delta_t).
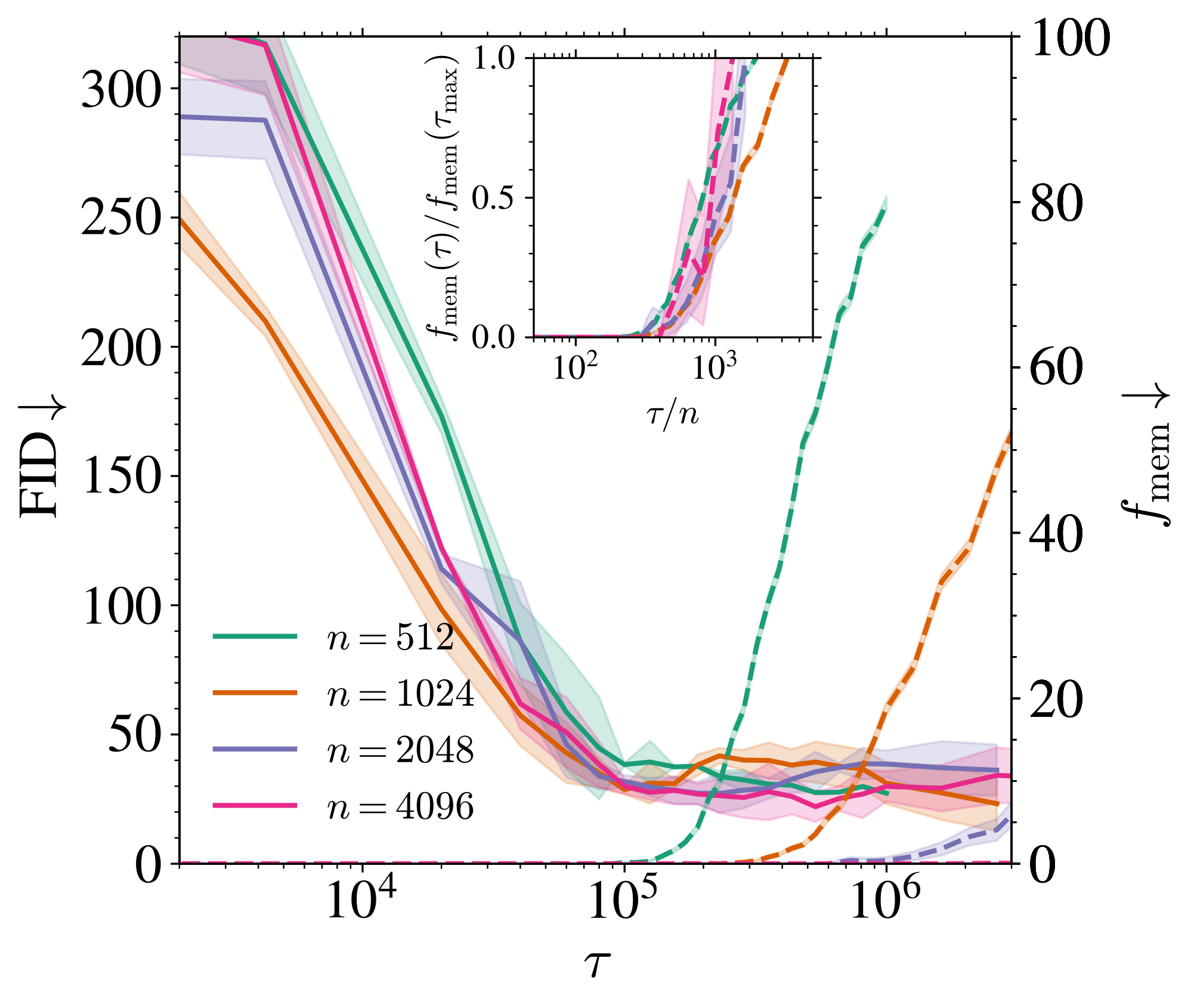
t>0 が大きく,n が大きいほど \tau_{\text{mem}} が大きい.
\mathcal{E}_{\text{score}}:=\frac{1}{d}\operatorname{E}_x\biggl[\|s_A(x)-\nabla\log P_x\|^2\biggr]
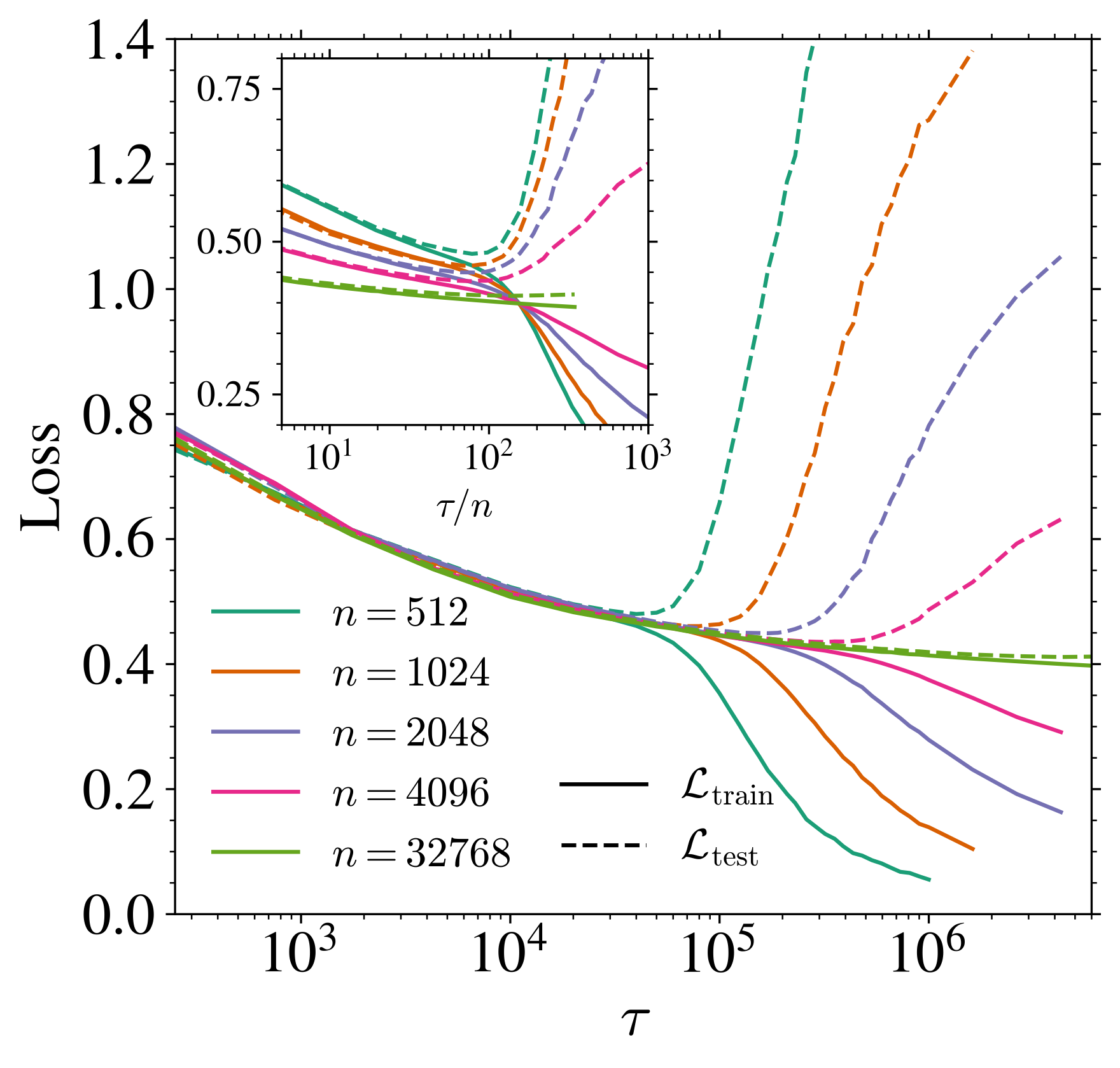
\tau_{\text{gen}} までの速いスケールでは,汎化ギャプ \mathcal{L}_{\text{gen}}=\mathcal{L}_{\text{test}}-\mathcal{L}_{\text{train}} が消える.
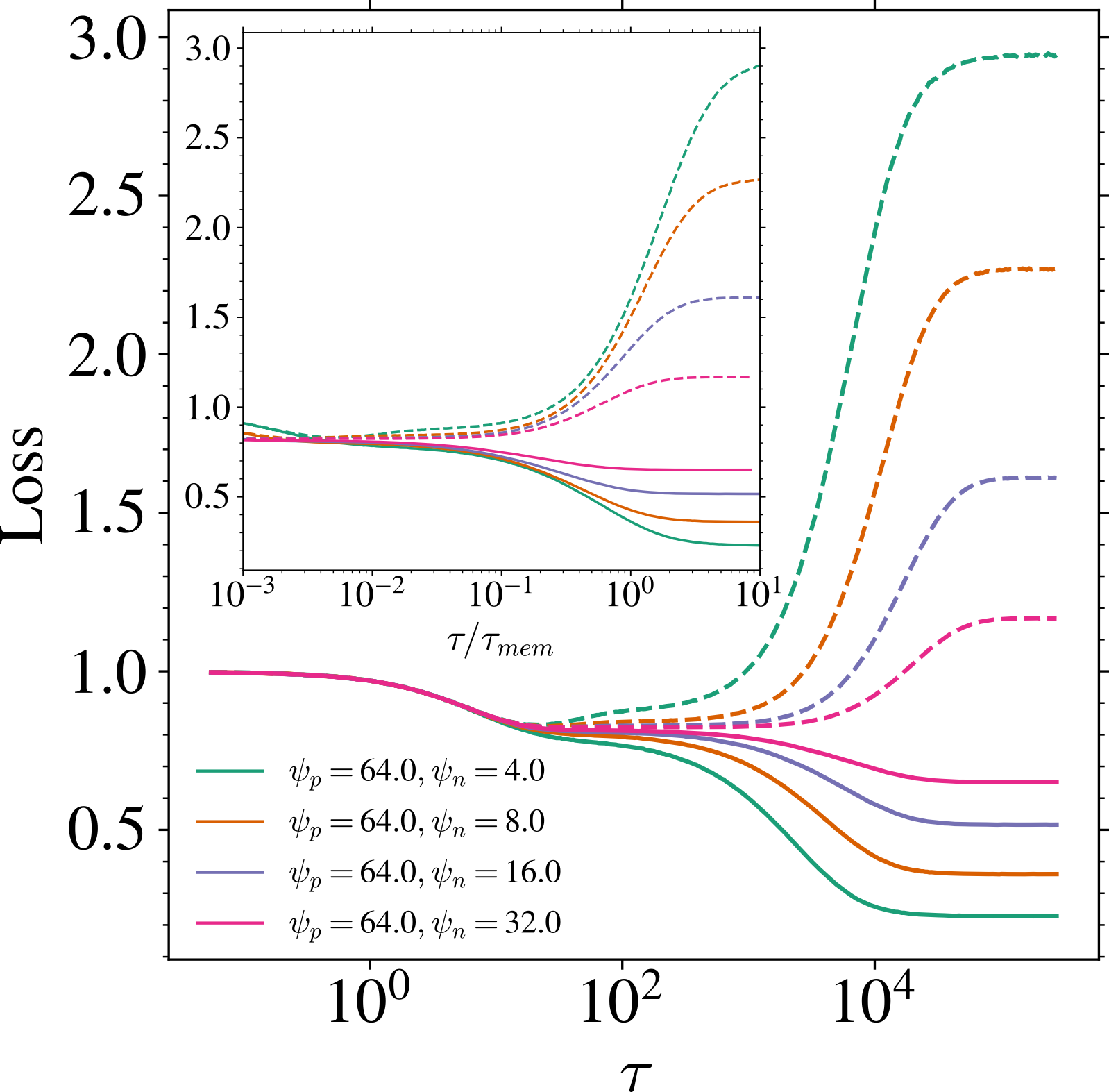
補足:経験誤差最小化解 \tau\to\infty の汎化誤差
実は収束先も n が大きいほど汎化ギャップ \mathcal{L}_{\text{gen}}=\mathcal{L}_{\text{test}}-\mathcal{L}_{\text{train}} は低くなる (George et al., 2025 ) .
ただし,パラメータ不足領域 \psi_p<\psi_n に侵入した場合は,時間スケールの分離は見られず,architectural regularization により \mathcal{L}_{\text{gen}}=\mathcal{L}_{\text{test}}-\mathcal{L}_{\text{train}} はさらに下がる.
t=0.01 .縦の点線は \psi_n=\psi_p (Figure 5 George et al., 2025 ) .\tau\to\infty の場合に対応.