Today’s Contents
1 PDMPs: A New Frontier of Monte Carlo
(1953–)
(1978–)
(2008–)
Let me start by placing PDMP in the broader history of Monte Carlo methods. The history starts with a Markov chain driven by a simple uniform random variable, originally simulated on the MANIAC computer (Metropolis et al., 1953). Then the attention naturally shifted to more structured stochastic processes, such as Langevin diffusion (Rossky et al., 1978) and PDMP (Michel et al., 2014), (Peters and de With, 2012).
A Blog Entry on Bayesian Computation by an Applied Mathematician
$$
$$
1.1 PDMP: Mathematical Definition

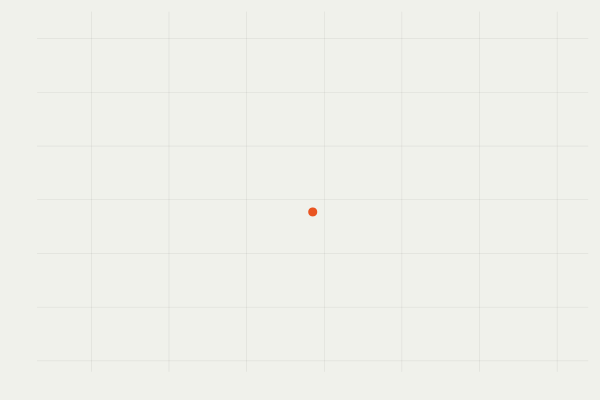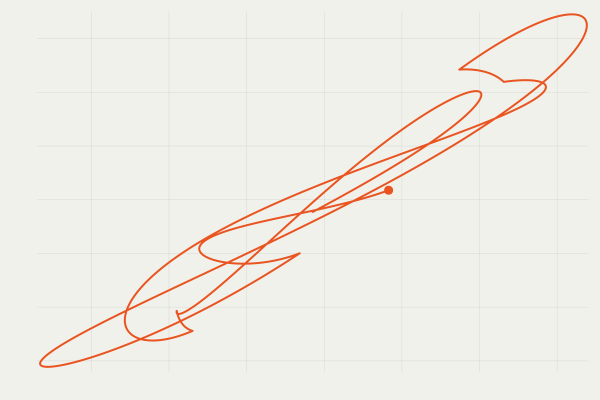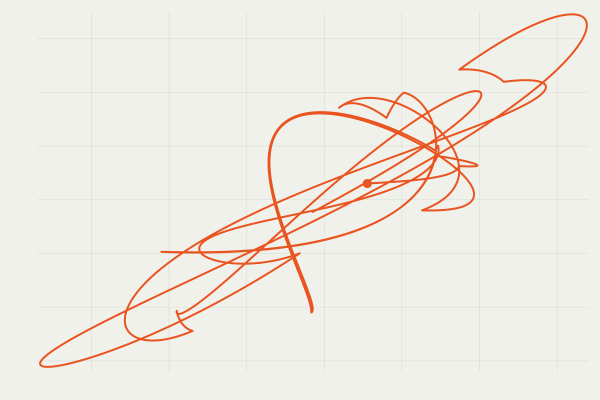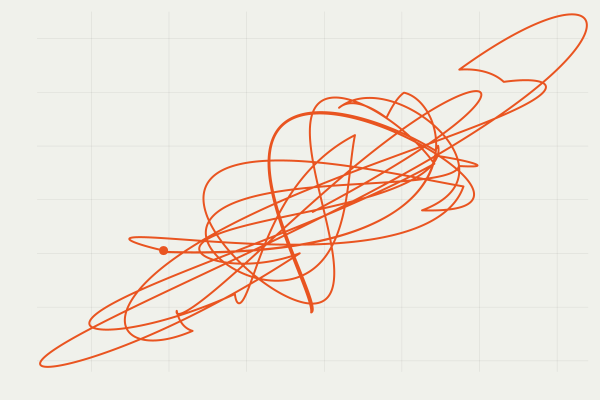
PDMP is a class of Markov processes that complements the diffusion process. A PDMP is a `diffusion’ process driven by jumps, rather than a Brownian motion. An important consequence is a strong ballistic / transport property, which is typically absent in a Langevin diffusion. Informally, the Brownian term moves only on the scale of \Delta B_t \sim \sqrt{\Delta t}.
1.2 Markov Chain Monte Carlo
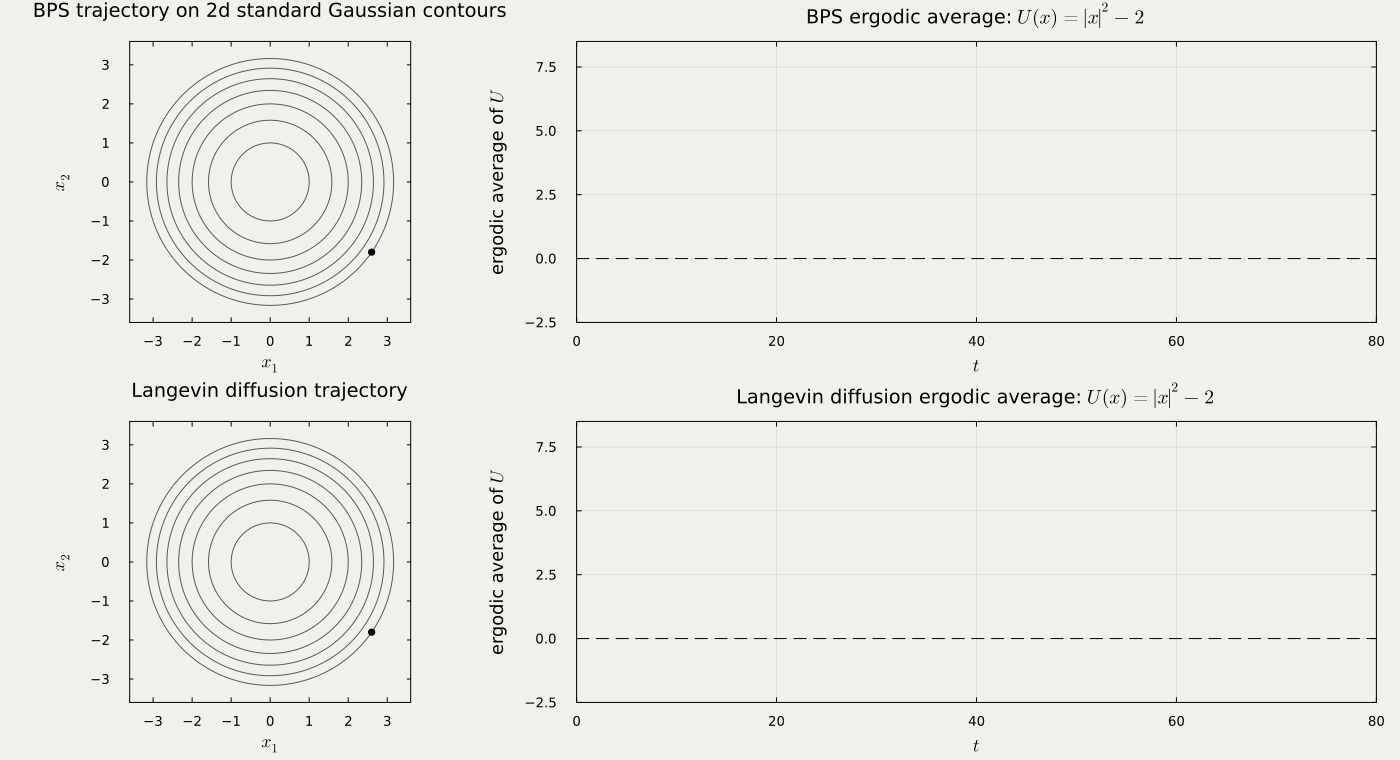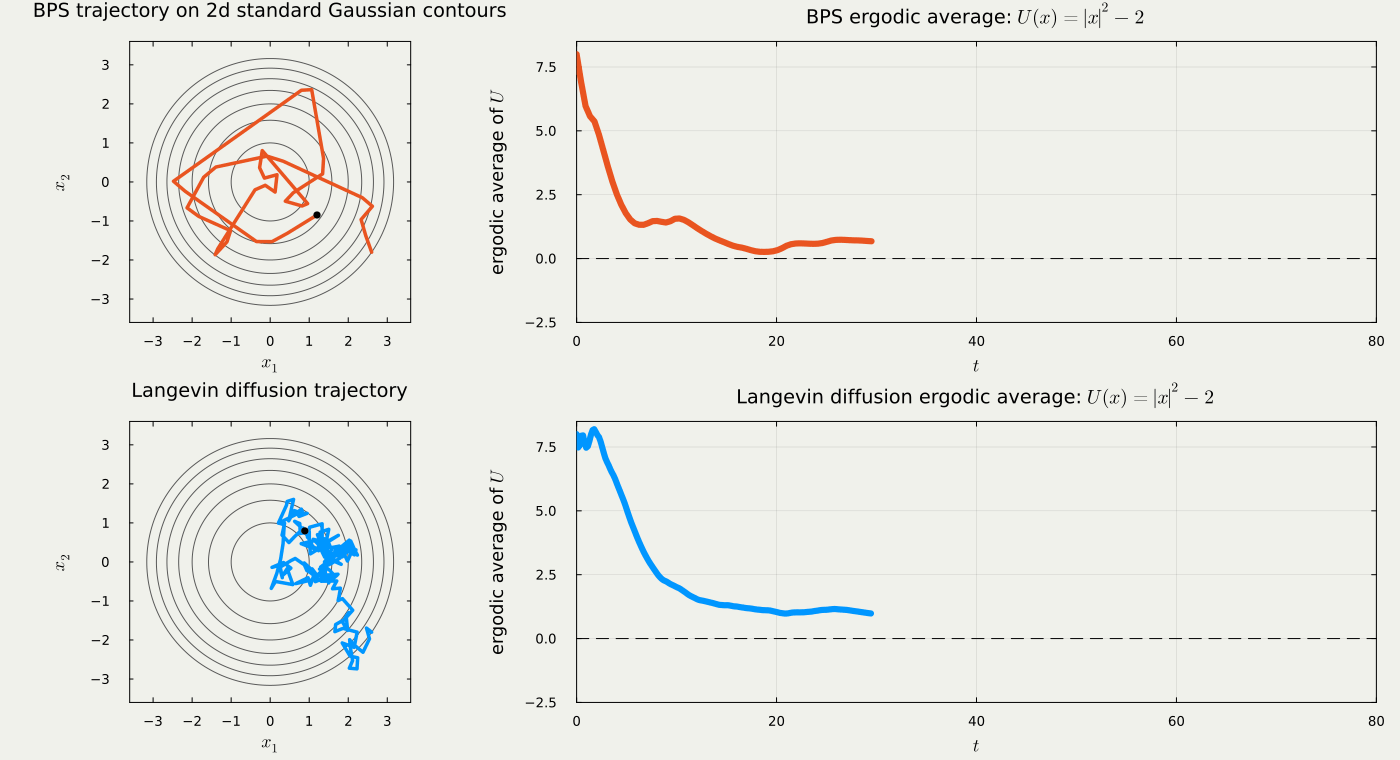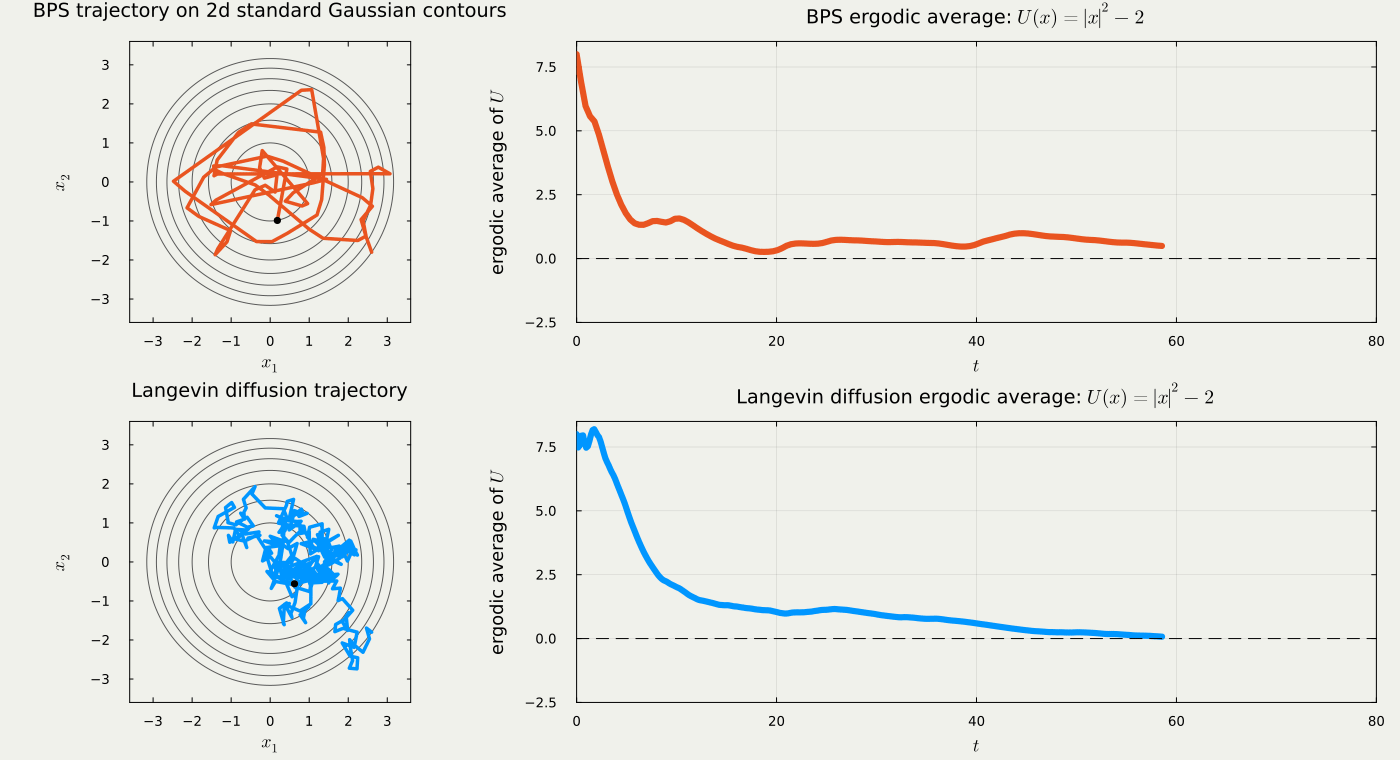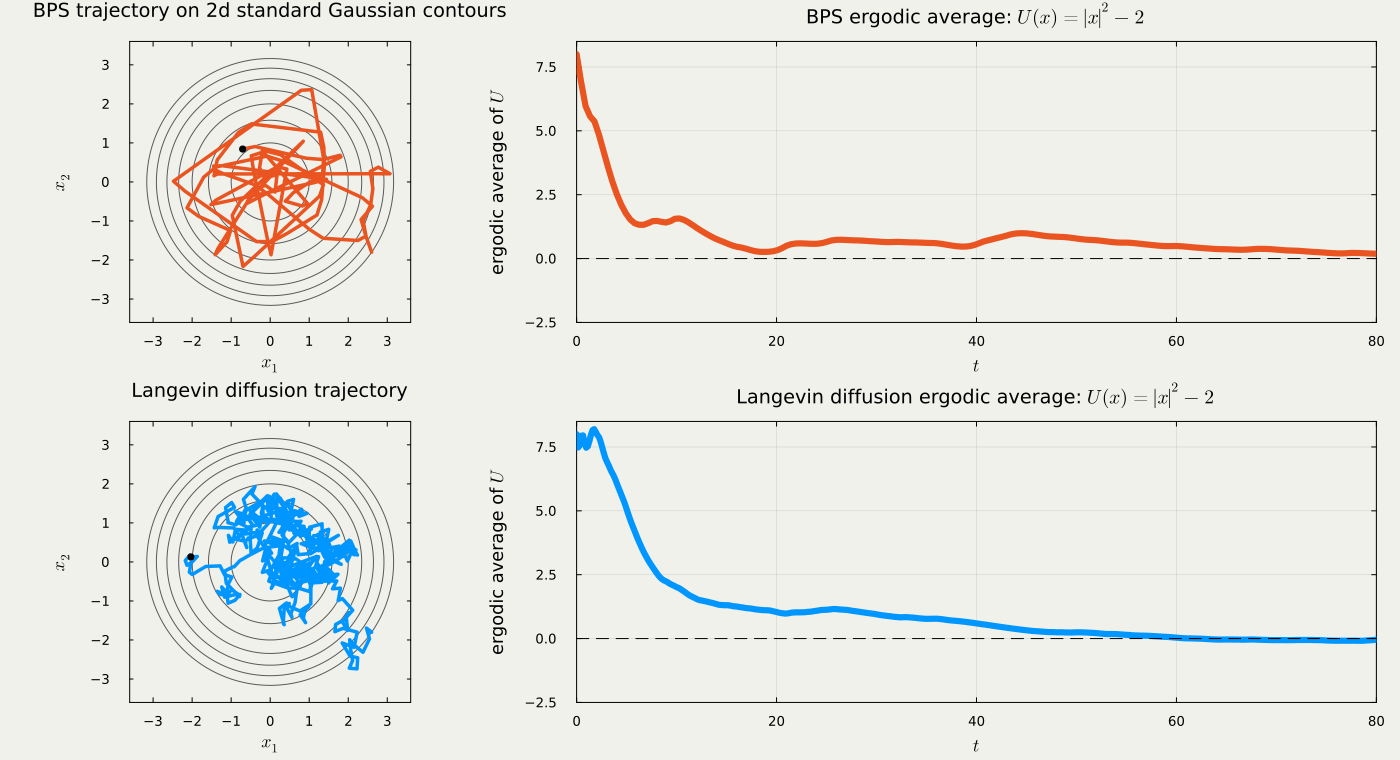
These processes are routinely used in the MCMC methodologies. However, notice that the trajectory of Langevin diffusion requires a discretization, while the output of PDMP potentially allows sparse representations, by retaining the event-time information and the new velocity at these points.
1.3 Classical Methods Turn Out to Be PDMPs in Disguise
Many PDMPs behave similarly in high dimensions.
discretized by a symplectic integrator
e.g. HMC has O(d^{1.25}) complexity

simulate piecewise linear trajectory
e.g. BPS with normal velocity has O(d^{1.5}) complexity
So far, I may have suggested that PDMP is an entirely new class of MCMC methods. Yes, in some sense, e.g., the output is a continuous trajectory instead of a set of discrete samples. However, though the term may be new to the field, it might be nothing new conceptually. To me, PDMP also works as an umbrella term that helps shed light upon a previously overlooked aspect of classical MCMC methods.
This is a somewhat strong claim, but let me pose it this way. Somehow, every successful MCMC method is implicitly a PDMP. To be precise, it chases Hamiltonian dynamics in high-dimensional settings, which may be one of the reasons why PDMP is a class of Markov processes worth considering collectively (Deligiannidis et al., 2021).
The randomized Hamiltonian Monte Carlo dynamics mix fast regardless of the dimension (for a certain class of target). From this point of view, classical Hamiltonian Monte Carlo and Bouncy Particle Sampler give different ways of numerically simulating the same dynamics.
We see a trade-off between the computational complexity and the robustness of the method.
1.4 Digression: Killer Applications of PDMP
Sparse Markov Random Field with d=10
O(d^1) Local Implementation
Exploiting sparsity, BPS atteins better scaling than HMC (MSE/sec.)
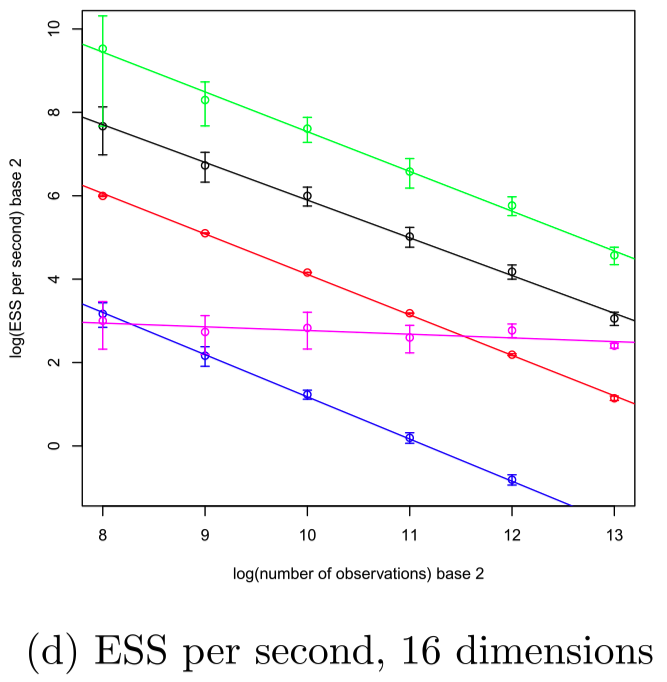
Stochastic Gradient O(n^0)
x: sample size n, y: log ESS
Logistic regression with d=16
Using an appropriate control variate, the efficiency of Zig-Zag is O(1)
in the limit of n\to\infty, it outperforms Langevin.
I briefly touch upon some killer applications of PDMP, as they are important motivations for the development of PDMP.
2 Towards Better Jump Strategy: A Scaling Analysis
We compare two famous PDMP methods under the following condition:
- ODE: Fixed
- Jump: Reflection + Refreshment vs. Combination
- Target: High dimensional standard Gaussian U(x):=-\log\pi(x)=\|x\|^2/2.

2.1 BPS vs. FECMC
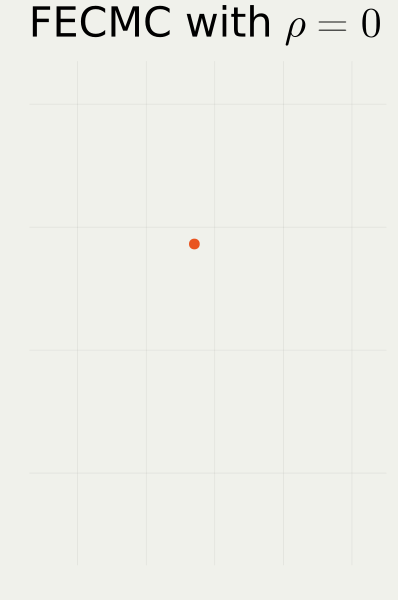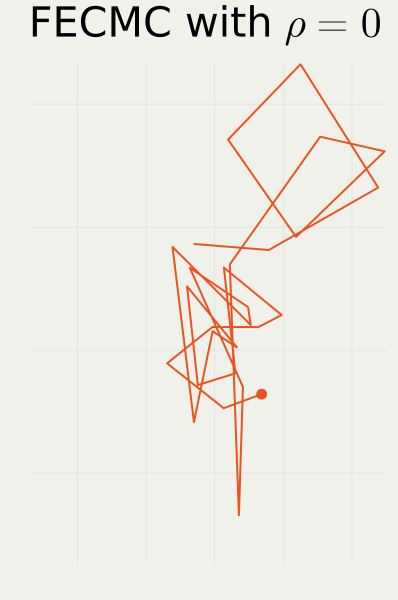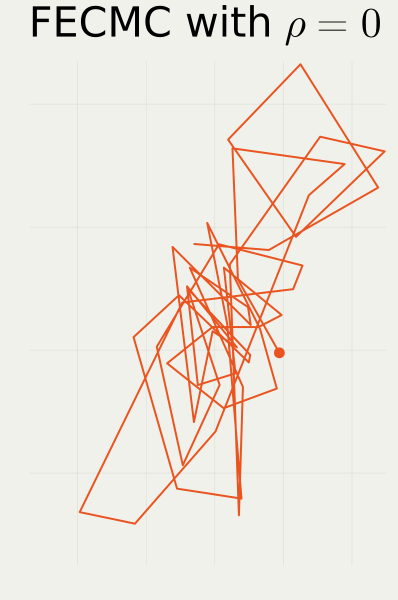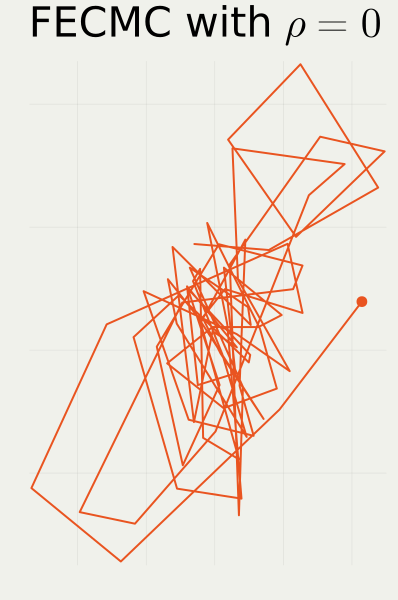
To get straight to the point, we compare the two methods with possibly different hyperparameter values \rho. Once animated, one might easily see the red method, Forward Event-Chain Monte Carlo proposed in (Michel et al., 2020), is the fastest. We would like to show this quantitatively, together with dependence upon \rho.
2.2 Jump Strategy in BPS vs. FECMC
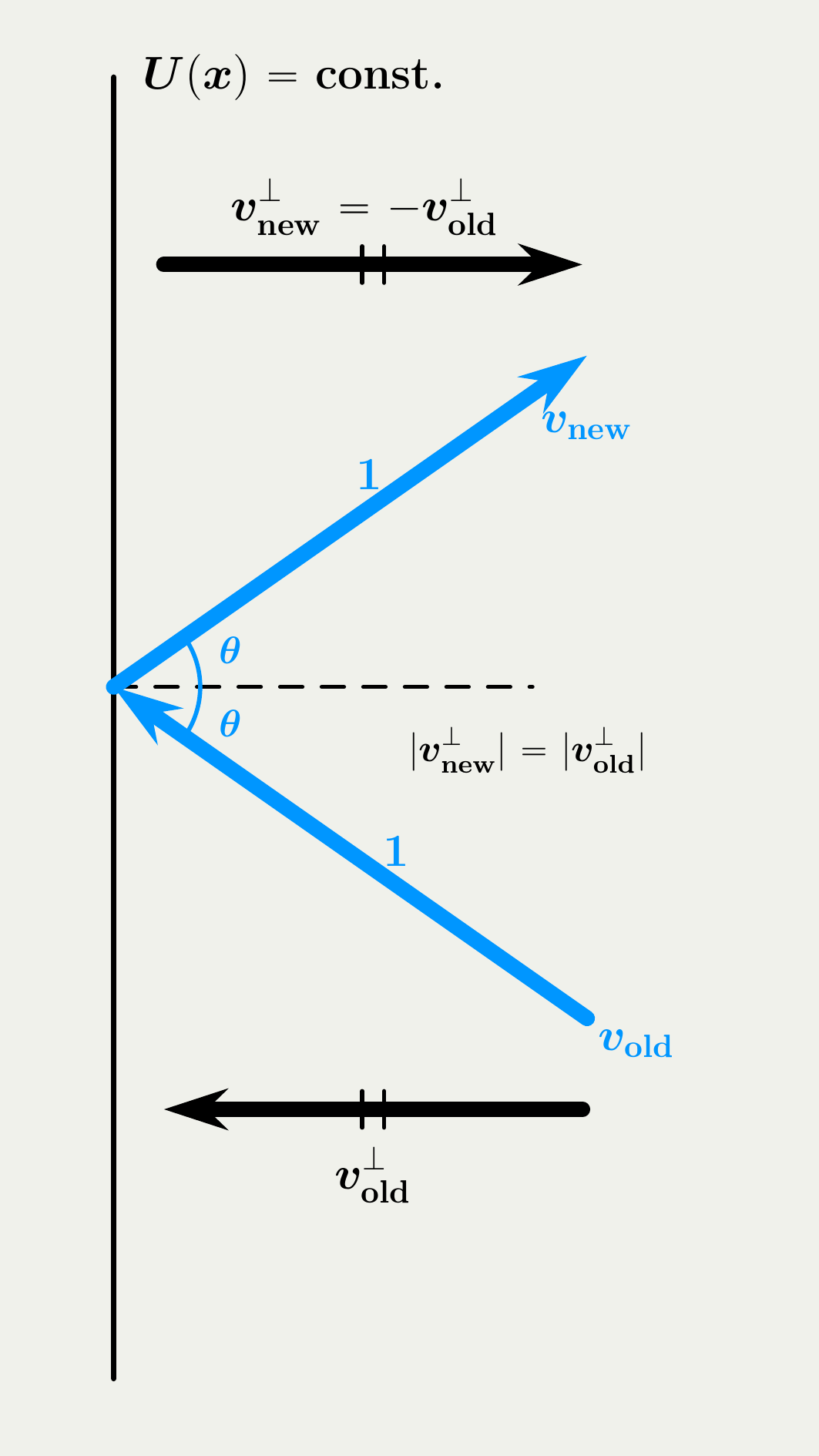
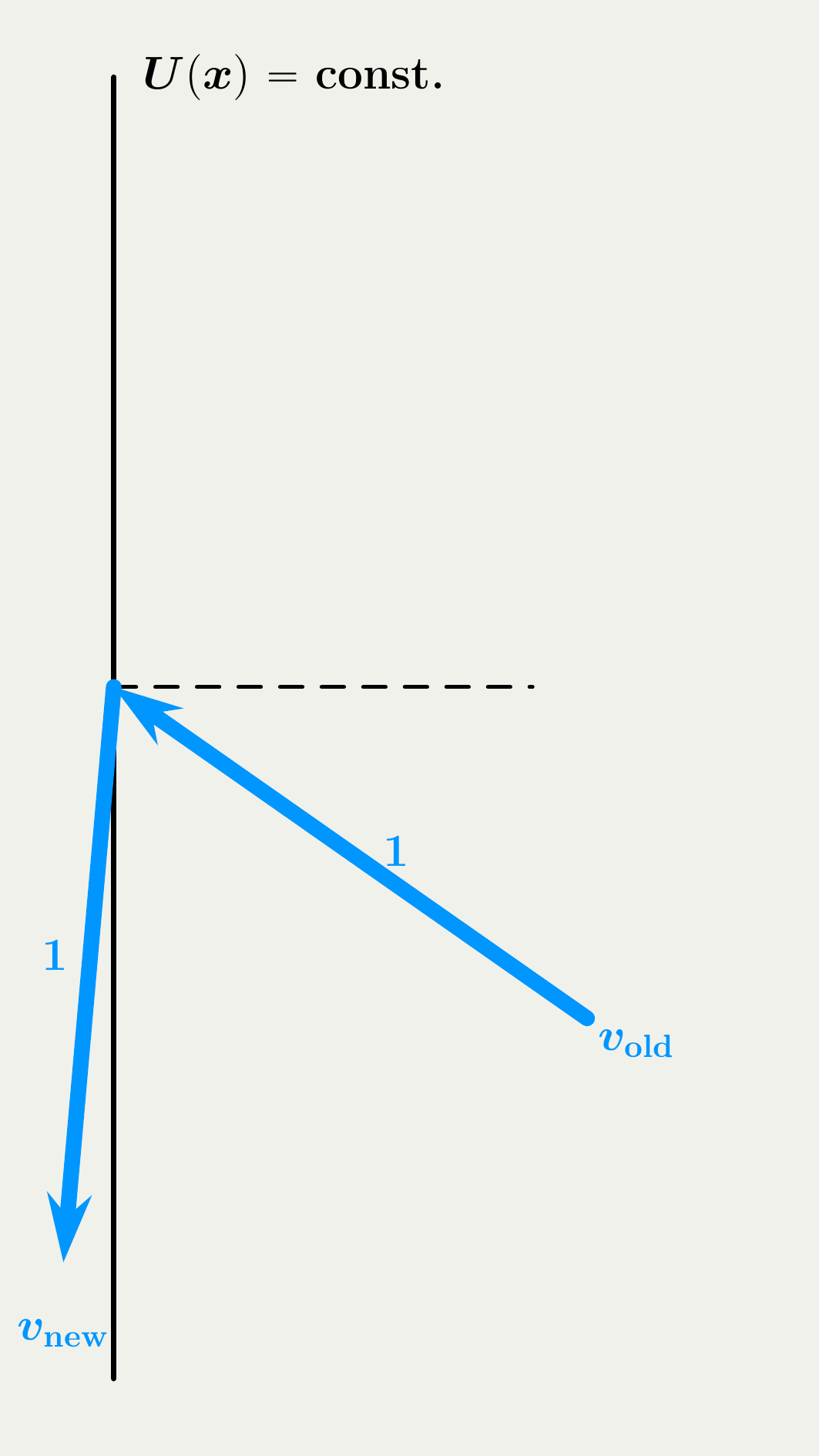
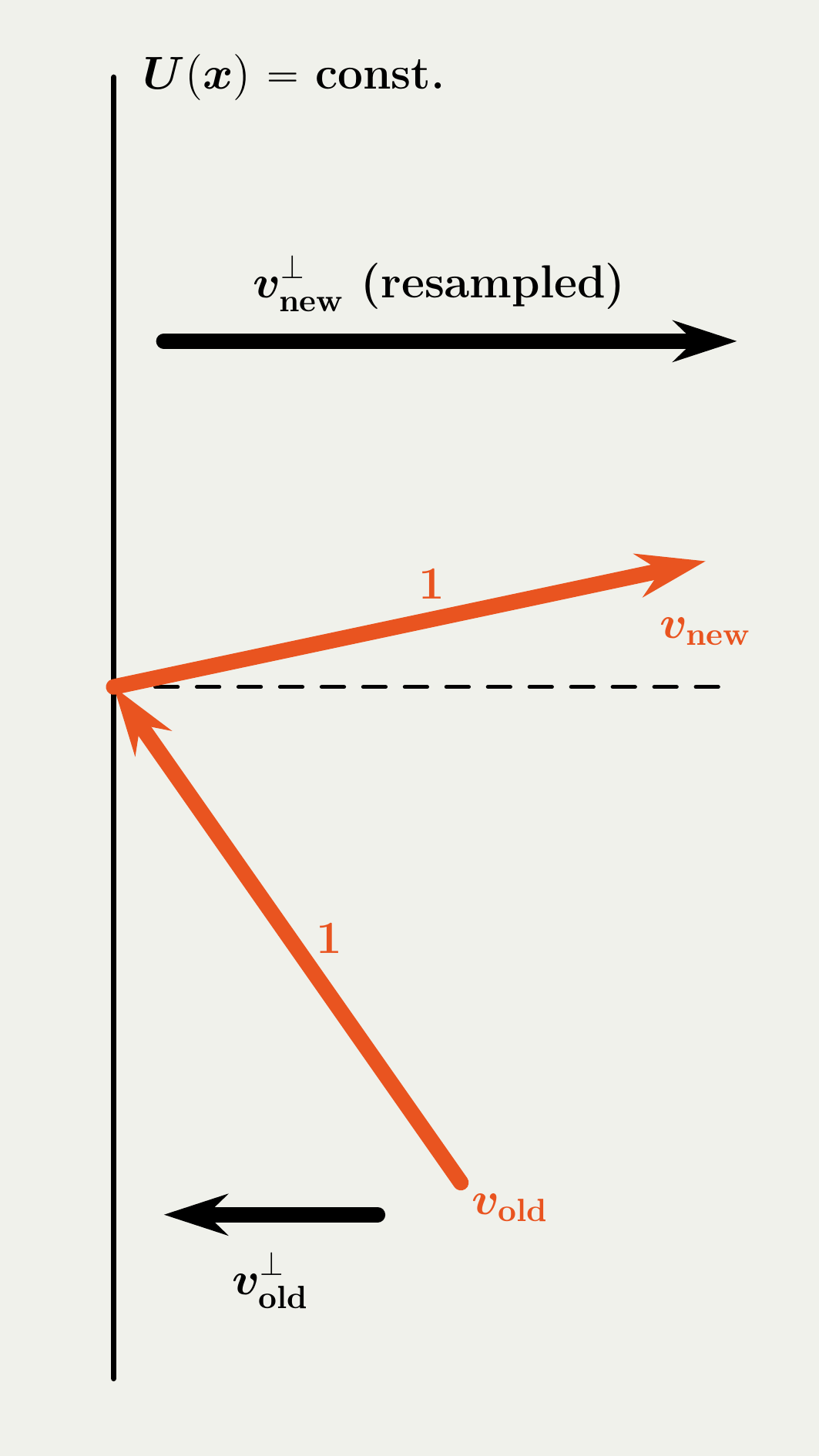
The velocity jump mechanism in BPS is simpler and we start with it. When jumps, the BPS process either reflect or refresh. On reflection, the process changes the velocity as a light ray does, matching the incidence and reflection angles. On refreshment, the process resamples the velocity from the invariant distribution, a uniform distribution on the unit sphere in our setting.
Forward Event-Chain Monte Carlo, on the other hand, is more sophisticated, combining the two mechanisms.
2.3 Empirical Comparison: BPS vs. FECMC

2.4 Scaling Analysis = Deriving a Diffusion Limit
\text{Plotting } \textcolor{#0096FF}{Y_t^{(d)}}=\frac{\lvert\textcolor{#0096FF}{X}_{d\textcolor{#0096FF}{t}}^{\textcolor{#0096FF}{(d)}}\rvert^2-d}{\sqrt{d}} \text{ with } d=10^2,10^3,10^4:

2.5 Theorem 1: Diffusion Limits of FECMC & BPS

dY_t^{\textcolor{#0096FF}{\text{B}}}=-\frac{\sigma^2_{\textcolor{#0096FF}{\text{B}}}(\rho)}{4}Y_t^{\textcolor{#0096FF}{\text{B}}}\,dt+\sigma_{\textcolor{#0096FF}{\text{B}}}(\rho)\,dB_t \sigma^2_{\textcolor{#0096FF}{\text{B}}}(\rho)=8\int^\infty_0e^{-\rho s}\operatorname{E}[R_0^{\textcolor{#0096FF}{\text{B}}}R_s^{\textcolor{#0096FF}{\text{B}}}]\,ds

dY_t^{\textcolor{#E95420}{\text{F}}}=-\frac{\sigma^2_{\textcolor{#E95420}{\text{F}}}(\rho)}{4}Y_t^{\textcolor{#E95420}{\text{F}}}\,dt+\sigma_{\textcolor{#E95420}{\text{F}}}(\rho)\,dB_t \sigma^2_{\textcolor{#E95420}{\text{F}}}(\rho)=8\int^\infty_0e^{-\rho s}\operatorname{E}[R_0^{\textcolor{#E95420}{\text{F}}}R_s^{\textcolor{#E95420}{\text{F}}}]\,ds
2.6 Theorem 2: Analytic Expression of \sigma^2’s

2.7 Sketch of Proof: the non-Markovianity of Y^d
2.8 Asymptotic Equivalence to a Skeleton Process

Difficult to see how C_t=\sigma^2t emerges.
3 Asymptotic Variance / ESS Estimation for PDMP (or continuous-time MCMC more broadly)
There is a fundamental difference between the Monte Carlo estimators produced by
\text{PDMP}\quad\widehat{h}_T^{\textcolor{#E95420}{\text{PDMP}}}=\frac{1}{T}\int^T_0h(\textcolor{#E95420}{X}_{\textcolor{#E95420}{t}}^{\textcolor{#E95420}{(d)}})\,dt,\quad t\in[0,T], \text{classical MCMC}\quad\widehat{h}_N^{\textcolor{#0096FF}{\text{MCMC}}}=\frac{1}{N}\sum_{n=1}^Nh(\textcolor{#0096FF}{X_n^{(d)}}),\quad n=1,\cdots,N.
Exploiting this continuous-time nature of PDMP, we can introduce more efficient estimators for the asymptotic variance of \widehat{h}_T^{\textcolor{#E95420}{\text{PDMP}}}.
Algorithmically, there is a fundamental difference in the Monte Carlo estimator produced by PDMP & classical MCMC. As the algorithm outputs a continuous trajectory, we are able to look into fine structure of the trajectory, which is not possible with classical MCMC.
3.1 Implications of the Diffusion Limit Results
[Proof] The Monte Carlo estimator (= ergodic average of \textcolor{#E95420}{\{X_t\}}) \widehat{h}_T^d:=\frac{1}{T}\int^T_0U(\textcolor{#E95420}{X_t^{(d)}})\,dt has a computable variance under double asymptotic limit: \lim_{T\to\infty}\lim_{d\to\infty}T\frac{\operatorname{Var}[\widehat{h}_{\textcolor{#E95420}{d}T}^d]}{\operatorname{Var}_\pi[U]}=\frac{8}{\sigma^2}\approx2.50\cdots. ESS equals the inverse of this variance ratio.
3.2 Theory Matches Practice: FECMC vs. BPS

3.3 Asymptotic Variance Estimation for MCMC

\text{Markov Chain CLT: }\quad\frac{1}{\sqrt{N}}\sum_{n=1}^NX_n\Rightarrow N(0,\sigma^2_{\text{asym}})\quad(N\to\infty). For mini-batches b=1,\cdots,B with length m:=N/B, \operatorname*{{Batch\; Means\; Estimator:}}_{\text{(for mean estimation)}} \text{ }\quad\widehat{\sigma^2}_\text{asym}:=\frac{m}{B-1}\sum_{b=1}^B\left(\textcolor{#0096FF}{\overline{{X}}^{(b)}}-\textcolor{#0096FF}{\overline{{X}}}\right)^2, where \textcolor{#0096FF}{\overline{{X}}^{(b)}}=\frac{1}{m}\sum_{n=1}^m\textcolor{#0096FF}{X_{n+(b-1)m}} is the mean over the b-th batch.
3.4 Optimal Batch Size for Classical MCMC & PDMP

3.5 Diffusivity Estimation for High-dimensional PDMPs
= Quadratic Variation (QV) Estimation under Misspecification

The Realized Volatility estimator (Barndorff-Nielsen and Shephard, 2002) \widehat{Q}^d:=\frac{1}{T}\sum_{n=1}^N\biggr(Y_{\Delta n}^d-Y_{\Delta(n-1)}^d\biggl)^2,\quad T=\Delta N, converges to \sigma^2 under the conditions \Delta\to0,\quad d\to\infty,\quad\Delta d\to\infty.
3.6 Experiment: QV Estimation Improves with Dimension

3.6 Experiment: QV Estimation Improves with Dimension

3.7 Batch Size Selection for the QV Estimator
\fallingdotseq selecting the sampling step size \Delta under Misspecification (Aït-Sahalia et al., 2011)

For too small / large \Delta, \widehat{Q}^{d}(\Delta)\approx0. The optimal choice seems to be \Delta=O(d^{1/2}).

Conclusion
- Reducing redundant noise produces a more efficient algorithm: BPS → FECMC
- Continuous-time MCMC allows more efficient estimators for asymptotic variance
- potentially works whenever a diffusion limit exists