或る区分確定的マルコフ過程のスケーリング極限
2/05/2026
1 背景:PDMP とその特殊性
モンテカルロ法に用いられる PDMP の例:Forward Event-Chain Monte Carlo
A Blog Entry on Bayesian Computation by an Applied Mathematician
$$
$$
1.1 モンテカルロ法小史
(1953〜)
(1978〜)
(2008〜)
1.2 Piecewise Deterministic Markov Process

直感:SDE より ODE の離散化の方が「扱いやすい」
1.3 HMC v. PDMP:高次元ではほぼ同じ.離散化が違うのみ
PDMP サンプラーは ODE Solver なしで Hamiltonian flow を近似できる
symplectic integrator で離散化
O(d^{1.25}) の計算複雑性

大量の Poisson 点測度 で近似
通常時は O(d^{1.5}) の計算複雑性
1.4 PDMP は killer application での爆発力がすごい
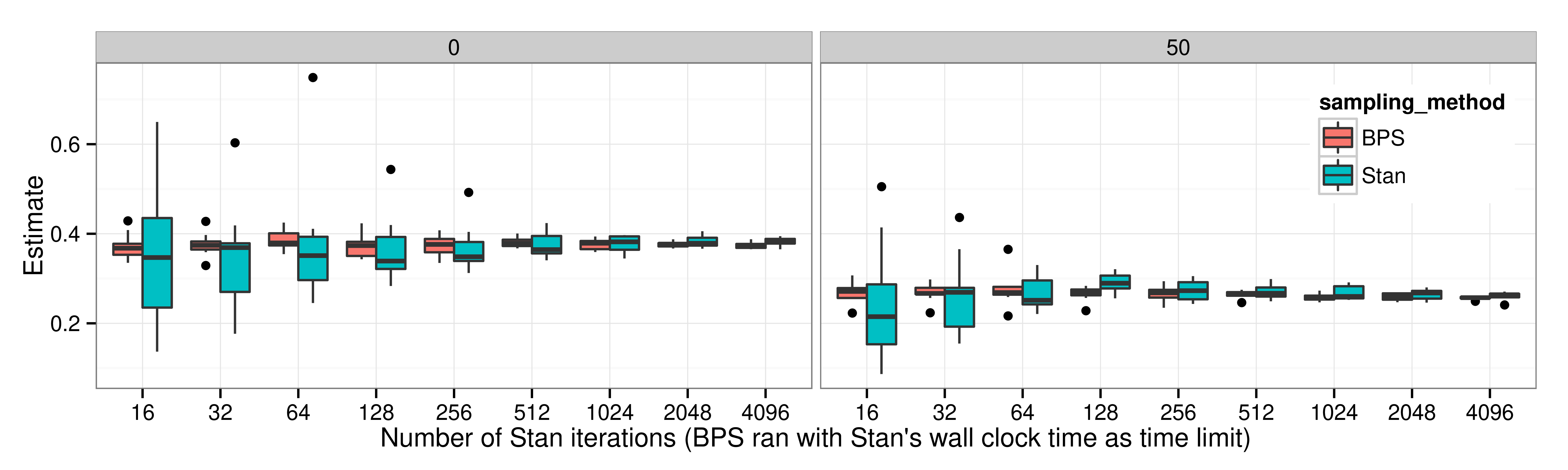
スパースな相互作用を持つマルコフ確率場モデル(d=10)
局所実装 O(d^1)
BPS で,sparsity を利用した実装をすると,HMC よりも「推定量の分散/時」が良い.
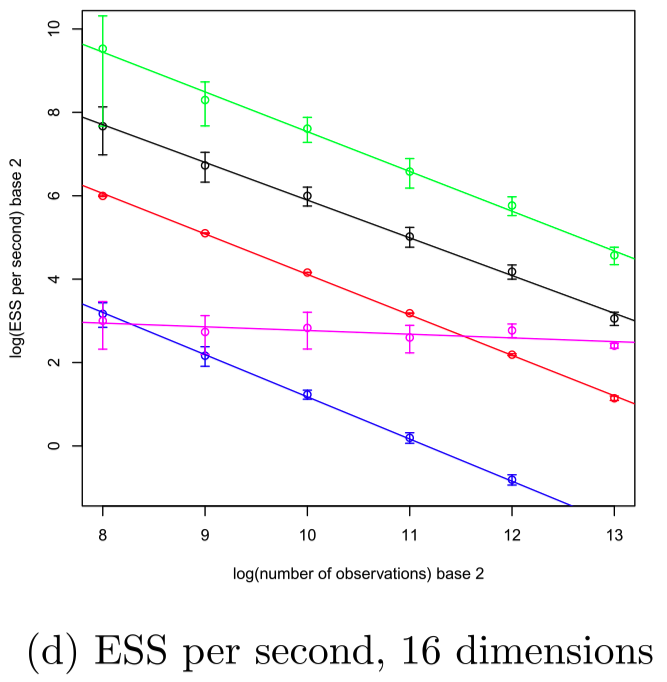
Stochastic Gradient O(n^0)
横軸:観測数 n,縦軸:有効サンプルサイズ.
ロジスティック回帰(d=16).
Zig-Zag で,control variate を用いると,データサイズ n に対して O(1) の性能
n\to\infty の極限で Langevin を越す.
2.1 BPS の大域的リフレッシュパラメータ \rho
2.3 BPS の拡散スケーリング極限(\gamma=1)
\textcolor{#0096FF}{Y_t^{(d)}} を U(x)=-\log\pi(x) について,d=10^2,10^3,10^4 でプロットしてみる:

2.4 先行研究:Zig-Zag v. BPS (Bierkens et al., 2022)

L(s,t)=2-\int^t_s\int^t_sK(u,v)\,dudv
K は動径運動量 R のカーネル K(s,t)=\operatorname{E}[R_sR_t]

dY_t=-\frac{\sigma^2(\rho)}{4}Y_t\,dt+\sigma(\rho)\,dB_t \sigma^2(\rho)=8\int^\infty_0e^{-\rho s}K(s,0)\,ds
2.5 拡散係数 \sigma の近似 → 漸近最適なハイパラ選択基準

2.6 FECMC という新星:\rho の排除
2.7 効率性比較:Zig-Zag v. BPS v. FECMC

100 次元 Gauss の U(x)=\|x\|^2 推定における有効サンプルサイズ (ESS).1000 回実行して推定.
2.8 主貢献1:FECMC のスケーリング極限は BPS と同じ形

dY_t^{\textcolor{#0096FF}{\text{B}}}=-\frac{\sigma^2_{\textcolor{#0096FF}{\text{B}}}(\rho)}{4}Y_t^{\textcolor{#0096FF}{\text{B}}}\,dt+\sigma_{\textcolor{#0096FF}{\text{B}}}(\rho)\,dB_t \sigma^2_{\textcolor{#0096FF}{\text{B}}}(\rho)=8\int^\infty_0e^{-\rho s}\operatorname{E}[R_0^{\textcolor{#0096FF}{\text{B}}}R_s^{\textcolor{#0096FF}{\text{B}}}]\,ds

dY_t^{\textcolor{#E95420}{\text{F}}}=-\frac{\sigma^2_{\textcolor{#E95420}{\text{F}}}(\rho)}{4}Y_t^{\textcolor{#E95420}{\text{F}}}\,dt+\sigma_{\textcolor{#E95420}{\text{F}}}(\rho)\,dB_t \sigma^2_{\textcolor{#E95420}{\text{F}}}(\rho)=8\int^\infty_0e^{-\rho s}\operatorname{E}[R_0^{\textcolor{#E95420}{\text{F}}}R_s^{\textcolor{#E95420}{\text{F}}}]\,ds
2.10 拡散係数の比較 FECMC v. BPS

2.12 実験との整合:FECMC v. BPS

3.3 実験結果:既存手法 v. 提案手法

3.4 非等方的 Gauss:既存手法 v. 提案手法

