変分推論2
EM アルゴリズム
2024-02-10
本稿では,\(K\)-平均アルゴリズム によるクラスタリングの考え方と問題点を,Python による実演を通じてみる.次稿 で,\(K\)-平均アルゴリズムの model-aware な一般化として EM アルゴリズム を説明し,その共通の問題点「初期値依存性」と「局所解へのトラップ」の数理的な理解を目指す.
A Blog Entry on Bayesian Computation by an Applied Mathematician
$$
$$
より図が見やすい PDF 版は こちら.
ハード \(K\)-平均法はモデルフリーのクラスタリングアルゴリズムである.Voronoi 分割による競争学習の一形態とも見れる.1
一方で原論文 (Lloyd, 1982) では,パルス符号変調 の文脈で,アナログ信号の量子化の方法として提案している.2
実際,\(K\)-平均法は(非可逆)データ圧縮にも用いられる.クラスター中心での画像の値と,それ以外では帰属先のクラスター番号のみを保存すれば良いというのである.このようなアプローチを ベクトル量子化 (vector quantization) という.3
ソフト \(K\)-平均法とは,このようなデータ点のクラスターへの一意な割り当てを,ソフトマックス関数を用いて軟化したアルゴリズムであり,多少アルゴリズムとしての振る舞いは改善するとされている.
\(N\) 個のデータ \(\{x_n\}_{n=1}^N\) の \(K\) クラスへの \(K\)-平均クラスタリングアルゴリズムは,ハードとソフトの二種類存在するが,いずれも \[ J:=\sum_{n=1}^N\sum_{k=1}^Kr_{nk}\|x_n-\mu_k\|^2 \] という損失関数の逐次最小化アルゴリズムとみなせる.
この見方は,EM アルゴリズム への一般化の軸となる.
しかしこの目的関数 \(J\) が非凸関数であることが,第 5 節で示す実験結果で見る通り,アルゴリズムに強い初期値依存性をもたらす.
これをクラスタがより互いに離れるように,クラス割り当て法を修正することで対策した 最遠点クラスタリング (Gonzalez, 1985) が提案された.これは k-means++ (Arthur and Vassilvitskii, 2007) とも呼ばれており,データ圧縮法として用いた場合は復元誤差が \(O(\log K)\) でバウンド出来ることも示されている.
実際のコードとデータを用いて \(K\)-平均法を解説する.
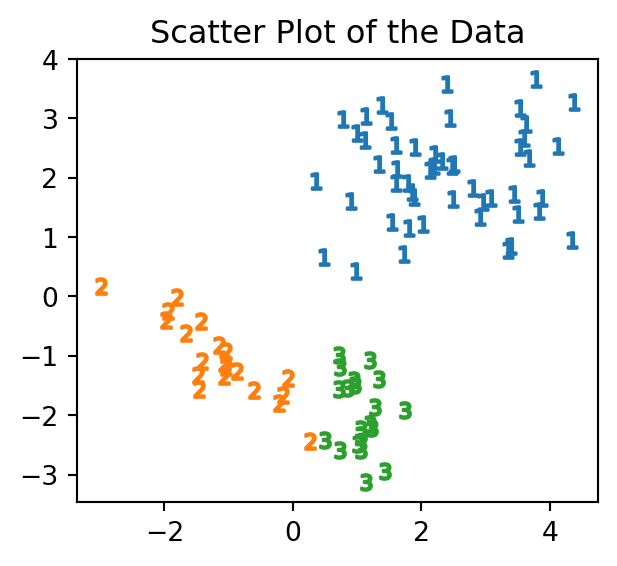
まずは,解説にために作られた,次のような3つのクラスタからなる2次元のデータを考え,これの正しいクラスタリングを目指す.
head \(K\)-means algorithm はデータ \(\{x^{(n)}\}_{n=1}^N\subset\mathbb{R}^I\) とクラスタ数 \(K\in\mathbb{N}^+\),そして初期クラスター中心 \((m^{(k)})_{k=1}^K\in(\mathbb{R}^I)^K\) の3組をパラメータに持つ.
soft \(K\)-means algorithm 3.1 はさらに硬度パラメータ \(\beta\in\mathbb{R}_+\) を持つ.
numpy の提供する行列積を利用して,これを Python により実装した例を以下に示す.ソフト \(K\)-平均法の実装と対比できるように,負担率を通じた実装を意識した例である.
アノテーションを付してあるので,該当箇所(右端の丸囲み数字)をクリックすることで適宜解説が読めるようになっている.
def hkmeans_2d(data, K, init, max_iter=100):
"""
2次元データに対するハード K-平均法の実装例.
Parameters:
- data: (N,2)-numpy.ndarray
- K: int クラスター数
- init: (2,K)-numpy.ndarray 初期値
Returns:
- clusters: (N,)-numpy.ndarray クラスター番号
"""
N = data.shape[0]
I = data.shape[1]
m = init
r = np.zeros((K, N), dtype=float)
for _ in range(max_iter):
# Assignment Step
for i in range(N):
distances = np.array([d(data[i], m[:,k]) for k in range(K)])
k_hat = np.argmin(distances)
r[:,i] = 0
r[k_hat,i] = 1
# Update Step
new_m = np.zeros_like(m, dtype=float)
numerator = np.dot(r, data)
denominator = np.sum(r, axis=1)
for k in range(K):
if denominator[k] > 0:
new_m[:,k] = numerator[k] / denominator[k]
else:
new_m[:,k] = m[:,k]
if np.allclose(m, new_m):
break
m = new_m
return np.argmax(r, axis=0)dtype=float の理由は後述.
distances 変数は (K,)-numpy.ndarray になる.すなわち,第 \(k\) 成分が,第 \(k\) クラスター中心との距離となっているようなベクトルである.ただし,d は Euclid 距離を計算する関数として定義済みとした.
dtype=float と指定しないと,初め引数 init が整数のみで構成されていた場合に,Python の自動型付機能が int 型だと判定し,クラスター中心 m の値が整数に限られてしまう.すると,アルゴリズムがすぐに手頃な格子点に収束してしまう.
numpy の行列積を計算する関数 np.dot を使用している.更新式 \[
m^{(k)}\gets\frac{\sum_{n=1}^Nr^{(n)}_kx^{(n)}}{\sum_{n=1}^Nr^{(n)}_k}
\] の分子を行列積と見たのである.
r の行和として得られる.
hat_k の列をそのまま返せば良いが,soft \(K\)-means アルゴリズムにも通じる形で実装した.
次の2つの初期値を与えてみる. \[ m_1:=\begin{pmatrix}4\\0\end{pmatrix},\quad m_2:=\begin{pmatrix}1\\4\end{pmatrix},\quad m_3=\begin{pmatrix}-1\\1\end{pmatrix}, \] と,\(m_2,m_3\) は変えずに \(m_1\) の \(y\)-座標を \(1\) だけ下げたもの \[ m_1':=\begin{pmatrix}4\\-1\end{pmatrix} \] とを初期値として与えてみる.
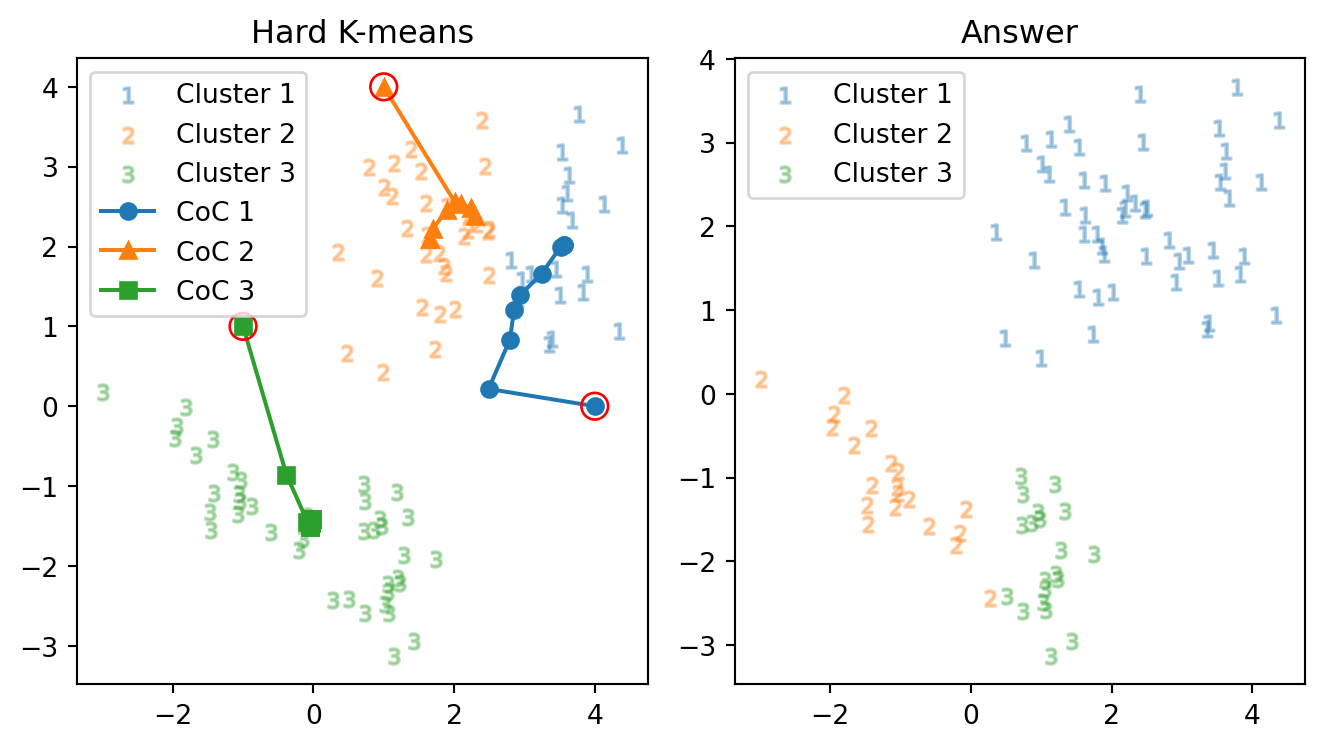
正解数: 51 正解率: 56.7 % 反復数: 9 回別の初期値を与えてみる(右下の点 \(m_1\) を \(1\) だけ下に下げただけ): \[ \begin{pmatrix}4\\0\end{pmatrix}=m_1\mapsto m_1':=\begin{pmatrix}4\\-1\end{pmatrix} \]
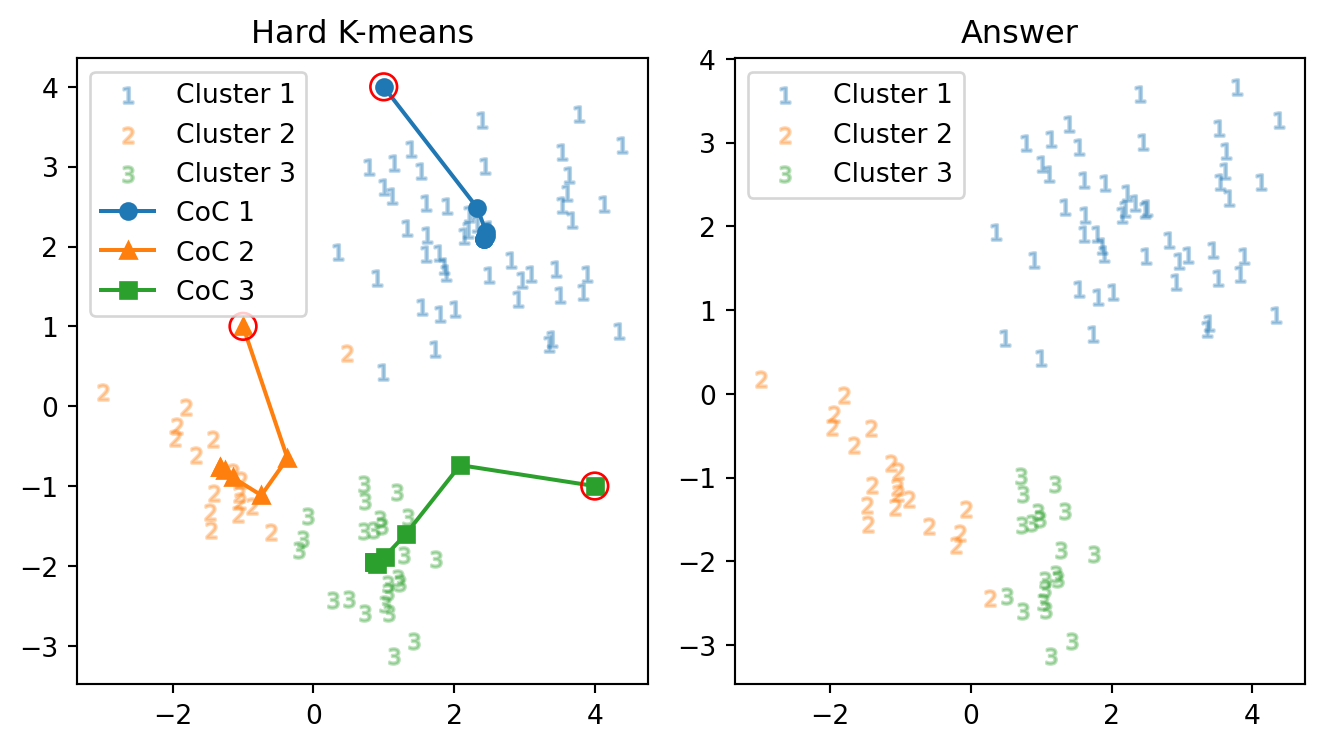
正解数: 85 正解率: 94.4 % 反復数: 7 回結果が全く変わり,\((m_1',m_2,m_3)\) を与えた方が,大きく正解に近づいている.具体的には,右下の初期値 \(m_1\) は右上の島に行くが,\(m_1'\) は左下の島に行ってくれる.
ハード \(K\)-平均アルゴリズムは初期値に敏感である ことがよく分かる.
直前の結果2ではクラスター2と3の境界線で4つのミスを犯しており,これを修正できないか試したい.
そこで,答えに近いように, \[ m_1\gets\begin{pmatrix}2.5\\2\end{pmatrix},\;\; m_2\gets\begin{pmatrix}-1\\-1\end{pmatrix},\;\; m_3\gets\begin{pmatrix}1\\-2\end{pmatrix}, \] を初期値として与えてみて,正答率の変化を観察する.
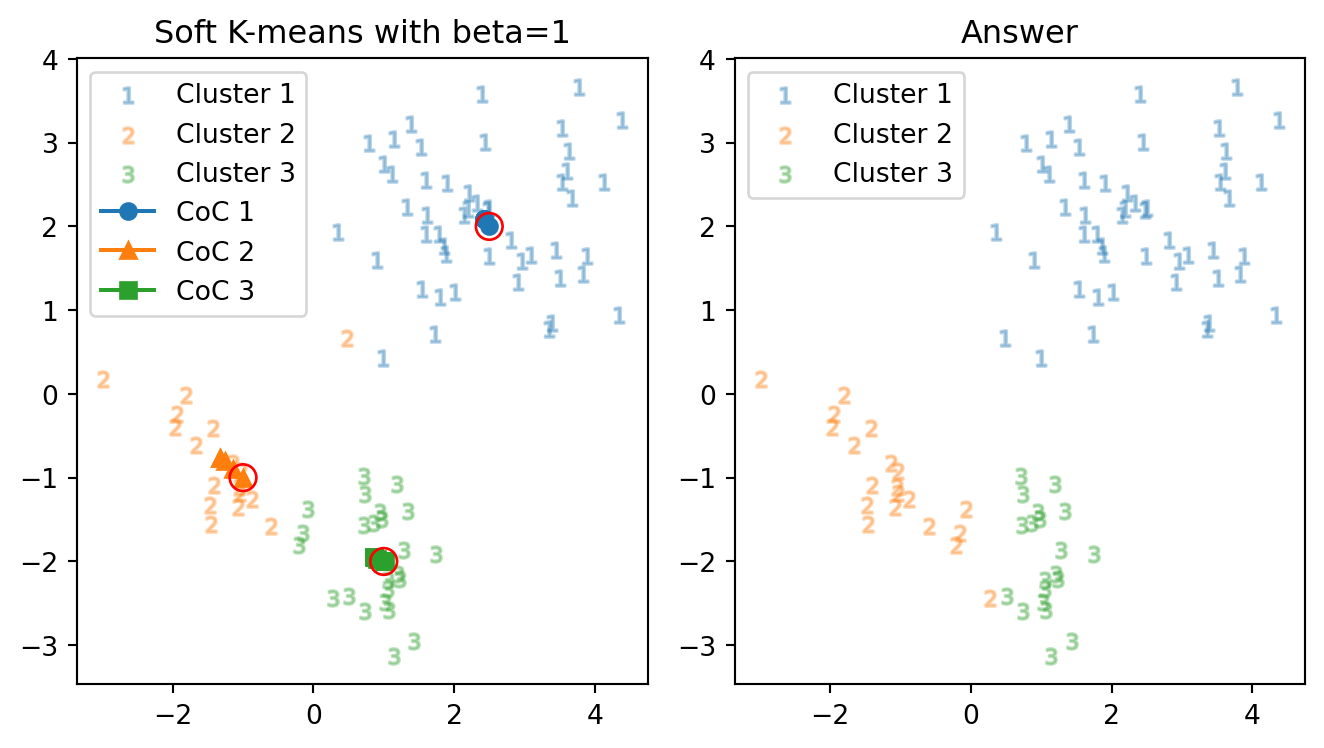
正解数: 85 正解率: 94.4 % 反復数: 5 回もはや初期値から殆ど動いていないが,目標のクラスター3に分類された3つの点が,相変わらず3のままであり,加えてクラスター2の中心がこれらから逃げているようにも見えるので,クラスター2の初期値をよりクラスター3に近いように誘導し,クラスター3の中心をより右側から開始する:
\[ m_2:\begin{pmatrix}-1\\-1\end{pmatrix}\mapsto\begin{pmatrix}0\\-2\end{pmatrix}\;\; m_3:\begin{pmatrix}1\\-2\end{pmatrix}\mapsto\begin{pmatrix}2\\-2\end{pmatrix} \]
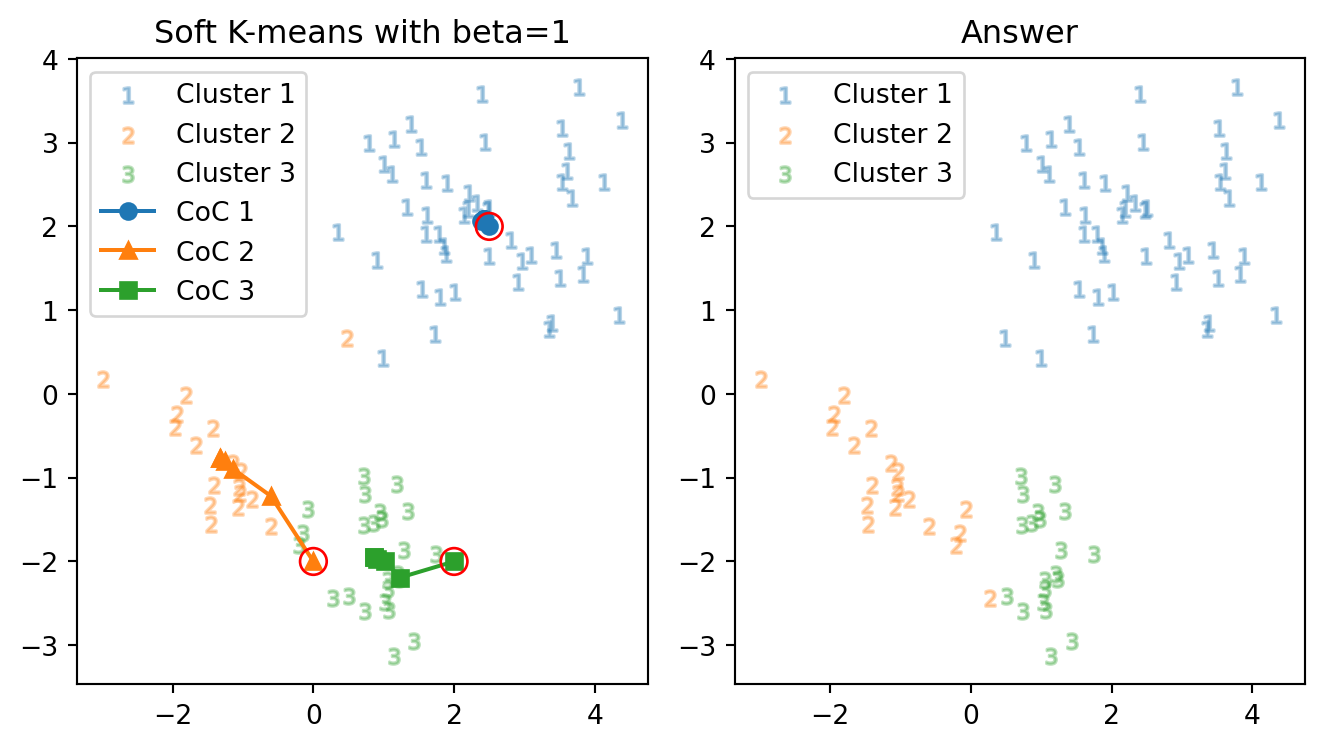
正解数: 85 正解率: 94.4 % 反復数: 6 回こんなに誘導をしても,正しく分類してくれない.
実は,以上2つの初期値では,最終的に3つのクラスター中心は同じ値に収束している.よって,これ以上どのように初期値を変更しても,正答率は上がらないシナリオが考えられる.
以上の観察から,ハード \(K\)-平均法はある種の 局所解に収束する ようなアルゴリズムであると考えられる.
ハード \(K\)-平均法2では,負担率 \[ r_{kn}\gets\delta_{k}(\operatorname*{argmax}_{i\in[k]}d(m_i,x_n)) \] は \(0,1\) のいずれかの値しか取らなかった.この振る舞いを, \[ \sigma(z;e)_i:=\frac{e^{z_i}}{\sum_{j=1}^Ke^{e_j}}\quad(i\in[K]) \] で定まる ソフトマックス関数 \(\sigma:\mathbb{R}^K\to(0,1)^K\) を用いて,「軟化」する.
ここでは,\(\beta\ge0\) として, \[ \sigma(z;e^{-\beta})_i=\frac{e^{-\beta z_i}}{\sum_{j=1}^Ke^{-\beta e_j}} \] の形で用い,\(\operatorname*{argmax}\) の代わりに \[ \begin{align*} r_{kn}&\gets\sigma(d(-,x_n)^2\circ m;e^{-\beta})_k\\ &=\frac{e^{-\beta d(m_k,x_n)^2}}{\sum_{j=1}^K e^{-\beta d(m_j,x_n)^2}} \end{align*} \] とする.ただし,\(d\) は \(\mathbb{R}^2\) 上の Euclid 距離とした.
\(\beta\) は 硬度 (stiffness) または逆温度と呼ぶ.4 \(\sigma:=\beta^{-1/2}\) は距離の次元を持つ.
\(\beta=0\) のときは温度が無限大の場合にあたり,常に負担率は一様になる.絶対零度に当たる \(\beta\to\infty\) の極限が hard \(K\)-means アルゴリズムに相当する.
逆温度 \(\beta\) を連続的に変化させることで,クラスタ数に分岐が起こる,ある種の相転移現象を見ることができる.5
実装は例えば hard \(K\)-means アルゴリズム2から,負担率計算の部分のみを変更すれば良い:
for i in range(N):
distances = np.array([d(data[i], m[:,k]) for k in range(K)])
denominator_ = np.sum(np.exp(-beta * distances))
r[:,i] = np.exp(-beta * distances) / denominator_distances に格納している.
denominator_ に格納している.
denominator_ を用いてデータ \(x_i\) の負担率 \((r_{ki})_{k=1}^K\) を計算し,\((K,N)\)-行列 r の各列に格納している.
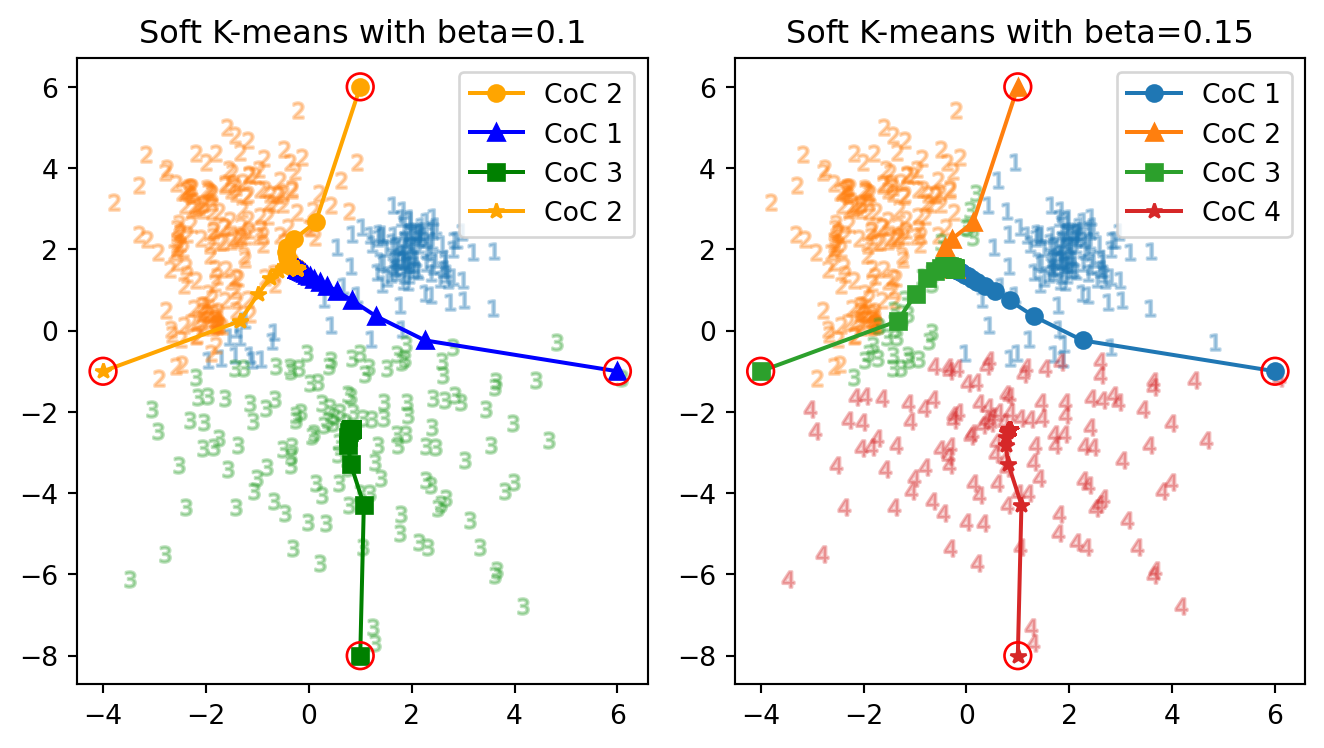
逆温度をはじめに \(\beta=0.3\) としてみる.図 1 と全く同様な初期値 \[ m_1:=\begin{pmatrix}4\\0\end{pmatrix},\quad m_2:=\begin{pmatrix}1\\4\end{pmatrix},\quad m_3=\begin{pmatrix}-1\\1\end{pmatrix}, \] を与えてみると,次の通りの結果を得る:
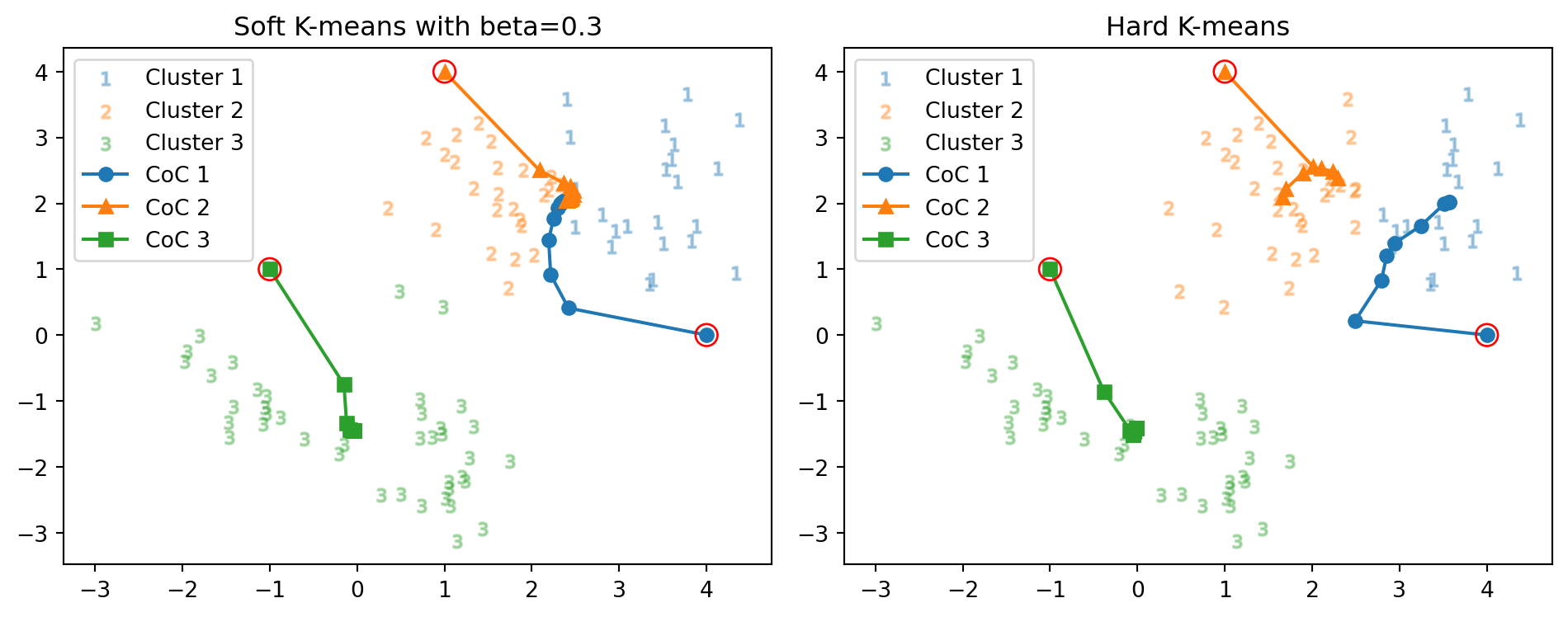
正解数: 44 vs. 51 正解率: 48.9 % vs. 56.7 % 反復数: 28 回 vs. 9 回クラスターの境界が変化しており,正解率は悪化している.さらに,反復数が9回であったところから,3倍に増えている(28回).
また,右上の2つのクラスター中心の収束先は,微妙にずれているが ほとんど一致している 点も注目に値する.
図 2 で与えた初期値 \((m_1',m_2,m_3)\) も与えてみる.
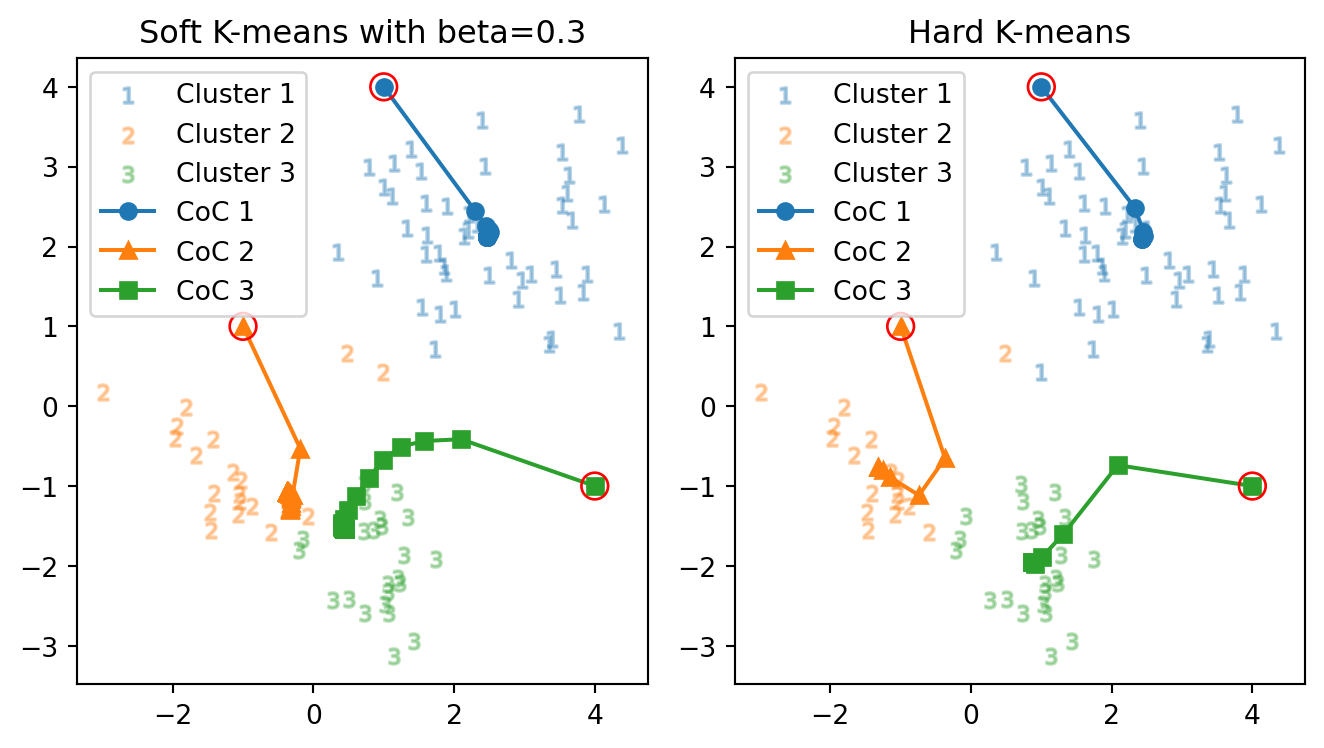
正解数: 85 vs. 85 正解率: 94.4 % vs. 94.4 % 反復数: 59 回 vs. 7 回クラスター境界と正答率は変わらないが,反復数がやはり7回から大きく増えている.
結果はやはり 図 3 とは大きく異なっており,ハード \(K\)-平均法で観察された初期値鋭敏性が,変わらず残っている.
加えてこの場合も 図 3 のクラスター1と2と同様に,クラスター2と3の中心がほぼ一致している.
\(\beta=0.3\) の場合のソフト \(K\)-平均法は,この例では クラスター中心が融合する傾向にある ようである.
一般に,\(\beta\) が小さく,温度が大きいほど,エネルギーランドスケープに極小点が少なくなり,クラスターは同じ場所へ収束しやすくなると予想される.
初期値を直前で用いた \[ m_1\gets\begin{pmatrix}4\\-1\end{pmatrix},\quad m_2\gets\begin{pmatrix}1\\4\end{pmatrix},\quad m_3\gets\begin{pmatrix}-1\\1\end{pmatrix}, \] で固定とし,さらに温度を上げて,逆温度を \(\beta=0.1\) としてみる.
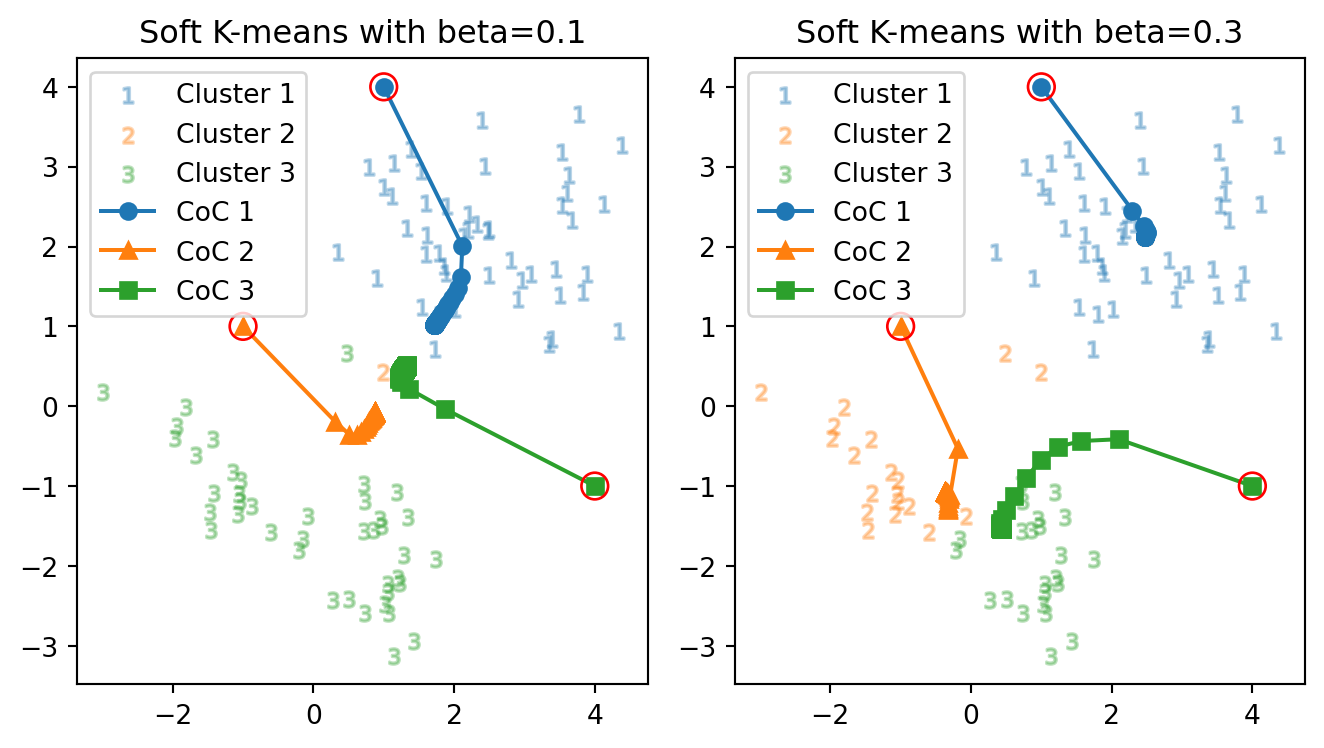
正解数: 68 vs. 85 正解率: 75.6 % vs. 94.4 % 反復数: 101 回 vs. 59 回反復数はさらに増加し,全てがほとんど同じクラスターに属する結果となってしまった.
温度が大変に高い状態では,全てが乱雑で,3つのクラスターが一様・公平に負担率を持つようになった.そのため,第一歩からほとんど全体の中心へと移動し,反復数が減る.
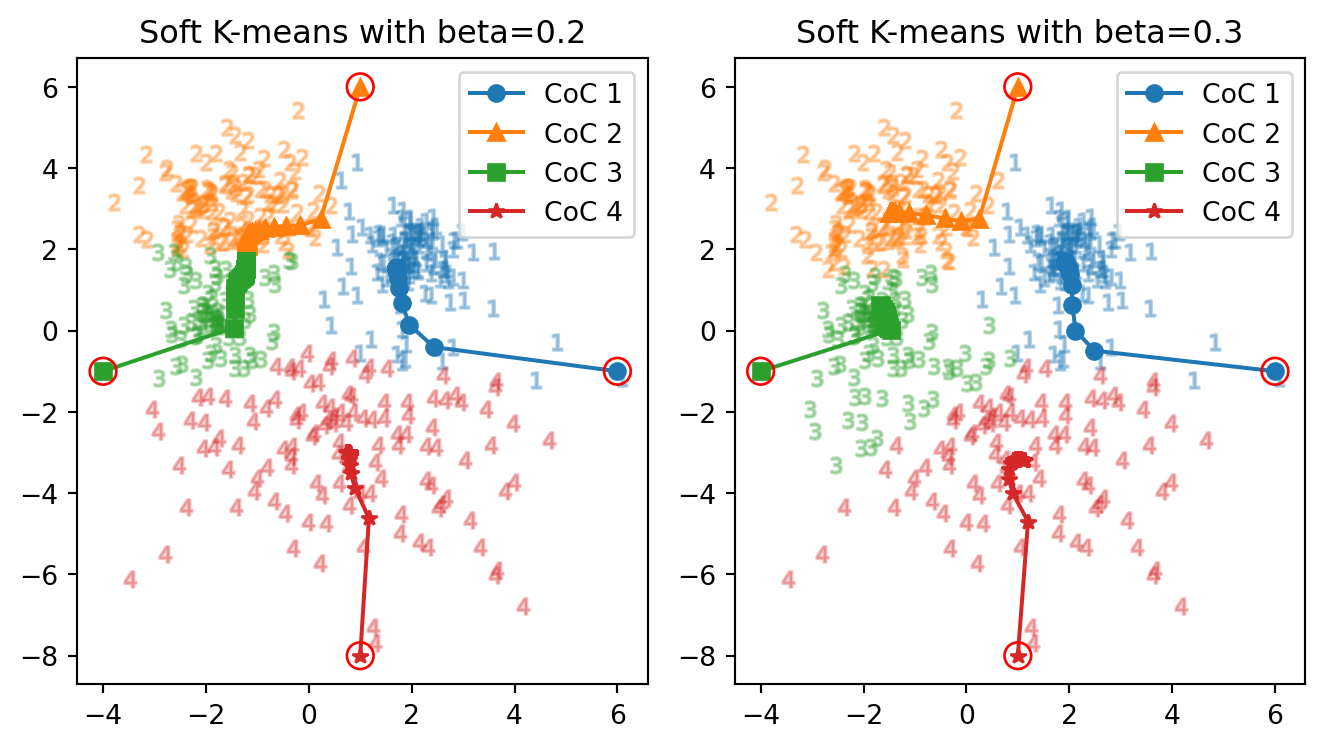
次に,温度を少し下げて,逆温度を \(\beta=2\) としてみる.
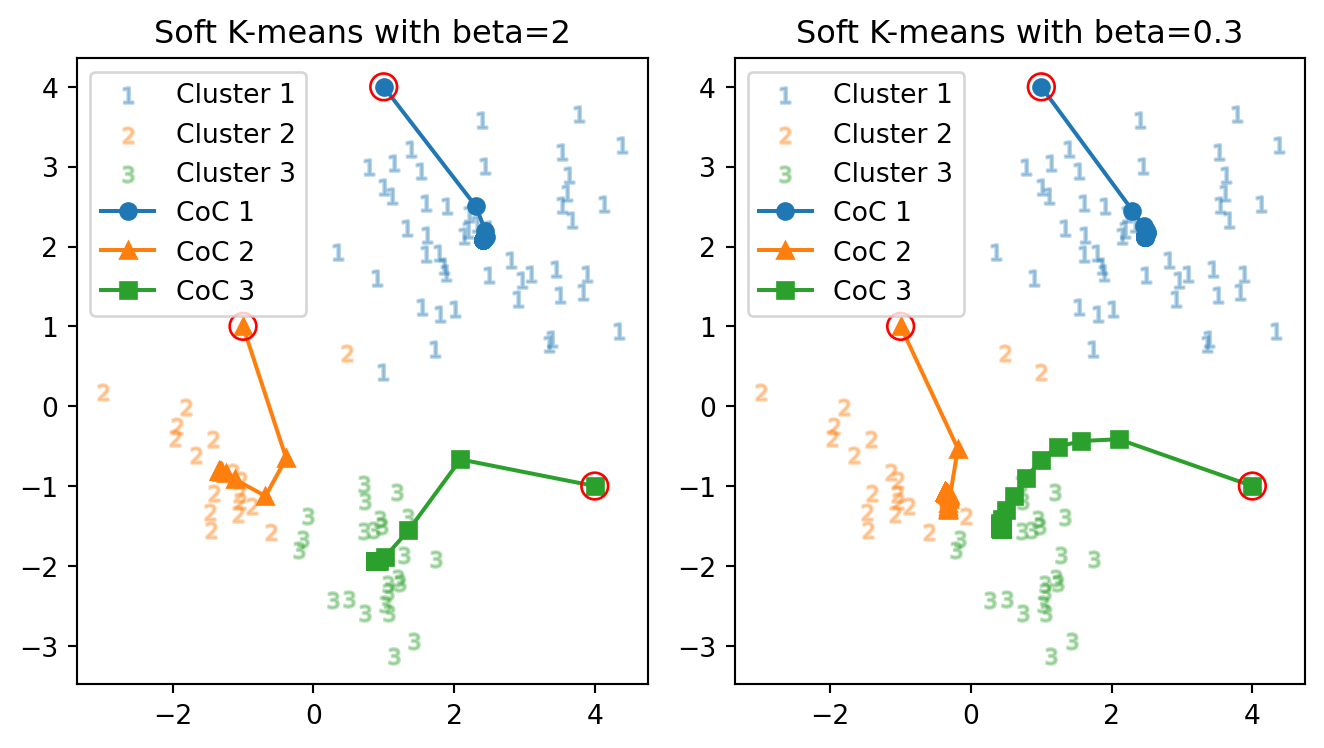
正解数: 85 vs. 85 正解率: 94.4 % vs. 94.4 % 反復数: 17 回 vs. 59 回初めて soft \(K\)-means アルゴリズムを用いた場合で,3つのクラスター中心がはっきりと別れた.反復回数は,\(\beta=0.3\) の場合と比べればやはり落ち着いている.
しかし,正解率は head \(K\)-means の場合( 図 2 など)と全く同じである.実は,最終的なクラスター中心も 図 2 の最終的なクラスター中心とほとんど同じになっている.
以上より,ソフト \(K\)-平均法は温度を上げるほどクラスター数が少なくなり,温度を下げるほどクラスター数は上がり,十分に温度を下げるとハード \(K\)-平均法に挙動が似通う.
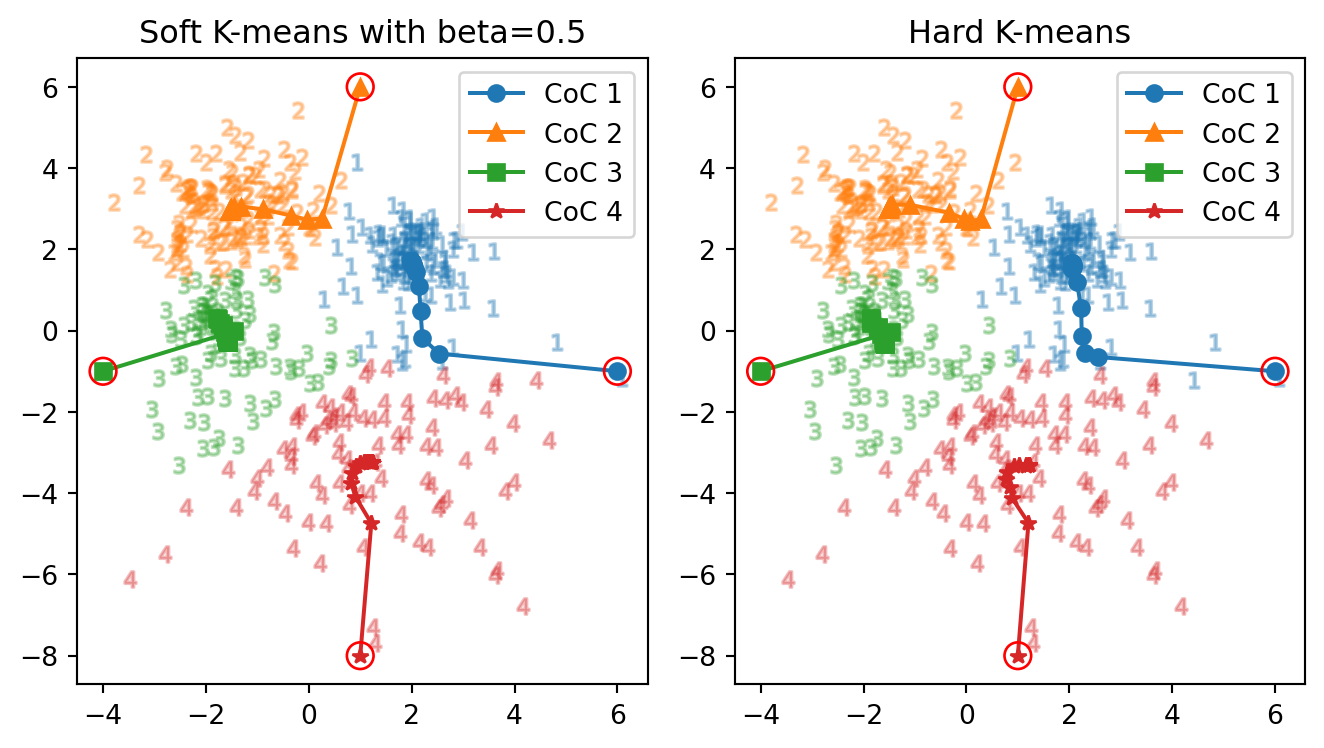
\(\beta=0.2\) ではクラスターが2つに縮退し,\(\beta=1\) では hard \(K\)-means アルゴリズムの結果とほとんど変わらなくなる.その中間では次のように挙動が変わる:
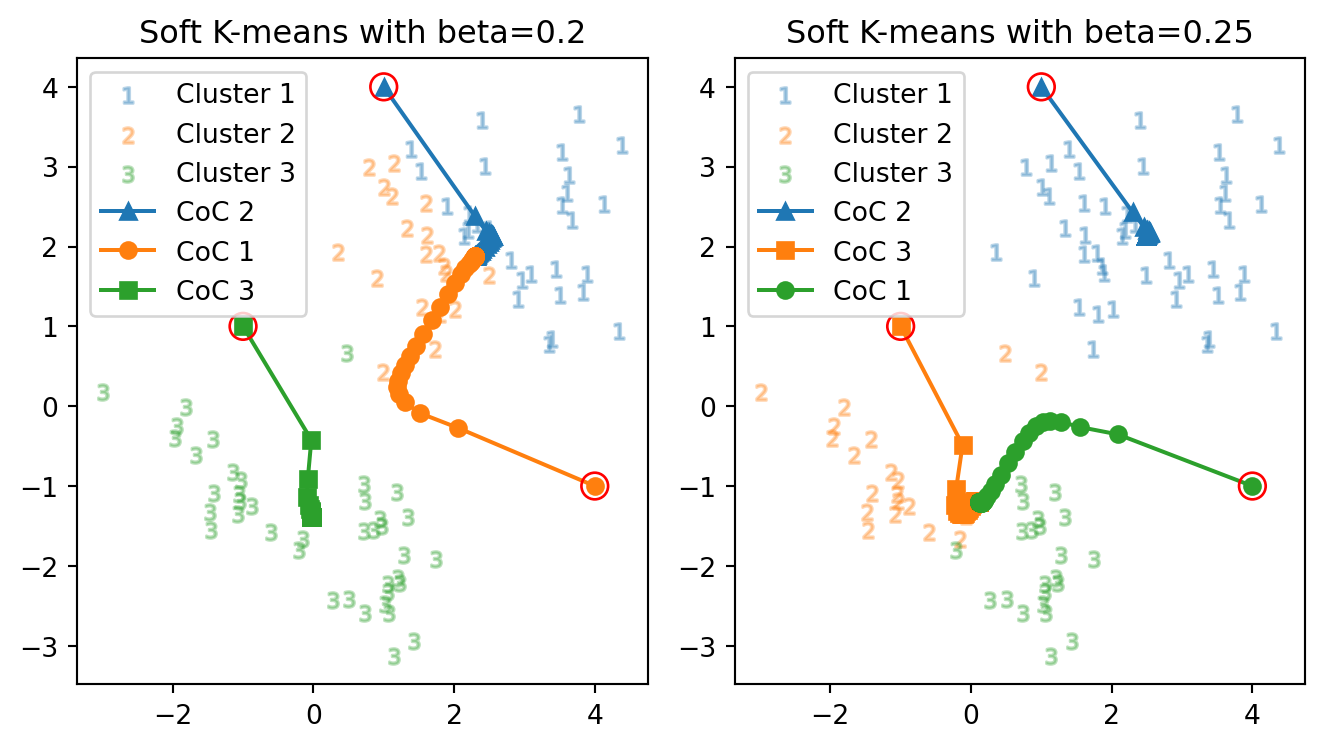
正解数: 50 vs. 86
正解率: 55.6 % vs. 95.6 %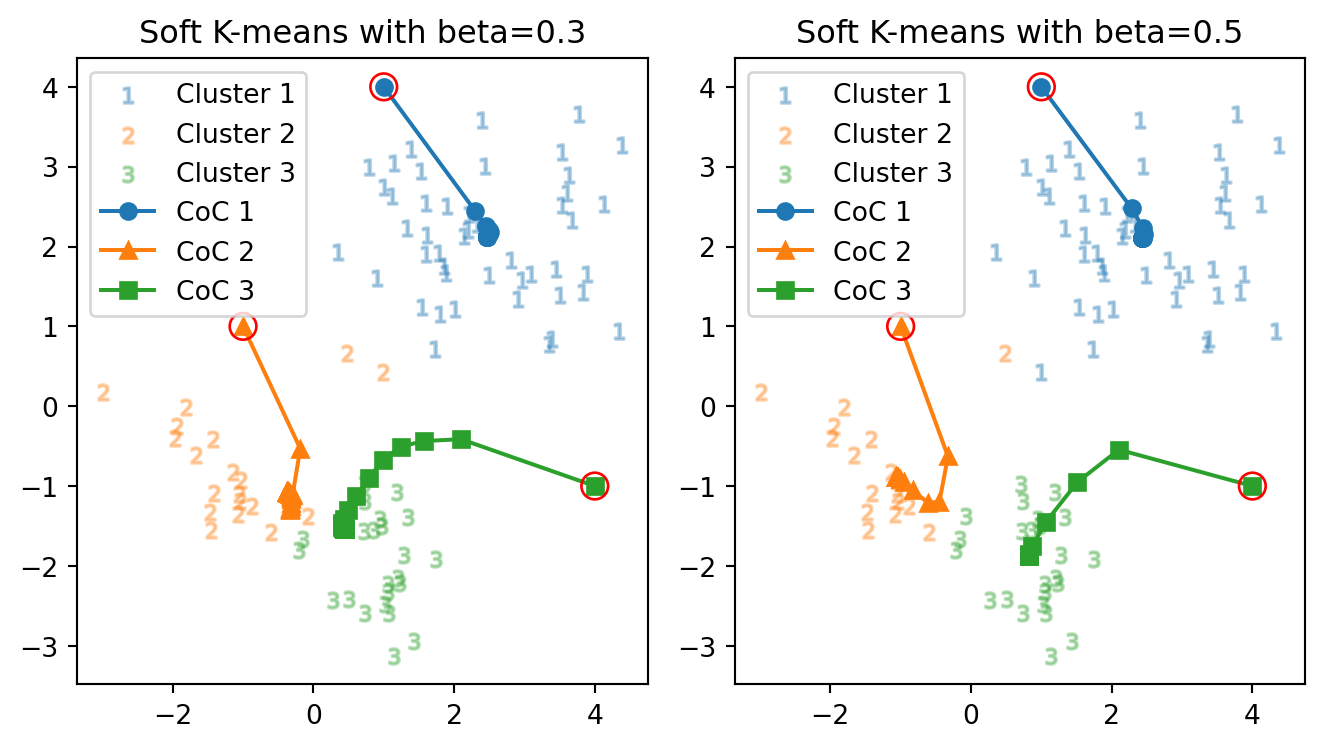
正解数: 85 vs. 85
正解率: 94.4 % vs. 94.4 %やはり,温度が高い場合はクラスター中心が合流・融合してしまいやすいが,冷却することでクラスター数は大きい状態で安定する,と言えるだろう.
今まで使っていたデータ1.3はクラスターのオーバーラップはなかったため,いわば優しいデータであった.ここからはよりデータ生成過程が複雑なデータを用いて,ソフト \(K\)-平均法の挙動を観察する.
今度は,次の4クラスのデータを用いる.
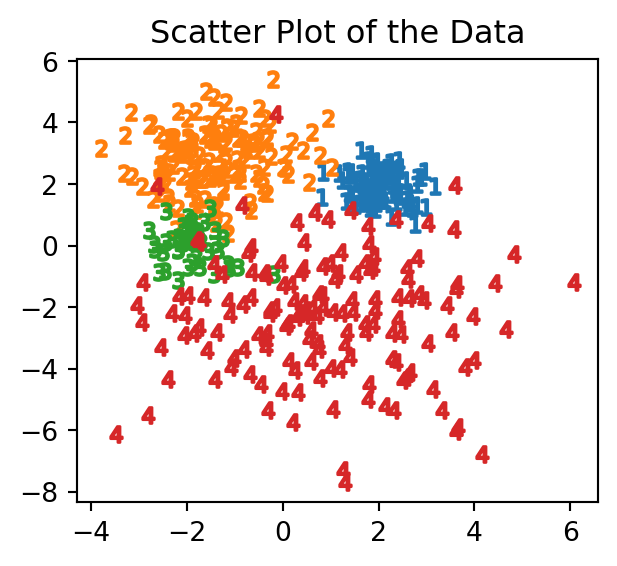
実は,これは4つの Gauss 分布から生成されたデータである.
正解数: 377 vs. 366 正解率: 83.8 % vs. 81.3 % 反復数: 49 回 vs. 62 回
正解数: 386 vs. 375 正解率: 85.8 % vs. 83.3 % 反復数: 101 回 vs. 70 回
正解数: 378 vs. 378 正解率: 84.0 % vs. 84.0 % 反復数: 39 回 vs. 14 回こうしてソフト \(K\)-平均法とハード \(K\)-平均法の性質は分かった.主に
の問題が未解決であり,恣意性が残る.
これを,ベイズ混合モデリングにより解決する方法を次稿で紹介する:
Lloyd は 1957 年には発表していたが,論文の形になったのが 1982 である.\(K\)-means という名前の初出は (MacQueen, 1967) とされている.↩︎
(MacKay, 2003, p. 284),(Bishop, 2006, p. 429),(Murphy, 2022, p. 722) 21.3.3節.クラスター中心は 符号表ベクトル または 代表ベクトル (code-book vector) という.↩︎
stiffness の用語は (MacKay, 2003, p. 289) から.実は各クラスターに Gauss モデルを置いた場合の分散 \(\sigma^2\) に対して,\(\beta=\frac{1}{2\sigma^2}\) の関係がある.次稿 参照.↩︎

