1 背景:PDMP とその特殊性
A Blog Entry on Bayesian Computation by an Applied Mathematician
$$
$$
1.1 モンテカルロ法小史
(1953〜)
(1978〜)
(2008〜)
1.2 Piecewise Deterministic Markov Process

直感:SDE より ODE の離散化の方が「扱いやすい」
1.3 HMC v. PDMP:高次元ではほぼ同じ.離散化が違うのみ
PDMP サンプラーは ODE Solver なしで Hamiltonian flow を近似できる
symplectic integrator で離散化
O(d^{1.25}) の計算複雑性

大量の Poisson 点測度 で近似
通常時は O(d^{1.5}) の計算複雑性
1.4 PDMP は killer application での爆発力がすごい
スパースな相互作用を持つマルコフ確率場モデル(d=10)
局所実装 O(d^1)
BPS で,sparsity を利用した実装をすると,HMC よりも「推定量の分散/時」が良い.
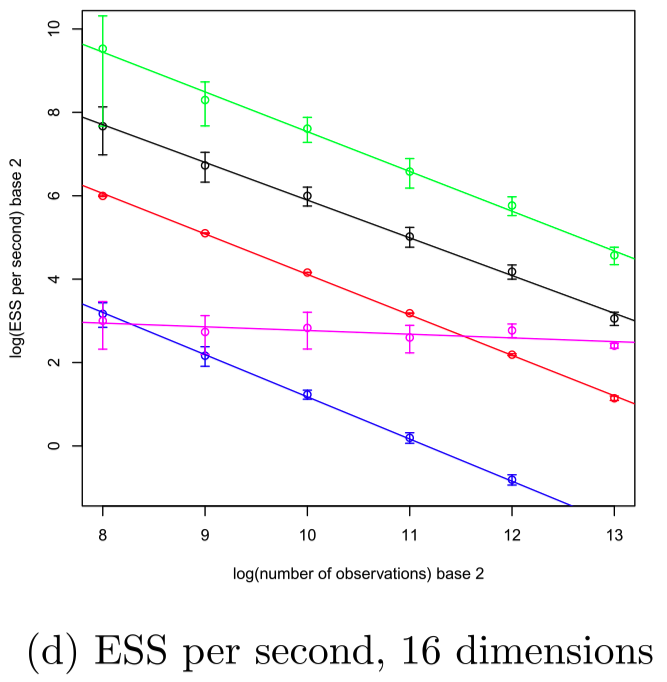
Stochastic Gradient O(n^0)
横軸:観測数 n,縦軸:有効サンプルサイズ.
ロジスティック回帰(d=16).
Zig-Zag で,control variate を用いると,データサイズ n に対して O(1) の性能
n\to\infty の極限で Langevin を越す.
2 等速直線ダイナミクス
でどこまで行けるか?
HMC は Metropolis–Hastings 界のトップ.PDMP のトップは?
2.1 BPS の大域的リフレッシュパラメータ \rho
2.2 BPS \textcolor{#0096FF}{\{X_t\}} のスケーリング解析
定常分布 X_0\sim\pi から実行したときの低次元射影 \textcolor{#0096FF}{Y_t^{(d)}}:=\frac{U(\textcolor{#0096FF}{X_{d^\gamma t}})-\operatorname{E}_\pi[U(\textcolor{#0096FF}{X_{d^\gamma t}})]}{\sqrt{\operatorname{Var}_\pi[U(\textcolor{#0096FF}{X_{d^\gamma t}})]}},\quad U:\mathbb{R}^d\to\mathbb{R}\text{: 射影},\;\textcolor{#0096FF}{\gamma}>0 の,d\to\infty の極限での挙動を解析する.
2.3 BPS の拡散スケーリング極限(\gamma=1)
\textcolor{#0096FF}{Y_t^{(d)}} を U(x)=-\log\pi(x) について,d=10^2,10^3,10^4 でプロットしてみる:

2.4 先行研究:Zig-Zag v. BPS (Bierkens et al., 2022)

L(s,t)=2-\int^t_s\int^t_sK(u,v)\,dudv
K は動径運動量 R のカーネル K(s,t)=\operatorname{E}[R_sR_t]

dY_t=-\frac{\sigma^2(\rho)}{4}Y_t\,dt+\sigma(\rho)\,dB_t \sigma^2(\rho)=8\int^\infty_0e^{-\rho s}K(s,0)\,ds
2.5 拡散係数 \sigma の近似 → 漸近最適なハイパラ選択基準

2.6 FECMC という新星:\rho の排除
2.7 効率性比較:Zig-Zag v. BPS v. FECMC

2.8 主貢献1:FECMC のスケーリング極限は BPS と同じ形

dY_t^{\textcolor{#0096FF}{\text{B}}}=-\frac{\sigma^2_{\textcolor{#0096FF}{\text{B}}}(\rho)}{4}Y_t^{\textcolor{#0096FF}{\text{B}}}\,dt+\sigma_{\textcolor{#0096FF}{\text{B}}}(\rho)\,dB_t \sigma^2_{\textcolor{#0096FF}{\text{B}}}(\rho)=8\int^\infty_0e^{-\rho s}\operatorname{E}[R_0^{\textcolor{#0096FF}{\text{B}}}R_s^{\textcolor{#0096FF}{\text{B}}}]\,ds

dY_t^{\textcolor{#E95420}{\text{F}}}=-\frac{\sigma^2_{\textcolor{#E95420}{\text{F}}}(\rho)}{4}Y_t^{\textcolor{#E95420}{\text{F}}}\,dt+\sigma_{\textcolor{#E95420}{\text{F}}}(\rho)\,dB_t \sigma^2_{\textcolor{#E95420}{\text{F}}}(\rho)=8\int^\infty_0e^{-\rho s}\operatorname{E}[R_0^{\textcolor{#E95420}{\text{F}}}R_s^{\textcolor{#E95420}{\text{F}}}]\,ds
2.9 主貢献2:拡散係数の解析的表示
\begin{align*} \underbrace{\frac{\sigma^2(0)}{4}=2\int^\infty_0\operatorname{E}[R_0R_t]\,dt}_{\text{Green--Kubo 公式}}=\operatorname{E}\biggl[R_0\underbrace{\int^\infty_0\operatorname{E}[R_t|R_0]\,dt}_{=:f(R_0)}\biggr]=\operatorname{E}[R_0f(R_0)] \end{align*} この関数 f は,動径運動量 R の生成作用素 L に関して次を満たす: -Lf(x)=x\quad\text{(Poisson 方程式)}
2.10 拡散係数の比較 FECMC v. BPS

2.11 拡散係数 \sigma ≒ モンテカルロ漸近分散 ≒ ESS
【説明】 モンテカルロ推定量(=PDMP \textcolor{#0096FF}{\{X_t\}} の時間平均) \widehat{h}_T:=\frac{1}{T}\int^T_0U(\textcolor{#0096FF}{X_s})\,ds の漸近分散比は,高次元極限では次で与えられる: \lim_{T\to\infty}\lim_{d\to\infty}T\frac{\operatorname{Var}[\widehat{h}_{\textcolor{#E95420}{d}T}]}{\operatorname{Var}_\pi[U(X)]}=\frac{8}{\sigma^2}\approx2.50\cdots. この逆数が単位時間あたりの有効サンプルサイズである.
2.12 実験との整合:FECMC v. BPS

3 応用:PDMP の収束判定
実際の分布 \pi では \sigma^2 の値はわからない.これを推定するのが収束判定.
PDMP には補助変数 \textcolor{#E95420}{\{V_t\}} があり,これを利用することでモンテカルロ漸近分散の推定量の分散を改善することができる.
3.1 漸近分散推定における fast proxy
推定対象 U(x)=-\log\pi(x) の代わりに,その時間微分 \textcolor{#E95420}{g(x,\dot{x})}:=\dot{U} を考える \text{例:}\quad U(x)=\frac{\|x\|^2}{2}\quad\text{のときは}\quad \textcolor{#E95420}{g(x,v)}=\langle x,v\rangle.
2種類のモンテカルロ推定量を考える:
\widehat{h}_T:=\frac{1}{T}\int^T_0U(X_s)\,ds,\quad \textcolor{#E95420}{\widehat{g}_T}:=\frac{1}{T}\int^T_0\textcolor{#E95420}{g(X_t,V_t)}\,dt.
→ \textcolor{#E95420}{d} が大きいほど,\sigma^2 の値を知るのに,\textcolor{#E95420}{\widehat{g}_T} を使った方が有利?
3.2 漸近分散推定量の例 Batch Means Estimator
batch size b>0 を設定し,その小区間平均 h_i:=\frac{1}{b}\int^{ib}_{(i-1)b}U(X_t)\,dt の全体 h_1,h_2,\cdots,h_B の不偏分散の b 倍を batch means 推定量という: \textcolor{#0096FF}{\frac{b}{B-1}\sum_{i=1}^B(h_i-\overline{h})}\xrightarrow[\text{適切な極限}]{T\to\infty}\lim_{d\to\infty}\lim_{T\to\infty}T\frac{\operatorname{Var}[\widehat{h}_{\textcolor{#E95420}{d}T}]}{\operatorname{Var}_\pi[U(X)]}=\frac{8}{\sigma^2}\;\;(\textbf{一致性}). MSE の意味で最適な b>0 が判っている (Liu et al., 2022).
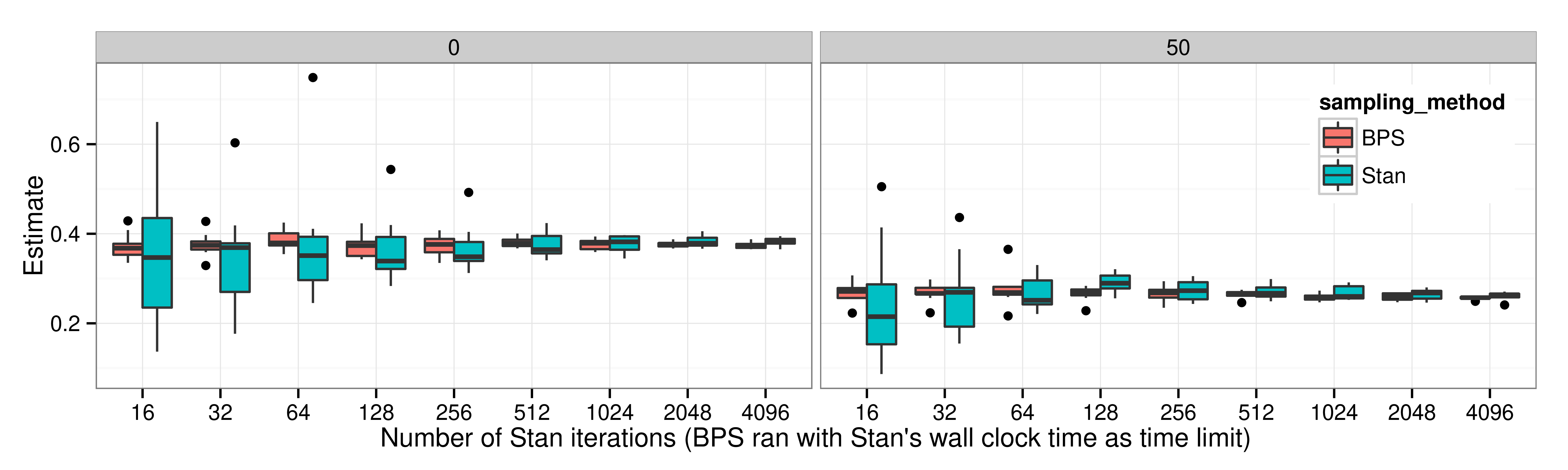
3.3 実験結果:既存手法 v. 提案手法

3.4 非等方的 Gauss:既存手法 v. 提案手法
