A Blog Entry on Bayesian Computation by an Applied Mathematician
$$
$$
- 動的型付けであるが,明示的な型付けを型注釈の記法でコードに追加できる.
- 多重ディスパッチによって動的にメソッド呼び出しが行われる.Julia で method というと,この多重ディスパッチの方を意味する.
- 一般的な OOP ではなく,オブジェクトに関数を所属させる意味での method は存在せず,型の継承も存在せず,階層関係があるのみである.
- 全ての型は supertype をもち,Julia の Type はこの親子関係について木構造をなす.
- root は
Anyである.
- 多重ディスパッチでは,より葉に近い方から match する.
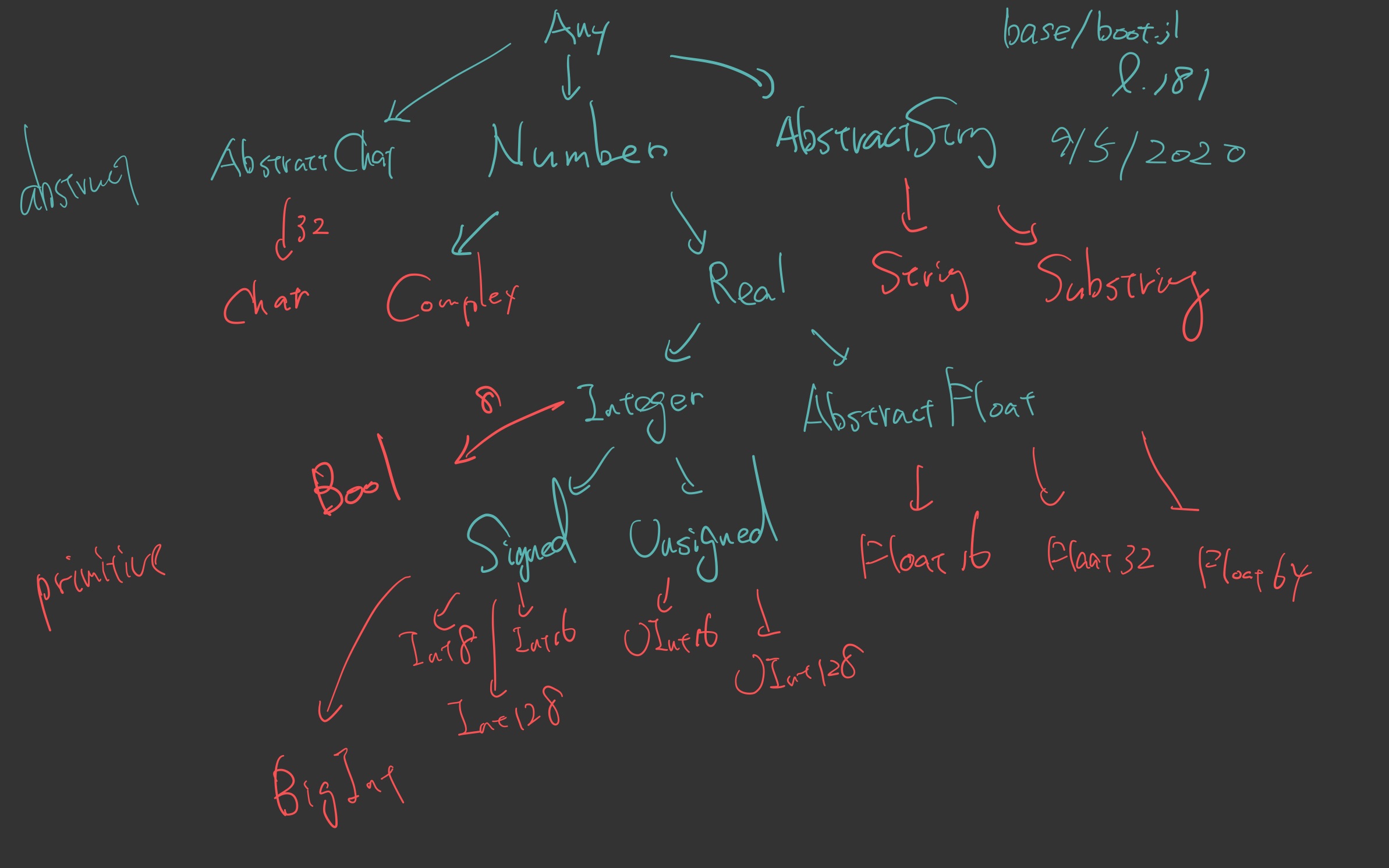
concrete型とabstrat型に大別される.
concrete型の中でも基底層であるprimitive型は 8bit 単位で指定する.abstract型は instance 化して object を得ることはできない.concrete型はsubtypeを持てない.
Built-in Type@base/boot.jl
原始型
Nothing型 <: Any
- ただ一つの instance である
nothingを持つ.
- subtypes を訊くと Type[]と返ってきた.
- nothing objectはREPLでは何も表示されない.return [nothing]と同じ原理.新たな空の概念ですね,記号論が出来る.
isnothing(x) -> ::Bool
整数ℤ
- Int8, UInt8, Int16, UInt16, Int32, UInt32, Int64, Uint64, Int128, Uint128
- Int, UInt型:システムのデフォルトSys.WORD_SIZEに応じて,上記のいずれかのエイリアスとして設定されている.僕のMacは64bitなので64.
- 符号なし整数型はprefix”0x”を付けて十六進法で表す.
- ÷/2
真理値TV={true, false}
- Bool
- !
- ~
- &
-
- ⊻ (+ Tab)
- <<
- 左論理/算術シフト *論理演算はassembly言語の包みと考えるのが良い. 論理演算:word(charやintなど)では届かない,個々のbitに対する演算に対するinterfaceを実装するためにISAや言語に追加された命令操作.初期のコンピュータは「語」単位でデータを扱っていたが,そんなの粒度大きくて仕方がない,という歴史的経緯で後から追加された群.C言語では1bitまで小さいfieldを取れる.(こういう”field”の使い方を,”bit field”という.)
- shift : 語中の全てのbitを左や右にずらして,空いた部分には0を詰める.n bitの左/右シフトは,2^(±n)を乗ずることに等価.だから,実は配列のindexからbyte addressingに換算してどれくらいbaseからとぶかの計算は,左2シフトである.CやJavaの<<に当たる.
- AND : 以前はmaskと呼んでいた,隠すからである.maskはAND論理演算のことだったのか!高級言語の&
- OR, NOR(=ORのNOT) : 左から作用すると考えればちょうどNOT◦OR.それぞれ高級言語の:, ~(これは本来ORの実装)にあたる.
- NOTはNORを使われて,ISAには等価なものはない.
- ===
- メモリ上のobjectとしての同一性.
- こんな意味論数学上にはない.
小数
- Float16, Float32, Float64
- 通常は64で解釈され,32はf0やf-4のsuffixを付けて表す.
- それぞれのサイズに対して,値Inf16, Inf32, Infが無限大を表す値として用意されている.
- 0/0などの「未定義」値として,NaN16, NaN32, NaNが用意されている.
- /2
複素数ℂ
- 虚数単位はim
- real(x)
- imag(x)
- conj(x)
- abs(x)
任意精度演算
- 任意精度整数:BigInt,任意精度小数:BigFloat
定数
Collection型:直積
更なる構造付きのものはDataStructure.jlにある. 各直積型に,tagをつけてその性質を明示する.
Collection 型
全てのobjectに,indexing, slicingの操作が施せる.
indexing - [n] - 最初から数えて第n byteのobjectを返す. - 日本語は3byte表現されていることに注意. - [end] - 最後の要素のindexing.長さがわからないときに使う. - [end-n] - 末尾からのindexing slicing * n:m * UnitRange{Int}型object. * for文にも使える. - [n:m] - n番目からm番目までの閉区間を切り取る. - n=mの時,indexingとは違ってString型を返す.
- 文字列
- Char, String
- UTF-8符号化を用いているので,Unicode文字列がサポートされている.
- UTF-8は可変長の符号化なので,indexingについては注意しなきゃいけない.
- “ … “ #constructor
- ‘ … ‘ #constructor
- string(x[,y,…])
- $
- 文字列補間(interpolation)演算子
- $(obj)で,objに格納されたString型オブジェクトに置換される.
- $(1+2)は評価されてから文字列に変換される.
- Vector{Char::DataType}(s::String) -> Array
- Charと指定したデータの配列にデータ型を変換する.するとindexingが直感的にやりやすくなる.
- これはconstructorに(s)で作用させているのか.
- length(s)
- repeat(s,n::int)
- replace(str, s => t)
- split(str, delimitar) -> Array{SubString{String}, n}
- delimitarの部分で分割し,n要素のString-配列を返す.
- startswith(str1, str2) -> TV::Bool
- str1がstr2の文字列を始切片として持つ場合trueを返す.
- endswith(str1, str2)
- join([str1, str2]::Array{String}, delimitar} -> String
- findfirst(str1, str2) -> slicing object::UnitRange{Int64}
- str1の先頭から,str2にマッチする部分を検索し,見つかったらその最初の要素の範囲を閉区間で返す.
- 正規表現object::Regex
- 文字列型データの前にrをつけることで表す.
- PCRE (Perl compatible regular expressions)ライブラリでサポートされている.
- match(regex::Regex, string) -> RegexMatch(“substring”::Substring{String})::RegexMatch
- matchingがなかった場合はnothing::Nothingが返ってくる.
- RegexMatch
- m.match::Substring{String}:matchした文字列が格納されている.
- m.offset::Int:マッチした位置を表すindexが格納されている.
- 配列
Any直下の型
- (a,b,…)::Tuple{T1,T2,…}
- immutableである
- Array型に対するsize関数の返り値はTuple型.
- 可変長引数もTuple型のobjectとして受けられる.
- 上記から観察されるように,入れ物であって,代数的構造を持たせることを意図していない.その場合はArrayを使う.
- named tuple:Typeの直積.
- 元々NamedTuple.jlという独立したpackageだったが,0.7から統合.
- 要素に数字以外のaliasでタグ付できる.immutable.
- (a=1, b=2)::NamedTuple{(:a, :b), Tuple(Int, Int)}などの記法で定義される.
- つまり,値のTupleと,Symbol型のオブジェクトのTupleとの組で表される.
- この時の射影が,keys関数,values関数として実装されている.
- keyは.演算子でアクセスできる.
- Symbolをindexの代わりに使える.
- 一時的に使うのが普通で,本格的にはstruct, mutable structとして第一級の居住権を与えるのが良い.
- List:Array{T,1}としての実装.Vector{T}というエイリアスもある.
- 追加や削除などの順序的構造が重視されるCollection型.
- スタック,キュー,両端キューはDataStructure.jlへ.
- push!(List, object) -> List’
- pushfirst!(List, object) -> List’
- pop!(List) -> object
- popfirst!(List)
- insert!(List, n, object) -> List’
- deleteat!(List, n) -> List’
- 辞書:Dict{K, V}という直積型
- constructorは
- d = Dict{String, Int}()
- d[“a”] = 1
- d = Dict(key => value, key => value, …)
- constructorの{}内の要素を1つ,または全て省略するとAnyとしたのと等価.
- haskey(Dict, key) -> Bool
- Dict型objectに,所定のkeyが含まれているかを判定する.
- built-inにIdDict型とWeakKeyDict型がある.
- 集合:Set{T}
- constructorは
- 即ち,1次元Arrayから生成される.というより,1次元Arrayにタグをつけたものである.
- 実装は「keyのみを保持する辞書」というべきもので,辞書と同様,値の重複を無視する.
- push!(set, object)
- union(set, List)
- intersect(set, List)
- issubset(List, List) -> ::Bool
- List ⊂ List -> ::Bool
- Set型のinstanceを生成することなく集合演算ができる.
- 多次元配列:Array{T,n}.Matrix{T}はArray{T,2}のエイリアスである.
- MATLABを踏襲している.NumPyとは所々違う.
- NumPyは0からindexingし,row-major orderである.これは,行列のindexingにとって,辞書式順序になる.
- しかしJuliaは1からindexingし,column-major orderである.後者は行列のindexingに沿って,第一要素のストライドが1になる.
- 従って,Juliaは同じ行の要素の列挙が得意.線型代数のものの見方である.
- 内部実装は結局一次元配列(List)であることを意識すると良い.
- [] (constructor)
- [ a b c; d e f; h i j ]
- または改行を入れてもいい.
- []
- isempty(collection) -> Bool
- empty!(collection) -> collection
- length(collection) -> Int
- eltype(collection) -> Type
- 関数名の最後に!
- 引数の一部を変更・破棄する関数
- !のつかない関数は,引数に対する破壊的変更はないので安心して使用できる,という慣習.
- 例:push!,insert!
- sortは新たなobjectを返すが,sort!は引数そのものを変更してしまう.
- for文に使う構文はPythonと同じ使用感.
- しかし,直積型を意識.
- for (key, value) in d::Dict
- 実装は,iterable型オブジェクトを介して行われる.つまり,Juliaは次のように変換して処理される.速度の問題?
- next = iterate(collection)while next !== nothing (x,state) = next #suite next = iterate(collection, state)end
- Juliaはiterable型は無く,Tuple{Int, Int}である.
- 第一要素は,「次の要素」で,第二要素は「その次の要素」のindex(やそれに値するもの)を表す整数またはnothing.
- 従って,自作のcollection型にもfor文iterationを実現させるためには,iterate関数をディスパッチすれば良い.
Array型の関数
作成
- constructor
- Array{T}(undef, dims…)
- 値が初期化されていないことに注意.
- collect(reshape(1:9, 3, 3))
- collectionから,要素を奪って配列に仕立て直す.
- zeros([T,] dims…)
- ones([T,] dims…)
- fill(x, dims…)
- 行列xI
- fill!(A,x)
- 配列AをxIにする.
- rand([T,] dims…)
- 一様分布でランダムに初期化した配列
- 型を指定しないとFloat64で.
- randn([T,] dims…)
- 正規分布でランダムに初期化した配列
- similar(A,[T,dims…])
- 配列Aと類似した配列を返す.
- reshape(A, dims…) -> AbstractArray
- 切り取る,または形を変える.
- 並びはcolumn-major orderのままである.
- AにはUnitRange型も許容されるのがすごい.
- copy(A)
- deepcopy(A)
- Aの要素も再帰的にコピーする.
- [A B]
- 数学的記法の感覚で使える行列の接続.
- view(A, n, m) -> view(::Array{T,n}, m, i)
- n, mはindexingまたはslicing.
- Aから部分配列を抜き出す.
- 返るobjectはAへの参照とindexの情報を持っているので,Aを変更するとその部分配列も変わる.
- この実装は,Aが巨大すぎる場合への配慮を感じる.
- 「ただし,現在の計算機による配列のコピー操作は,一般に非常に高速であるため,巨大な配列を扱うのではない限り,サブ配列を作成するよりも,通常のindexingで新たな配列を作成してしまう方が高速であることも多い.この辺りは,実際に計測してパフォーマンスを確かめてみるのが良いだろう.」
属性
- eltype(A)
- length(A)
- ndims(A)
- size(A)
- size(A,n)
- n番目の次元におけるAのサイズ
- size(A)で返ってくるtupleの第n要素.
- strides(A)
- Aのストライド.
- 第一要素は必ず1になる.
- 要素同士が,一番浅い意味での一次元配列上でどれくらい離れているか.
- stride(A,n)
- n番目の次元におけるAのストライド
- [i, j, k, …]または[n:m, i:j, k:l, …]でindexingできる.
代数的構造
dot付演算子:broadcasting.broadcast(+, A, B)のエイリアスである.broadcast!(+, A, B)とするとAが変更される.
- component-wiseの演算.
- A .+ c
- A + cIと同じ.
- column-wiseの演算.
- A .+ B
- BがAの繰り返し単位になっている場合のみ.
- つまり,size(B)とsize(A)を各要素ごとに見比べたとき,次の2条件のいずれかを満たすとき.
- 値が同じ
- どちらかの値が1
- 2つ目の条件として,pr_i(size(B)) | pr_i(size(A))だったらもっと使いやすかったがね.
- broadcast関数
- broadcast(f, args…)が定義.
- f.(args…)とも記述できる.
- ただし,f=+などの時には使えない.fは関数が想定されている.
- sigmoid.(A)やexp.(A)などである.
- argsはArrayに限らず,tupleでも良い.
位相的構造
- map(f, c::collection…) -> collection
- collection cにelement-wiseにfを適用させる.
- broadcastingやdot演算と似ているが,fが匿名関数でない場合はdot演算を使うのが良い?
- reduce(op, itr; [init]) -> obj
- Aをitrableと見做して,要素ごとにopに突っ込んでいく.
- 従って,次元が1段階下がる.
- filter(f, a::collection) -> a’
- aを要素ごとにfに突っ込んで,fがfalseを返すものについては脱落させる.