ニューラル常微分方程式
シミュレーションなしの拡散モデルとしての連続正規化流
2024-02-14
A Blog Entry on Bayesian Computation by an Applied Mathematician
$$
$$
正規化流 (NF: Normalizing Flow) とは (Tabak and Vanden-Eijnden, 2010), (Tabak and Turner, 2013) が提案・造語した生成モデリングアプローチである.
ニューラルネットワークとしては画像生成を念頭に置いた密度推定モデルである NICE (Dinh et al., 2015)(のちに Real NVP (Dinh et al., 2017))が初期のものであり,正則化流を有名にした.
また変分推論のサブルーチンとして正則化流を使えば,効率的な reparametrization trick を可能にするというアイデア (Rezende and Mohamed, 2015) も普及に一役買ったという (Kobyzev et al., 2021).
アイデアとしては,ニューラルネットワークの一層一層を可逆に設計するという制約を課すのみである.
GAN,VAE,拡散モデル など,深層生成モデルは,潜在空間 \(\mathcal{Z}\) 上の基底分布 \(p(z)dz\) を,パラメータ \(w\in\mathcal{W}\) を持つ深層ニューラルネットによる変換 \(f_w:\mathcal{Z}\times\mathcal{W}\to\mathcal{X}\) を通じて,押し出し \[ p_w(x):=(f_w)_*p(x) \] により \(\mathcal{X}\) 上の分布をモデリングする.
このモデル \(\{p_w\}_{w\in\mathcal{W}}\) の尤度は解析的に表示できない.そこで,GAN (Goodfellow et al., 2014) は敵対的な学習規則を用いれば,尤度の評価を回避できるというアイデアに基づくものであり,VAE (Kingma and Welling, 2014) は変分下界を通じて尤度を近似するというものであった.
正規化流 (normalizing flow / flow-based models) では,拡散モデル に似て,「逆変換」を利用することを考える.
すなわち,\(\{f_w\}\subset\mathcal{L}(\mathcal{Z},\mathcal{X})\) が可逆であるように設計するのである.逆関数を \(g_w:=f_w^{-1}\) と表すと,\(p_w(x)dx\) は \(p(z)dz\) の \(g_w\) による引き戻しの関係になっているから,変数変換 を通じて, \[ p_w(x)=p(g_w(x))\lvert\det J_{g_w}(x)\rvert\;\mathrm{a.e.}\; \] が成立する.
すると, \[ \log p_w(x)=\log p(g_w(x))+\log\lvert\det J_{g_w}(x)\rvert \] を通じて,尤度の評価とパラメータの最尤推定が可能である.
従って,可逆なニューラルネットワーク \(\{f_w\}\subset\mathcal{L}(\mathcal{Z},\mathcal{X})\) を設計することを考える.これは,各層が可逆な変換を定めるようにすることが必要十分である.1
このとき,行列式 \(\det:\mathrm{GL}_n(\mathbb{R})\to\mathbb{R}^\times\) は群準同型であるから,\(g_w\) のヤコビアンは,各層のヤコビアンの積として得られ,その対数は \[ \log\left|\det J_{g_w}(x)\right|=\sum_{i=1}^n\log\left|\det J_{g_i}(z_i)\right|,\qquad z_i:=f_i\circ\cdots\circ f_1(z), \] と得られる.
この条件はたしかにモデルに仮定を置いている.\(p(z)dz\) は典型的に正規で,\(f_w\) は可逆である.
しかしそれでも,深層ニューラルネットワーク \(\{f_w\}\) の表現力は十分高いため,多様な密度のモデリングにも使うことが出来る (Papamakarios et al., 2021).
次節 2 で紹介するカップリング流は大変親しみやすい.
その特別な場合として自己回帰流(第 3 節)があり,複雑な成分間の条件付き構造をモデリングできるが,その分高次元データに対する密度評価とサンプリングは遅くなる.
ある可微分同相 \(f_\theta:\mathbb{R}^m\to\mathbb{R}^m\) と任意の関数 \(\Theta:\mathbb{R}^{n-m}\to\mathbb{R}^{n-m}\) について, \[ (z^{(1)},z^{(2)})\mapsto (f_{\Theta(z^{(2)})}(z^{(1)}),z^{(2)}) \] で定まる変換を カップリング層,\(f\) をカップリング関数,\(\Theta\) を conditioner という.
(Kingma and Dhariwal, 2018) では,conditioner には ResNet を使っている.
この逆変換は \[ (x^{(1)},x^{(2)})\mapsto (f^{-1}_{\Theta(x^{(2)})}(x^{(1)}),x^{(2)}) \] で与えられる.
加えて,後半の成分 \((-)^{(2)}\) には変換を施していないので,カップリング層の Jacobian は \(f_\theta\) の Jacobian に一致する.
\(f_\theta\) は各成分が可逆になるように設計することで \(f_\theta^{-1}\) が計算しやすくされることが多い.
カップリング流を最初に提案したのが NICE (Non-linear Independent Component Estimation) (Dinh et al., 2015) であり,これを画像データに応用したのが (Dinh et al., 2017) の RealNVP (Real-valued Non-Volume-Preserving) である.
NICE では affine カップリング \[ f_\theta(x)=\theta_1x+\theta_2 \] を考えていたが,RealNVP ではさらに \[ f_{\Theta(z^{(2)})}(z^{(1)})=e^{f_{\Theta(z^{(2)})}^{(1)}} \odot z^{(1)}+f_{\Theta(z^{(2)})}^{(2)}(z^{(1)}), \] という形を与えている.ただし \(\odot\) はベクトルの成分ごとの積とした.
実際に訓練する変換は \(f^{(1)}_\theta,f^{(2)}_\theta\) のみであり,これを可逆に制約するということはなく,実装も簡単になっている.
こうして得たカップリング層を,分割 \(z\mapsto(z^{(1)},z^{(2)})\) を取り替えながら(permutation layer と呼ばれる) 32 層重ねるのみで,効率的な密度モデリングができる:
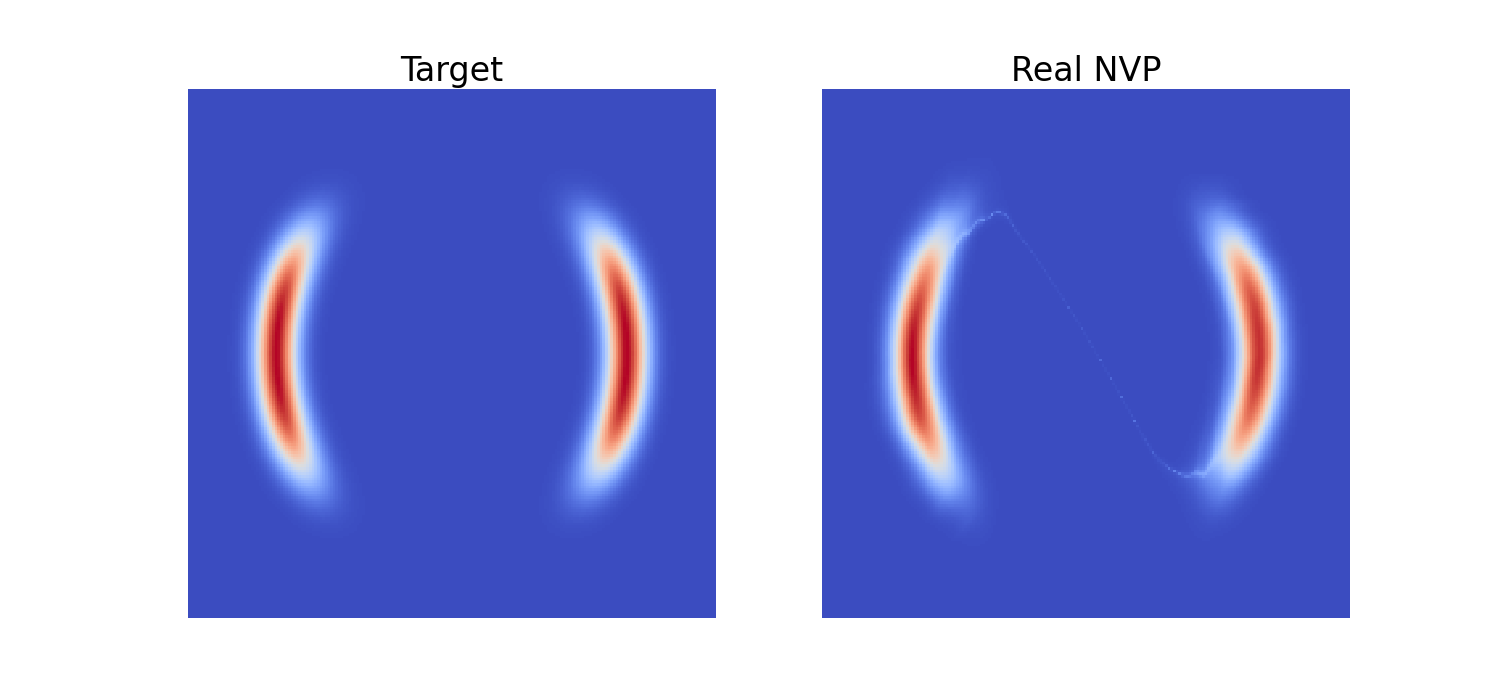
Real NVP では簡単な置換 (permutation) が用いられていたところを,(Kingma and Dhariwal, 2018) では,\(1\times 1\) の畳み込みに基づく,一般化されたカップリング・アーキテクチャを提案した.
このことによる計算量の増加は,LU 分解の利用によって回避している.
OpenAI release に発表されているように,画像生成タスクに応用された.
自己回帰流 (autoregressive flow) とは,カップリング流のカップリング関数 \(f_\theta\) を極限まで押し進めた立場である.
入力 \(z\in\mathbb{R}^n\) を形式上時系列と見做し,ある可微分関数 \(f_\theta:\mathbb{R}\to\mathbb{R}\) と任意の関数列 \(\Theta_i\) について, \[ x_i=f_{\Theta_i(x_{1:i-1})}(z_i) \] と再帰的に定義していく変換 \(z\mapsto x\) を 自己回帰流 という.
この逆は \[ z_i=f_{\Theta_i(x_{1:i-1})}^{-1}(x_i) \] で与えられる.
自己回帰流の Jacobi 行列は上三角行列になるので,Jacobian は効率的に計算できる.
\(\Theta_i\) を単一の自己回帰型ニューラルネットワークを用いてモデリングするためには,\(\Theta_i\) が \(x_{1:i-1}\) のみに依存するようにマスク (Germain et al., 2015) をするとよい.
こうすることで \(x_1,x_2,\cdots\) と順々に生成する必要はなくなり,並列で計算することができる.(しかし逆の計算は並列化はできない).
この方法を採用したのが MAF (Masked Autoregressive Flow) (Papamakarios et al., 2017) であった.
MAF では \(f\) は affine 関数としている.
\(f\) と \(f^{-1}\) を取り替え \[ x_i=f_{\Theta_i(z_{1:i-1})}(z_i) \] としてモデリングする方法を IAF (Inverse Autoregressive Flow) (Kingma et al., 2016) という.
これにより \(x_i\) の生成のために \(x_1,\cdots,x_{i-1}\) を先に評価する必要がなく,並列で生成することが可能になり,サンプリングが高速になる.
従って IAF はサンプリング用途に使われるが,その分 MAF より密度評価が遅くなってしまう (Papamakarios et al., 2017).
Parallel WaveNet (Oord et al., 2018) では,WaveNet モデル \(p_t\) からのサンプリングを加速させる方法として IAF \(p_s\) を用いている.
\(p_t\) の密度評価は高速であったため,\(\operatorname{KL}(p_s,p_t)\) の値は,\(p_t\) の評価と IAF \(p_s\) からのサンプリングによって効率的に計算できる.
この KL 乖離度を最適化することで \(p_t\) のモデルを \(p_s\) に移すことで,サンプルの質を保ちながらサンプリングを加速することに成功した.
カップリング流と自己回帰流はいずれも変換 \(f_\theta:\mathbb{R}^m\to\mathbb{R}^m\) に基づいており,次元 \(m\le n\) が違うに過ぎない.
この \(f_\theta\) の表現力を高めることも重要である.
そのためには,1次元の写像 \(f^i_\theta:\mathbb{R}\to\mathbb{R}\) の積 \(f=(f^i)\) としてデザインすることもできる.
このアプローチを element-wise flow ともいう (Kobyzev et al., 2021).
指定した点 \(\{(x_i,y_i)\}\) をなめらかに補間する曲線を一般に スプライン という.
単調関数によって補間すると約束すれば,可逆な変換 \(f^i\) を得る.
スプラインを,2つの二次関数の商 (rational-quadratic spline) によって補間する方法を提案したのが,Neural Spline Flow (Durkan et al., 2019) である.
この方法では,指定した点 \((x_i,y_i)\) における微分係数が学習すべきパラメータとなる.
例えば von Mises 分布が次のようにモデリングできる:

残差接続 \[ u\mapsto u+F(u) \] において,残差ブロック \(F\) が縮小写像になるようにすれば,全体として可逆な層となる.
iResNet (Invertible Residual Networks) (Behrmann et al., 2019) では,縮小写像 \(F\) のモデリングに CNN を用いた.
この方法のボトルネックは Jacobian の計算にある.愚直に計算すると入力の次元 \(d\) に関して \(O(d^3)\) の計算量が必要になるため,なんらかの方法で効率化が必要である.
Residual Flow (R. T. Q. Chen et al., 2019) では,Jacobian の推定に Monte Carlo 推定量を用いた.
\(J_F\) のランクが低い場合は,\(I+J_F\) の形の行列の Jacobian は効率的に計算できる.
Planar flow (Rezende and Mohamed, 2015) では隠れ素子数1の残差接続層を用いたものである: \[ f(u)=u+v\sigma\biggr(w^\top u+b\biggl). \] この設定では Jacobian が次のように計算できる: \[ \det J_f(u)=1+w^\top v\sigma'\biggr(w^\top u+b\biggl). \]
ただし非線型な活性化関数 \(\sigma\) は全単射になるように選ぶ必要がある.
Planar flow の欠点は逆の計算が難しい点であり,現在広く使われるわけではない (Kobyzev et al., 2021).
他に,circular flow (Rezende and Mohamed, 2015) や Sylvester flow (Berg et al., 2019) も同様な解析的な Jacobian の表示を与えるアーキテクチャである.
Sylvester flow (Berg et al., 2019) は \(\sigma\) を多次元化したものである.この際の Jacobian は Sylvester の行列式の補題 により導かれることから名前がついた: \[ \det(I_n+AB)=\det(I_m+BA). \]
仮に変換 \(F\) に制約を課さずとも,Jacobian は \[ \log\lvert\det(I+J_F)\rvert=\sum_{k=1}^\infty\frac{(-1)^{k+1}}{k}\operatorname{Tr}(J_F^k) \] を通じて,\(\operatorname{Tr}(J_F)\) が (Skilling, 1989)-(Hutchinson, 1990) の跡推定量 により,その無限和が Russian-roulette 推定量により不偏推定できる (R. T. Q. Chen et al., 2019).
Russian-roulette 推定量では,無限和を最初の \(N\) 項のみの有限和で近似するとバイアスが入るので,\(N\) を確率変数とすることで不偏推定が達成される.
変分推論における \(E\)-ステップ(変分分布について期待値を取るステップ)などにおいて,複雑な分布からのサンプラーとしても用いられる (Gao et al., 2020).
この使い方を初めて提唱し,フローベースのアプローチを有名にしたのが (Rezende and Mohamed, 2015) であった.
このような変分ベイズ推論,特にベイズ深層学習に向けたフローベースモデルが盛んに提案されている.
Householder flow (Tomczak and Welling, 2017) は VAE の改良のために考えられたものである.直交行列で表現できる層を,直行行列の Householder 行列の積として表現することで学習することを目指す.
他にも IAF (Kingma et al., 2016), 乗法的正規化流 (Louizos and Welling, 2017), Sylvester flow (Berg et al., 2019) など.
Neural Importance Sampling (Müller et al., 2019) とは,困難な分布からの重点サンプリングの際に,提案分布を正規化流で近似する方法である.この際に \(f_\theta(x)\) にはスプラインを用いている.
Boltzmann Generator (Noé et al., 2019) は名前の通り,多体系の平衡分布から正規化流でサンプリングをするという手法である.
(Hoffman et al., 2019) は IAF を用いて目標分布を学習し,学習された密度 \(q\) で変換後の分布から MCMC サンプリングをすることで効率がはるかに改善することを報告した.実際,フローによる変換を受けた後は対象分布は正規分布に近くなることから,MCMC サンプリングを減速させる要因の多くが消滅していることが期待される.
目標の分布 \(p_w\) を Guass 分布 \(p\) からの写像 \((f_w)_*p\) として捉える発想は,まずなんといっても密度推定に用いられた (S. Chen and Gopinath, 2000).この時点では Gaussianization と呼ばれていた.
この \(f_w\) のモデリングにニューラルネットワークを用いるという発想は (Rippel and Adams, 2013) の Deep Density Model 以来であるようだ.
その後同様の発想は非線型独立成分分析 (Dinh et al., 2015),引き続き密度推定 (Dinh et al., 2017) に用いられた.
現在は MAF 3.2 の性能が圧倒的である.
通常の VAE などは,あくまで \(p(x|z)\) を学習する形をとるが,正規化流を用いて結合分布 \(p(x,z)\) を学習することで,双方を対等にモデリングすることができる.
これを flow-based hybrid model (Nalisnick et al., 2019) という.これは予測と生成のタスクでも良い性能を見せるが,分布外検知などの応用も示唆している.
異常検知 (Zhang et al., 2020),不確実性定量化 (Charpentier et al., 2020) のような種々の下流タスクに用いられた場合は,VAE など NN を2つ用いる手法よりもモデルが軽量で,順方向での1度の使用で足りるなどの美点があるという.
画像生成への応用が多い:GLOW (Kingma and Dhariwal, 2018) (OpenAI release), 残差フロー (R. T. Q. Chen et al., 2019) など.
動画に対する応用も提案されている:VideoFlow (Kumar et al., 2020).
言語に対する応用もある (Tran et al., 2019).言語は離散データであることが難点であるが,潜在空間上でフローを使うことも提案されている (Ziegler and Rush, 2019).
純粋な生成モデリングの他に,IAF 3.3 は (Oord et al., 2018) において音声生成モデルの蒸留に用いられた.
WaveFLOW (Prenger et al., 2018), FloWaveNet (Kim et al., 2019) などもカップリング層を取り入れて WaveNet の高速化に成功している.
モデルの尤度は隠されており,入力 \(\theta\) に対して,\(p(x|\theta)\) からのサンプルのみが利用可能であるとする.このような状況でベイズ推論を行う問題を simulation-based inference (SBI) という.
これはデータの分布のサンプルから学習して,似たようなデータを増やすという生成モデルのタスクに似ており,正則化流との相性が極めて良い (Cranmer et al., 2020).
この際,任意の分布 \(p(\theta)\) に対して,結合分布 \[ p(x,\theta)=p(x|\theta)p(\theta) \] を,シミュレータから得られるサンプルのみからフローベースモデルにより学習してしまうことで,ベイズ償却推論が可能になる (Papamakarios et al., 2019).
この方法はさらに,事後分布推定に特化することで,SMC-ABC などの従来の近似ベイズ計算技法の性能を超えていくようである (Greenberg et al., 2019).
BayesFlow (Radev et al., 2022) は観測データからモデルパラメータへのフローを,償却推論によって学習する.一度このフローが学習されれば,新たなデータの到着に対しても極めて安価な限界費用で推論を更新できる.
Janosh Riebesell のリポジトリ awesome-normalizing-flows に実装がまとめられている.
(Murphy, 2023) 第23章は入門に良い.詳細はサーベイ (Kobyzev et al., 2021), (Papamakarios et al., 2021) に譲られている.
(S. Chen and Gopinath, 2000) の時点では同様のアイデアは Gaussianization と呼ばれていた.
(Tabak and Vanden-Eijnden, 2010), (Tabak and Turner, 2013) が (S. Chen and Gopinath, 2000) のアイデアを推し進めて,確率測度のフローによる押し出しとしての正規化流の提案と命名を行った.このフローの学習は最尤推定によって行なっていた.
この考え方は,VAE ではデコーダーをエンコーダーを用いていたものを,1つの可逆な NN で済ましているようにみなせる.↩︎

