理想点解析のハンズオン
MCMCpack パッケージとオリジナル Stan コードを使って
Bayesian
Statistics
MCMC
R
2024-10-02
理想点解析とは,政治学においてイデオロギーを定量化する方法論である.この手法は多くの側面を持ち,多次元展開法 (MDU: Multidimensional Unfolding) であると同時に項目反応モデルでもある.初めに政治学における理想点解析の目的と役割を概観し,続いて多次元展開法と項目反応理論の2つの観点から理想点解析を眺める.
A Blog Entry on Bayesian Computation by an Applied Mathematician
$$
$$
理想点推定 は (Poole and Rosenthal, 1991) 以来,政治学において各アクターのイデオロギーを定量化・可視化する方法論として用いられている.
理想点推定は,政治学における 空間モデリング の重要な一環であり,現代ではイデオロギーの「近さ」を定量化する際の多次元展開法の一種として,理想点推定を位置付けることができる.
政治過程とは合意形成の過程である.これを各アクターが政策空間上に選好分布を持つとしてモデリングし,その上でのアクターの行動を分析することで政治・立法・司法過程の理解を試みることを 空間モデリング (Davis et al., 1970), (Enelow and Hinich, 1984) という.
空間モデリングの政治学的な理論的根拠として 空間(競争)理論 (Downs, 1957) が源流にある.
政治学における空間理論とは,イデオロギーの「近さ」が影響力を持つとする枠組みであり,はじめは1次元空間上での選挙と投票行動の公理的な分析に用いられた.
空間理論はもともと,ゲーム理論における交渉理論 (bargaining theory) において (Hotelling, 1929) が雑貨店の立地の情報を考慮に入れたことから始まった.
政治学,特に選挙競争において (Black, 1948) が空間競争理論,特に一次元の政策空間を導入し,公理的な議論を行なった:
(Downs, 1957) は (Black, 1948) が用意した政策空間とゲーム理論を合流させ,選挙競争と投票行動の分析に応用した.
(Hotelling, 1929)-(Downs, 1957) のアプローチは政治的競争のモデルの出発点となり,政治的競争を人工的な空間上でモデリングする手法が広がった.
例えば多くの選挙結果を分析する際,政策空間内での中位政策の位置の特定や,実際の政党の政策の中位政策からのズレが重要な意味を持つようになった.
このように政策空間上にアクターをマッピングし,その上で競争をモデリングする手法は 空間モデル (spatial model) とも呼ばれる.
特にアクターが政策空間上に持つ選好分布の最頻値を 理想点 (ideal point) という.
さらには多次元に拡張された理論が多くの経済分析に応用されており,価格などの一次元的な尺度に限らずより一般的な選好を考慮した交渉の議論が可能になっている.3
one way to try to account for political choices is to imagine that each chooser occupies a fixed position in a space of one or more dimensions, and to suppose that every choice presented to him is a choice between two or more points in that space. (MacRae, 1958)
現代では空間理論と空間モデルは,投票などの政治過程,そして議会などにおける立法過程の研究に応用される.広く交渉における空間理論については (林光, 2016) も参照.
さらには純粋にイデオロギーという概念を定量化することにも用いられる.
古くイデオロギーとは一見バラバラに見える政治的問題の相互の繋がりに関する信念体系である (Converse, 2006).
特にリベラル - 中道 - 保守,左 - 右などといった空間的な理解は長らく用いられているものであるが,これは本人が既存のイデオロギーに倣って行動しているというより,よく見られる一貫した行動パターンに名前をつけたものというべきである (Hinich and Pollard, 1981).
一貫した行動パターンの分類,その分類がどれほど行動の予測に有用であるか,これらの尺度は統計学の本領というべきである.
理想点解析で最もよく使われるデータとして,各政治家が審議期間にて表明した投票記録,特に 点呼投票 (Roll Call Voting) 記録が用いられる.
点呼投票データを扱う展開法 (roll-call scaling method) として初めに提案されたものが NOMINATE (nominal, three-step estimation) (Poole and Rosenthal, 1985) であり,次の3段階からなる:
NOMINATE の方法には政策次元が \(K=1\) などの隠匿された仮定があり,これらの仮定を緩めることが必ずしも簡単ではなく,モデル比較の議論となるとほとんど十分な理論的根拠を持たなかった.
理想点推定を統計モデル,特に 項目反応モデル(第 3 節)とみなし,従来は局外母数とみなされた項目毎の母数も,ベイズの枠組みで同時に推論・モデル比較を行うことが (Jackman, 2000), (Jackman, 2001), (Clinton et al., 2004) によって提案された.4
ここでは (Imai et al., 2016) で「標準的な理想点モデル」とされている BIRT (Bayesian Item Response Theory) (Clinton et al., 2004) の定式化を紹介する.
このモデルは潜在変数 \(Y^*\) とパラメータ \((x_i)_{i=1}^N\in\mathbb{R}^{KN},(\beta_j)_{j=1}^J\in\mathbb{R}^{KJ}\) を持つ.
プロビット項目反応モデル 3.4 は,項目反応モデルの文脈でデータ拡張に基づく Gibbs サンプリングによるベイズ推定が古くから議論されていた (Albert, 1992).
(Patz and Junker, 1999) はロジスティックモデルに対して Metropolis-Hastings within Gibbs アルゴリズムを提案している.5
理想点推定にベイズモデルを立てて MCMC により推定する方法は動的なモデル (Clinton and Meirowitz, 2001), (Martin and Quinn, 2002),戦略的投票 (Clinton and Meirowitz, 2017), 階層モデリング (Bafumi et al., 2005) へ拡張され,主流の方法となった.
しかし (Martin and Quinn, 2002) では 47 年の米国最高裁データの分析に5日間かかっている.特に pscl (Zeileis et al., 2008) による Gibbs サンプリングがデータの不均衡性によって収束に苦しんでいる可能性がある.
そこでベイズの方法で理想点解析をやりたいが,理想点推定はモデルが大規模になるために効率的な計算手法が必要となっている.
(Imai et al., 2016) は高速なベイズ推論のために変分 EM アルゴリズムを提案し,emIRT パッケージに実装している.
種々のタイプのモデル(多値反応モデル,動的モデル,階層モデル,テキストデータ)を考察しているので,種々の理想点解析モデルのレビューとしても有用である.
その共通するアプローチは \(Y^*\) を欠測データと扱い,\(\widetilde{x}_i,\widetilde{\beta}_j\) を同時に EM アルゴリズムにより推定し,特定の基準に基づいてアルゴリズムを停止することである.その途中で変分近似を用いる.
ベイズ的な不確実性の可視化を得るために NOMINATE のようにパラメトリックブートストラップ (Carroll et al., 2009), (Lewis and Poole, 2004) を行う.
(Imai et al., 2016) の変分 EM アルゴリズムにより \(d=1\) 次元空間上の理想点を推定した結果が (三輪洋文, 2017) で公開されている:
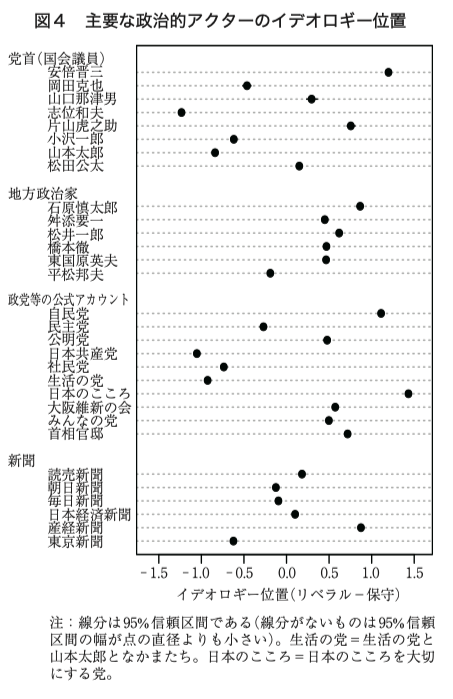
点呼投票データには,政党規律や 票取引 (logrolling) などの戦略的投票行動がある際には,必ずしも個人の政治的信条を反映しないという欠点がある.
そこで点呼投票データの他に有用なデータ源の探索とそれを用いた理想点推定の方法が模索されており,データ統合が最終的な目標として目指されている.
特に日本では政党規律が強く,点呼投票データが適さないため,政治家へのサーベイや質問,専門家調査 (加藤淳子, 2021) によってデータが収集されることが多いという (三輪洋文, 2017), (Miwa and Taniguchi, 2017).
このテキストベースのアプローチは,政党が公開しているマニフェストなどの客観的なデータも取り入れることが可能であるという点に美点がある (岡田謙介 and 加藤淳子, 2016).
また近年では,Twitter が政治家の政策と信条の空間的位置について多くの情報を含んでいる情報源として注目されている (Barberá, 2015), (三輪洋文, 2017).
(Barberá, 2015) は特に Twitter において誰が誰をフォローしているかのデータに注目した.
\((y_{ij})\in M_n(2)\) を,ユーザー \(i\) がユーザー \(j\) をフォローしているかを2値で表した \(0,1\) 成分行列とし,この関係が政策空間 \(\mathbb{R}^d\) におけるユーザー \(i,j\) の距離の近さによって決定されているとする.
\(\theta_i:[n]\to\mathbb{R}^d\) をユーザーの政策空間への埋め込みとすると,\(g\) をリンク関数として \[ g\biggr(\operatorname{P}[Y_{ij}=1\,|\,\alpha_j,\beta_i,\theta]\biggl)=\alpha_i+\beta_j-d(\theta_i,\theta_j) \] とするのである.
ただし,\(\alpha_j\) は知名度,\(\beta_i\) は政治的関心を表す説明変数とした.
これにより Gibbs サンプラーにより \(\alpha,\beta,\theta\) の推定が可能になるが,この方法では推定が遅く,また大規模なデータや偏りのあるデータに弱い.
この問題点は Zig-Zag サンプラーによって解決され,さらに推定が高速になる.詳しくは次の稿も参照:
(Bakker and Poole, 2013) は理想点解析を多次元尺度法と見て,ベイズ化の方法を提案している.
多次元空間への多次元尺度構成法は,非線型次元縮約法,多様体学習法,埋め込み法などといった種々の名前の下で考察されている.
逆に言えば,これらの他手法と比較したり,長所と短所を洗い出すことで,個々の手法に対する理解が深まるかもしれない.
(Escolar et al., 2023) では特許のデータを用い,各企業を技術空間 \(\mathbb{R}^{430}\) 内に埋め込んだ後,mapper (Singh et al., 2007) によりグラフ化したところ,企業の独自戦略が可視化されたという.
(Jackman, 2001), (Clinton et al., 2004) でも自覚されているように,理想点解析は多次元尺度構成法であると同時に,点呼投票という2値応答に特化した項目反応理論とも見れる.
項目反応理論 (IRT: Item Response Theory) は 現代テスト理論 とも呼ばる.
因子分析に基づいた古典テスト理論とは異なり,特定の項目に被験者がどのように応答するかを左右する種々の潜在変数を柔軟に取り入れることを可能にする モデルベース の枠組みである.7
その柔軟性のため,コンピュータを通じた適応的なテスト などの現代的な設定における心理測定・行動計量の基礎を支えている.
項目反応理論の初まりは (F. M. Lord et al., 1968) と ETS における実践・セミナーと目されている.
書籍 (F. M. Lord et al., 1968) はテストに対して真に統計的でモデルベースな扱いを創始したと評されている (Embretson and Reise, 2000).
ただし,同様の取り扱いはデンマークにて (Rasch, 1960) により早くから用いられており,この2つが IRT の源流とされている (Embretson and Reise, 2000).
(Rasch, 1960) のモデルは2値応答の確率を,個人と項目とのそれぞれ1母数の関数としてモデリングする最も単純なものであった.
長らくこの研究はヨーロッパを出ず,(Fischer, 1973) がこれを拡張し翌年に教科書も書いたが,ドイツ語であったので世界的には広まらなかった.
最終的に2つの流れが邂逅したのは Benjamin Wright を介してであった.
1960 年に Rasch が Wright を訪問して以来,Rasch モデルの客観的測定 (objective measurement properties) の重要性を評価し,その推定方法を FORTRAN により実装した (Wright and Panchapakesan, 1969).
その後 Wright の下で学んだ多くの学生が (Rasch, 1960) のモデルに関して基礎的な研究を行なった.8
項目反応モデルは個々人レベルの応答変数に基づいて,個人ごとに違う潜在変数 \(\theta_i\) と項目ごとに違うパラメータ \(\xi_j\) の推定を実行する際に広く用いられる.
\(\theta_i\) は典型的には個々人の「能力」といった概念構成を表すパラメータで 能力母数 (ability parameter) とも呼ばれる (Fox, 2010, p. 6).一方 \(\xi_j\) は難易度パラメータ (difficulty parameter) ともいう.
項目反応モデルの用途は主に潜在変数の測定 (measurement) と多次元尺度構成 (scaling) との2つに分けられる.
理想点解析は後者の用途に属する.これはパラメータ \(\theta_i\) がテストの種類などの測定方法に依存せず,モデルが同一ならば一定した尺度を持つという項目反応モデルの美点に基づく.この普遍性を Rasch は 固有客観性 (specific objectivity) と呼んだ (井澤廣行, 2008, p. 51).
また複数の項目反応モデルの結果の間で尺度を統一することを,特にテスト分析の分野では リンキング または 等化 (equating) という.9
項目反応モデルでは \(\theta_i\) は応答確率を変化させるとする: \[ \operatorname{P}[Y_{ij}=1]=g_j(\theta_i),\qquad i\in[N],j\in[J]. \] このリンク関数 \(g_j\) は 項目特性曲線 (ICC: Item Characteristic Curve / Trace Line) と呼ばれる.
加えて \(\theta_i\) の値で条件付けたとき,異なる項目への応用は互いに独立であると仮定する(局所独立性 という):10 \[ \operatorname{P}[Y_{i1}=1,\cdots,Y_{iJ}=1]=\prod_{j=1}^J\operatorname{P}[Y_{ij}=1]. \]
\(b_j,\theta_i\) は同じ空間 \(\mathbb{R}\) 上にプロットでき,同じ尺度を持つことに注意.\(\theta_i\) が \(b_j\) からみて左右のどちらにあるかに依って,応答確率が \(1/2\) より大きいか小さいかが決まる.
プロビットモデルも \(n\)-PNM (\(n\)-Parameter Normal ogive Model) (F. M. Lord et al., 1968, pp. 365–384) として古くから考えられていたが,Gibbs サンプリングの都合上ロジスティックモデルが好まれた.
ロジスティックモデルで推定された空間上で \(d=1.7\) のスケーリングの違いを除いて [-3,3] 上ではほとんど一致することが知られている (Hambleton, 1991, p. 15).
正解・誤答の2値以外にも,部分点があるなどの多値項目 (polytomous item) に対する拡張が考えられている.
(Muraki, 1992) はこれを一般化し,EM アルゴリズムによる推定方法を与えている.
空間理論(第 1.2 節)の端緒からして,単なる1次元の左-右といった軸ではなく,多次元の潜在空間上に各政治家の理想点を写像したい,という悲願がある (岡田謙介 and 加藤淳子, 2016).
このように新たな次元も考慮に入れることで,リベラル - 保守といった概念への理解が進むことが期待される上に,予測などの下流タスクの精度の大きな向上も望めるだろう.
一般に複雑な構成概念の精緻な検証が可能になる (坂本佑太朗 and 柴山直, 2017) ため,多次元項目反応モデルは近年注目されており,これを実現する統計計算法が必要とされている.
特に識別可能性の問題が深刻になるが,それがベイズのアプローチでは,\(\ell_2\)-ノルムベースであったところを \(\ell_1\)-ノルムベースにすることで,推定の安定性と効率性が向上することなどが考えられている (Lim et al., 2024).
従来の理想点解析における参照軸は,純粋に複雑な政治的現象を理解するための構成概念として利用された.
一方で理想点解析と項目反応理論との類似性に気付いた以上,応答過程に認知科学的変数も取り入れることは自然な拡張の1つとして試みられてきた (Lee, 2001).
例えば個々人の認知過程の違い (Embretson (Whitely), 1984) (DIF: Differential Item Functioning) (Frederic M. Lord, 1980, p. 212) や発達段階の違い (Wilson, 1984) も変数に取り入れることが考えられている.
そこで近年,理想点推定が出力する「次元」に対する人間の空間的認知との関係を明示的に取り入れたモデリングをしようという試みが,行動計量学との接点で考えられている (岡田謙介 and 加藤淳子, 2016).
(浅古泰史, 2016) は政治学における空間理論の入門として良い.
関連する日本語文献には (細野助博, 1981), (稗田健志, 2015) などがある.
NOMINATE 関連については (Poole and Rosenthal, 2001), (Poole and Rosenthal, 2007) を参考にした.
主に (Embretson and Reise, 2000), (Fox, 2010) を参照した.
項目反応理論の日本語文献には (前川眞一, 2023), (山口一大, 2022) が良い.
(井澤廣行, 2008) が Rasch の歴史に詳しい.
(浅古泰史, 2016, p. 69) を参考.↩︎
(浅古泰史, 2016, p. 75) を参考.↩︎
この交渉理論におけるコンテクストから,理想点 というのである.各主体が理想とする点,という意味である.↩︎
“In short, the goal that Bayesian methods make plausible is a transformation of roll call analysis, from a technical scaling or measurement problem best left to psychometricians (witness the canonical status of NOMINATE scores) to something that scholars motivated primarily by substantive concerns can do for themselves.” (Jackman, 2001, p. 240).↩︎
さらに詳しくは (Fox, 2010, pp. 71–) も参照.↩︎
probit とは (Bliss, 1934) が probability unit から名付けた.↩︎
例えば消費者の購買行動をモデリングする際は,選択疲れをした消費者は中間的な商品を選びやすいという 妥協効果 (compromise effect) (Simonson, 1989) などの文脈効果もモデルに入れる必要がある (加藤拓巳, 2021).↩︎
だが,Bock も Wright の教え子も主に教育学で活躍しており,最終的に心理学者に心理測定の基本として古典テスト理論を IRT が代替したのは 2000 年代になってからだったという (Embretson and Reise, 2000, p. 7).↩︎
2つは厳密には,等化は一番強い仮定のもとで行われるリンキングの一つである (宇佐美慧 et al., 2018).例えば集団の基礎学力が違った場合,同一の困難度を測定するためでも別のバージョンのテストを作成する必要がある.等化は ICC が affine 合同である場合に affine 変換により可能である (宇佐美慧 et al., 2018).↩︎
これが成り立つように,1つの設問で問われる能力は1つになるように設計することが原則である (宇佐美慧 et al., 2018).↩︎
3母数ロジットモデルにおいて加わる母数は当て推量母数/下方漸近パラメータとも呼ばれる (宇佐美慧 et al., 2018).↩︎