階層モデル再論
多変量解析から機械学習へ
2024-08-12
A Blog Entry on Bayesian Computation by an Applied Mathematician
$$
$$
多様体学習とは,非線型な次元削減手法のことをいう.
「多様体」の名前の由来は,「高次元データは低次元の部分多様体としての構造を持つ」という 多様体仮説 (Fefferman et al., 2016) である.1
特に多様体学習と呼ばれる際は,知識発見やデータ可視化を重視する志向がある.
一方で自己符号化器などによる表現学習では,種々の下流タスクに有用な表現を得るための分布外汎化が重視される,と言えるだろう.
近年,対照学習による表現学習が注目されている.このアプローチには,目的関数にサンプル間の類似度に関する事前情報を含めやすいという美点がある.
このような表現学習法は 距離学習 (metric learning) とも呼ばれている.
多くの多様体学習手法や,\(\mathbb{R}^d\) への埋め込み手法は,なんらかの意味でサンプル間の類似度を保存する埋め込みを求めている (Agrawal et al., 2021).
この意味で,「距離学習」というキーワードは,表現学習と多様体学習の交差点を意味していると言えるだろう.
現代のシークエンサー NGS (Next Generation Sequencer) では,単一の細胞が保持している mRNA の全体 scRNA-seq (single-cell RNA sequencing) を調べることができ,このような場合は極めて高次元のデータが大量に得られることになる.
例えば COVID-19 重症患者の末梢免疫の状態を調べるために末梢血単核細胞 PBMC2 から scRNA-seq を行った例 (Wilk et al., 2020) では,全部で \(n=44,721\) の細胞のデータが,\(p=26361\) 次元のスパースなベクトルを扱っている.3
多次元尺度法 (MDS: Multi-Dimensional Scaling) (Torgerson, 1952), (Kruskal, 1964) は,元のデータの「(非)類似度」を保存したままの低次元表現を探索する手法群である.
後続の手法はいずれも高次元データ \(\{y_i\}_{i=1}^n\subset\mathbb{R}^p\) を所与とするが,MDS は本質的には類似度行列 \(D\in M_n(\mathbb{R})\) が与えられていればよく,解析対象は必ずしも \(\mathbb{R}^p\)-値のデータである必要はない.
類似度行列 \(D\) が与えられたのちは,埋め込み \(\{z_i\}_{i=1}^n\subset\mathbb{R}^d\) の要素間の類似度が \(D\) に近くなるように埋め込みを学習する.
特にデータ \(\{x_i\}_{i=1}^n\subset\mathbb{R}^p\) 間の Euclid 距離を \(D\) とし,埋め込み \(\{z_i\}_{i=1}^n\subset\mathbb{R}^d\) の間の経験共分散が \(D\) に Hilbert-Schmidt ノルムに関して最小化することを (Torgerson, 1952) は考えた.
これは (Eckart and Young, 1936) の定理 を通じて PCA に一致する,線型な次元縮約法となる.
(Torgerson, 1952) のアプローチは 計量多次元尺度法と呼ばれ,一般のデータに適用可能な (Kruskal, 1964) のアプローチは非計量多次元尺度法と対照される.4
前述の通り,\(D\) は Euclid 距離に基づくとは限らないし,そもそもデータはベクトルなど構造化されているものでなくても良い.
このような一般的な場面で \(\{z_i\}_{i=1}^n\subset\mathbb{R}^d\) 間の類似度の \(D\) との「近さ」を図る尺度として,Kruskal の Stress-1 (Kruskal, 1964) がよく用いられる: \[ \mathcal{L}(E):=\sqrt{\frac{\sum_{i_1<i_2}\left(z_{i_1i_2}-d_{i_1i_2}\right)^2}{\sum_{i_1<i_2}d_{i_1i_2}^2}}. \]
勾配法を用いた最適化ベースの推論手法が使えるが,この目的関数に関しては SMACOF (Scaling by Majorizing a Complementary Function) (de Leeuw, 1977) という凸最適化アルゴリズムが提案されており,scikit-learn にも実装されている.
(Sammon, 1969) は探索的データ解析の文脈から,データの「構造」をよく保つために,\(z_{i_1i_2}\) の値が小さい場合は小さな変化も重視してくれるようにスケーリングを調整する新たなストレス関数を提案した:
\[ \frac{1}{\sum_{i_1<i_2}z_{i_1i_2}}\sum_{i_1<i_2}\frac{\left(z_{i_1i_2}-d_{i_1i_2}\right)^2}{z_{i_1i_2}}. \]
係数 \(\frac{1}{\sum_{i_1<i_2}z_{i_1i_2}}\) の存在は,勾配法による推論を効率的にする.
多次元展開法 (MDU: Multi-Dimensional Unfolding) は,個人の選考順位データに対処するために (Coombs, 1950) が提唱した,多次元尺度法 (MDS) の拡張である (足立浩平, 2000).
MDU ではさらに一般的な行列 \(D\) を取ることができる.というのも,MDS では暗黙のうちに行と列は同一物であり,\(D\) の対角成分は全て一定であるが,MDU では行と列で別の対象を取ることができる.
例えば,個体 \(i\) が項目 \(j\) をどれくらい好むか?を \(D\) と取り,行と列を同一の平面上に バイプロット (Gabriel, 1971), (Gower, 2004) する.
特に政治科学の分野で用いられる多次元展開手法であり,\(\mathbb{R}^d\;(d\le3)\) に埋め込むことが考えられる.
その際は \(\mathbb{R}^d\) 上への観測に至るまでの階層モデル(潜在変数モデル)を立てて,全体を MCMC により推定する方法が,(Martin and Quinn, 2002) 以来中心的である.
(Imai et al., 2016),(三輪洋文, 2017) は変分 EM アルゴリズムにより推定している.
力学モデルによるグラフ描画法 (Force-directed layout / Spring Embedder) (Tutte, 1963), (Eades, 1984), (Kamada and Kawai, 1989) は,グラフの頂点を質点,辺をバネに見立てて,グラフを \(\mathbb{R}^2\) 上に展開する方法である.
超大規模集積回路 (VLSI) の設計問題と両輪で発展してきた (Fisk et al., 1967), (Quinn and Breuer, 1979).
このグラフ埋め込み法はポテンシャルエネルギーをストレスと見立てた MDS とみなせる.
MDS 法の難点の1つに,データがある部分多様体上に存在する場合,その部分多様体上の測地距離を尊重できないという点がある.
このデータの部分多様体構造を尊重した測地距離をグラフにより捉え,MDS を実行する手法が Isomap (Tenenbaum et al., 2000) である.
ステップ2においては Dijkstra 法を用いることができ,高速な計算が可能である.
しかし Isomap はデータの摂動に極めて弱いことが topological instability として知られている (Balasubramanian and Schwartz, 2002).
この安定性をカーネル法に外注する Robust Kernel Isomap (Choi and Choi, 2007) も提案されている.
カーネル法の見地からは,従来の PCA は線型な核を用いた場合のカーネル主成分分析だったと相対化される.
しかし,少なくとも RBF カーネルを用いた場合は (Weinberger et al., 2004),次元縮約の代わりにより高次元な空間に埋め込みがちである.
カーネル PCA を次元縮約のために用いたものが 半正定値埋め込み (semidefinite embedding) または 最大分散展開 (MVU: Maximum Vairance Unfolding) (Weinberger et al., 2004) である.
これは,カーネル PCA による埋め込みの中でも,元データ \(y\) と埋め込み \(z\) の間で \[ \|z_i-z_j\|_2=\|y_i-y_j\|_2,\qquad(i,j)\in G \] を \(K\)-近傍 \(G\) に関して満たすような埋め込みの中で, \[ \max_{z\in\mathbb{R}^d}\sum_{i,j}\|z_i-z_j\|_2^2 \] を最大にするものを求めることを考える.
幸い,これを満たすカーネル関数は半正定値計画によって解くことができ,このカーネル関数によるカーネル PCA 法が MVU である.
ここまでの手法は畢竟,類似度行列 \(Y\) に関して,kPCA は特徴空間上でのスペクトル分解,Isomap はデータのなす \(K\)-近傍グラフ上でのスペクトル分解を考えている.
これに対して,スパースなスペクトル分解を用いることで,データの局所的構造がさらに尊重できることが,局所線型埋め込み (LLE: Local Linear Embedding) (Roweis and Saul, 2000) として提案された.
この方法は Isomap よりデータの摂動に関して頑健であることが知られている.
この方法では,データ多様体の接空間に注目する.
まず,各点をその \(K\)-近傍点の線型結合で表す方法を,次のように学習する: \[ \widehat{W}=\min_{W}\sum_{i=1}^n\left(x_i-\sum_{j=1}^nw_{ij}x_j\right)^2,\qquad\operatorname{subject to}\begin{cases}w_{ij}=0&x_i,x_j\,\text{は}\,K\text{-近傍でない}\\\sum_{j=1}^Nw_{ij}=1&\text{任意の}\,i\in[N]\,\text{について}\end{cases} \] こうして得た \(\widehat{W}\) はスパース行列になる.この \(W\) を通じて,局所構造を保った低次元埋め込みを構成する: \[ \widehat{Z}=\operatorname*{argmin}_Z\sum_{i=1}^n\left\|z_i-\sum_{j=1}^n\widehat{w}_{ij}z_j\right\|_2^2. \]
この最適化問題は,\(I_n-W\) の 特異値分解 に帰着する.
Hessian Eigenmaps (Donoho and Grimes, 2003) は微分幾何学的見方を推し進め,Hessian からの情報を取り入れた局所線型埋め込みの変種である.
Tangent Space Alignment (Zhang and Zha, 2004) はより明示的に接空間の構造に注目する.
Laplacian Eigenmaps または Spectral Embedding (Belkin and Niyogi, 2001) は,データ点の \(K\)-近傍グラフ \((Y,E)\) 上で \[ \mathcal{L}(Z):=\sum_{(i,j)\in E}W_{ij}\|z_i-z_j\|_2^2,\qquad W_{ij}:=\exp\left(-\frac{\|y_i-y_j\|_2^2}{2\sigma^2}\right) \] を最小化する埋め込み \(Z\) を求める方法である.
この目的関数 \(\mathcal{L}(Z)\) は実は,\(K\)-近傍グラフ \((Y,E)\) の Laplacian 行列 \(L\) に関して \[ \mathcal{L}(Z)=2\operatorname{Tr}(Z^\top LZ) \] とも表せる.
この量は,\(Z\) をグラフ上の関数と見た際の Dirichlet 汎函数になっており,グラフ上の関数としての「滑らかさ」の尺度となっている.
最も滑らかであるような \(Z\) を学習することで,データの局所構造を最も反映した埋め込みが得られる,というアイデアである.
SNE (Hinton and Roweis, 2002) では,\(K\)-近傍グラフを用いた Isomap を,ハードな帰属からソフトな帰属へ,確率分布を用いて軟化する.
t-SNE (van der Maaten and Hinton, 2008) では SNE が Gauss 核を用いていたところを Laplace 核(\(t\)-分布)を用いることで,より分散した表現を得ることを目指す.
ハイパーパラメータ \(\sigma_i\) を残して, \[ p_{j|i}:=\frac{\exp\left(-\frac{\lvert x_i-x_j\rvert^2}{2\sigma_i^2}\right)}{\sum_{k\neq i}\exp\left(-\frac{\lvert x_i-x_k\rvert^2}{2\sigma_i^2}\right)} \] と定める.
この \((p_{j|i})\) と,潜在空間における帰属確率 \[ q_{j|i}:=\frac{e^{-\lvert z_i-z_j\rvert^2}}{\sum_{k\neq i}e^{-\lvert z_i-z_k\rvert^2}} \] と一致するように埋め込みを学習する.すなわち,訓練目標は \[ \mathcal{L}:=\sum_{i=1}^n\operatorname{KL}(p_{-|i},q_{-|i})=\sum_{i,j=1}^np_{j|i}\log\frac{p_{j|i}}{q_{j|i}} \] と定める.
この目的関数は凸ではなく,SGD で訓練可能であるが特殊なノイズスケジュールなどのテクニックがある.5
SNE は,ある事前分布を課したスペクトル埋め込みとも見れる (Carreira-Perpiñan, 2010).
\(p_{i|j},q_{i|j}\) ではなく,結合分布 \(p_{ij},q_{ij}\) を用いることで,目的関数を対称化することができる.
このとき,目的関数の勾配は次のようになる: \[ \nabla_{z_i}\mathcal{L}(Z)=2\sum_{j=1}^n(z_j-z_i)(p_{ij}-q_{ij}). \]
t-SNE (van der Maaten and Hinton, 2008) は \(p_{j|i}\) の定義に Gauss 核を用いていたところを,Cauchy 分布の密度(Poisson 核)に置き換えたものである: \[ q_{ij}=\frac{\frac{1}{1+\lvert z_i-z_j\rvert^2}}{\sum_{k<l}\frac{1}{1+\lvert z_k-z_l\rvert^2}}. \]
このことにより,元々遠かったデータ点を引き寄せ過ぎてしまうこと (crowding problem) を回避できる.
勾配は \[ \nabla_{z_i}\mathcal{L}(Z)=4\sum_{j=1}^n(z_j-z_i)(p_{ij}-q_{ij})\frac{1}{1+\lvert z_i-z_j\rvert^2} \] で与えられ,対称化された SNE に,\(z_i,z_j\) の距離に従って調整する因子が追加された形になっている.
t-SNE は \(O(n^2)\) であるが,埋め込みの次元数が \(d=2\) などの低次元であるとき,これを \(O(n\log n)\) にまで加速する実装が知られている (Maaten, 2014).
t-SNE はハイパーパラメータ \(\sigma_i^2\) の設定に敏感である上に訓練が局所解にトラップされるなど不安定で,またデータ内のノイズに弱いことが知られている (Wattenberg et al., 2016).
敏捷な埋め込み (EN: Elastic Net) (Carreira-Perpiñan, 2010) という,より安定的でノイズに頑健な手法が目的関数を修正することで得られている.
LargeVis (Tang et al., 2016) は t-SNE の計算量を軽減させるために,\(K\)-近傍グラフの計算に近似手法である ランダム射影木 (Dasgupta and Freund, 2008) を導入する.
UMAP (Uniform Manifold Approximation and Projection) (McInnes et al., 2018) は t-SNE より高速で,大域的構造をより尊重する手法として提案された.
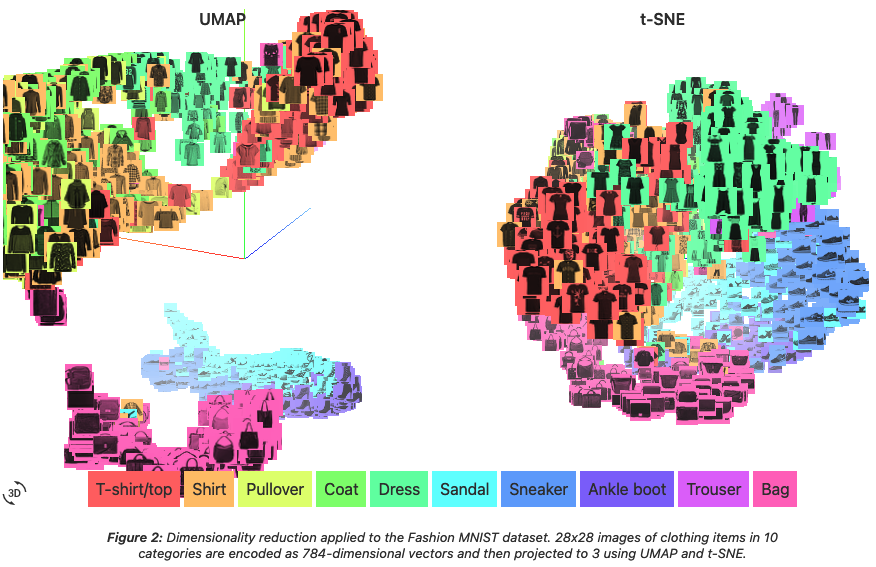
t-SNE, VargeVis, UMAP はいずれも確率を導入しているが,完全にモデルベースの発想をしているわけではない.
(Saul, 2020) はこれらの手法を 潜在変数モデル として定式化し,データサイズに合わせて EM アルゴリズムをはじめとした推定手法を議論している.
拡散埋め込み (Diffusion Map) (Coifman et al., 2005) では,データ上に乱歩を定めることでデータ多様体の局所構造を捉える.
この方法は Isomap 3 でグラフを用いて測地距離を近似したよりも,頑健なアルゴリズムを与える.
PHATE (Heat Diffusion for Affinity-based Transition Embedding) (Moon et al., 2019) は DEMaP (Denoised Embedding Manifold Preservation) という情報理論に基づく距離を定義し,データの局所構造を捉える.
Self-organizing Map (Kohonen, 1982), (Kohonen, 2013) は,ニューラルネットワークのダイナミクスを利用した,クラスタリングベースの次元縮約法である.
IVIS (Szubert et al., 2019) は 三つ子損失を取り入れたシャムネットワーク による距離学習に基づく次元縮約法である.
Mapper (Singh et al., 2007) は,距離空間 \(E\) 上のデータ \(\{x_i\}\subset E\) を,関数 \(f:E\to\mathbb{R}\) が定める分解を用いてグラフとして図示する方法である.\(f\) は filter function と呼ばれる.
他手法とは違い,出力が \(\mathbb{R}^d\) への埋め込みではなく,グラフである点に注意.
(Escolar et al., 2023) では特許のデータを用い,各企業を技術空間 \(\mathbb{R}^{430}\) 内に埋め込んだ後,mapper によりグラフ化したところ,企業の独自戦略が可視化できるという:
Mapper アルゴリズムは filter function \(f\) の選択が重要になるが,これにハイパーパラメータを導入し (Oulhaj, Carrière, et al., 2024),さらにニューラルネットワークで推定する方法 Deep Mapper (Oulhaj, Ishii, et al., 2024) が,分子モデリングと創薬に応用されている.
結局機械学習が日々の統計的営みに与えた最大のインパクトは,ニューラルネットワークや生成モデル自体というより,高精度な非線型表現学習であると言えるかもしれない.
例えば (Hoffman et al., 2019) は IAF (Kingma et al., 2016) を用いて目標分布を学習し,学習された密度 \(q\) で変換後の分布から MCMC サンプリングをすることで効率がはるかに改善することを報告した.実際,フローによる変換を受けた後は対象分布は正規分布に近くなることから,MCMC サンプリングを減速させる要因の多くが消滅していることが期待される.
多くの他の統計的な困難も,良い表現学習された空間上(あるいはカーネル空間上)で実行することで回避することができるということになるかもしれない.これが最初に SVM が機械学習に与えた希望の形であったし,ニューラルネットワークに対する飽くなき理論的興味の源泉でもある.データの視覚化や探索的データ解析の意味では,よき潜在表現を必要としているのは人間も然りである.
(Yao, 2011) は LLE, Laplacian Eigenmaps, カーネル PCA, Diffusion Maps の関連性を扱っている講義スライドである.
(Wattenberg et al., 2016) はインタラクティブに t-SNE の性質を理解できるウェブページである.Understanding UMAP も同様にして,UMAP と t-SNE の比較を与えている.
(Murphy, 2022) 第20章は次元縮約という題で,PCA, FA から自己符号化器,多様体学習を解説している.(Burges, 2010) が同じテーマのしばらく前のサーベイである.
多様体学習に関しては (本武陽一, 2017) も注目.
PCA は Kosambi-Karhunen-Loéve 変換ともいう (Bishop and Bishop, 2024, p. 497).PCA からとにかくスペクトルとの関連が深い.
(本武陽一, 2017) も注目.↩︎
(Peripheral Blood Mononuclear Cell)↩︎
なお,(Wilk et al., 2020) では最初の 50 の主成分がプロットされている.↩︎
(岡田謙介 and 加藤淳子, 2016) 参照.大変入門に良い日本語文献である.計量的多次元尺度法は 主座標分析 (PCoA: Principal Coordinate Analysis) (Young and Householder, 1938) とも呼ばれる.↩︎
どうやら相転移境界が近いため,アニーリングが必要?(Wu and Fischer, 2020).(Murphy, 2022, p. 700) 20.4.10.1節も参照.↩︎
このアルゴリズムは Morse 理論における概念である Reeb グラフの拡張と見れる.(Oudot, 2016) のスライドや (Schnider, 2024) の講義資料も参照.↩︎