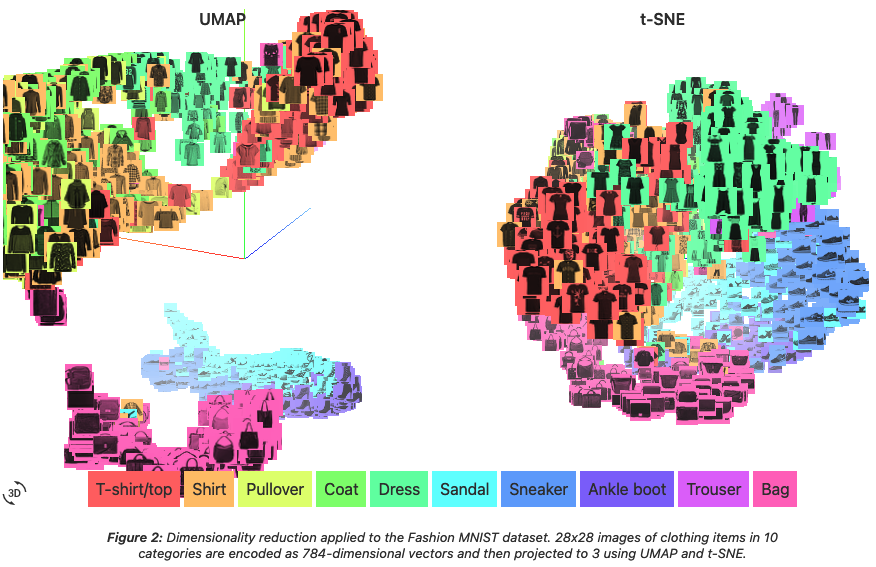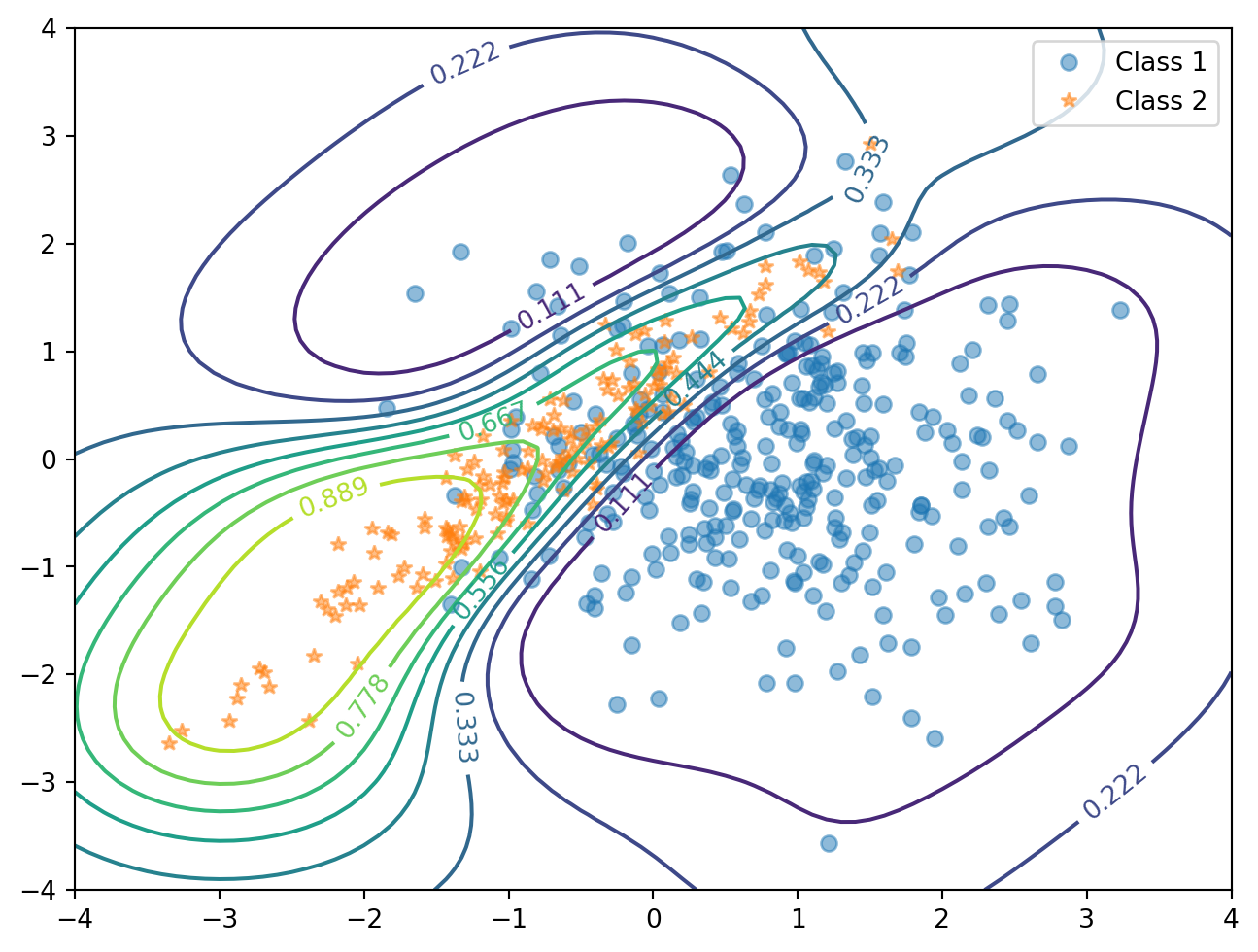
Gauss 過程を用いた統計解析
実践編(回帰と分類)
2024-02-11
A Blog Entry on Bayesian Computation by an Applied Mathematician
$$
$$
カーネル法とは,非線型な前処理を施すことで,その後の線型なデータ解析の性能を向上させるための手法であると言える.
これはニューラルネットワークと違いカーネル関数を決める段階が必要がある一方で,無限次元の特徴空間(再生核 Hilbert 空間)上の表現を得ることが出来るという美点がある.
線型手法が使えないときに,変数変換を挟むことで線型分離可能な問題に還元するという手法は広く見られる.
例えば,データが正規分布から大きく違っている場合,Box-Cox 変換 (Box and Cox, 1964)
\[ x \longmapsto x^{(\lambda)} = \begin{cases} \displaystyle \frac{x^\lambda - 1}{\lambda} & \lambda \neq 0\\ \log x & \lambda = 0\end{cases} \]
を通じて正規分布に近づけることが出来る.\(\lambda\in\mathbb{R}\) をハイパーパラメータとしてデータから調整出来る.
Box-Cox 変換は特定のリンク関数 \(G\) に関する一般化線型モデルと見れる.1
Box-Cox 変換はカーネル法もこのような非線形変換を見つけてくるための統一的な方法論である.
カーネル法によってデータを非線型変換をして得る空間は 特徴空間 と呼ばれ,この上で従来の線型なデータ解析を施すだけで,全体としては非線型な手法の完成である.
1992年,当時は2023年に生きる我々と全く同じく,ニューラルネットワーク(以降NN)のブームのさなかにあった(当時は第二期ブーム).このブームを一度終わらせたのが,(Boser et al., 1992) によるカーネル法であった.
当時は数学の範疇から出たことがなかったカーネルの概念を用いて,SVMを非線形化したKernel SVMという手法を提案したのである.以降,非線形問題を扱えるモデルとして,NNを凌ぐ勢いで発展し,NNがvanishing gradientsという障壁にぶつかったこともあり,2000年から2006年を「深層学習の冬」とまで言わしめた.
2006年というのは,(Hinton et al., 2006), (Hinton and Salakhutdinov, 2006) の年である.この自己符号化器の発表がきっかけになり,DNNの訓練がますます効率的になり,一方でKernel SVMは次の2つの障壁に直面しており,現在のDNN最強の時代を我々は見ている.2
カーネル法のトリックは単純であるから,個々の問題に即したカーネルの選び方,または適応的にカーネルを定めるアルゴリズムのデザインが,今後の課題である.
カーネルと言ったとき,数学的には「(実数値の)半正定値対称関数」を指す.
この「正定値カーネル」の概念は,次の意味で,「内積」と同一視できる.「内積」と同一視できるという意味で,「類似度の測り方」に対応する.
ここで,数学概念について,少し突飛に思えるかもしれないが,次の名前をつける.
「特徴写像」は,データ \(x,y\in\Omega\) を正定値カーネルが測る「類似度」を変えないように,しかしながら全く違う空間内の点 \(\Phi(x),\Phi(y)\in H_k\) に写している.「類似度」が変わっていないことを「カーネルトリック」と呼ぶ.
この「トリック」は少し 米田埋め込み に似ている.データ \(x\in\Omega\) の他のデータとの類似度の全体 \(k(-,x):\Omega\to\mathbb{R}\) は,そのデータを特徴づけるのである \(k(-,x)=\Phi(x)\in H_k\).
また,関数のなすHilbert空間 \(H\subset\mathbb{R}^\Omega\) が, \(\{\mathrm{ev}_x\}_{x\in\Omega}\subset H^*\) を満たすならば,\(H\) は再生核を持つ.このような関数空間 \(H\) の内積の構造を \(\Omega\) にも導入したいとき, \(k\) を通じてすれば良いということになる. \(k\) は違う \(H_k\) と \(\Omega\) を対応づけ,正しい \(k\) を選ぶと,データ \(\{x_1,\cdots,x_n\}\subset\Omega\) のうちなる「特徴」を暴き出せるかもしれない.
こうして見たように,カーネル法は
要は計算できることは内積だけなのである!しかし,特徴写像や特徴ベクトルの表示を陽に使わずとも,内積だけで実行可能な線型データ解析は,実に多いのである.
Ridge回帰は,次の最適化によって線型回帰係数 \(a\in\mathbb{R}^p\) を推定するロバスト手法である:
\[ \min_{a\in\mathbb{R}^p}\frac{1}{n}\sum_{i=1}^n(Y_i-a^\top X_i)^2+\lambda\|a\|^2. \]
これを「カーネル化する」とは,「特徴空間で実行する」ということである. \(X_i\) の代わりに \(\Phi(X_i)\) 上で,Euclid内積 \(a^\top X_i\) の代わりに特徴空間の内積 \((f|\Phi(X_i))_{H_k}\) で実行するということである:
\[ \min_{f\in H_k}\frac{1}{n}\sum_{i=1}^n\biggl(Y_i-(f|\Phi(X_i))_{H_k}\biggr)+\lambda\|f\|^2_H \]
実はこの式は次と等価:
\[ \min_{f\in H_k}\frac{1}{n}\sum_{i=1}^n\biggl(Y_i-f(X_i)\biggr)+\lambda\|f\|^2_H \]
たしかに,\(f\in H\) は一般の関数であり,非線形な回帰を行なっていることになる!
しかし,最後にこの最適化問題をどう解くか?という問題が残り,無限次元空間 \(H\) 上での最適化の理論が必要になるかといえばそうではなく,
\[ f=f_\Phi:=\sum_{i=1}^nc_i\Phi(X_i) \]
という形のみで解を探せば良いことが判る.これは \(f=f_\Phi\oplus f_\perp\) という直交分解を考えることで従う.つまり,最適化はデータ点 \(\Phi(X_1),\cdots,\Phi(X_n)\) の張る有限次元部分空間上のみで考えれば良い.この事実には representer 定理 (Kimeldorf and Wahba, 1970), (Schölkopf et al., 2001) という名前がついている.
すると目的関数は
\[ \frac{1}{N}\sum_{i=1}^N\biggl(Y_i-\sum_{j=1}^Nc_jk(X_i,X_j)\biggr)^2+\lambda\underbrace{\sum_{i,j=1}^Nc_ic_jk(X_i,X_j)}_{=c^\top Kc} \]
となり,これを解くと,カーネルRidge回帰の解は
\[ \widehat{f}(x)=\boldsymbol{k}(x)^\top(K+n\lambda_nI_n)^{-1}\boldsymbol{Y}, \]
\[ \boldsymbol{k}(x)=\begin{pmatrix}k(x,X_1)\\\vdots\\k(x,X_N)\end{pmatrix},\boldsymbol{Y}=\begin{pmatrix}Y_1\\\vdots\\Y_N\end{pmatrix} \]
と表せることがわかる.
第 1.2 節で紹介した2つの問題点に戻る.
この2.について,カーネルRidge回帰の例だと,逆行列 $\((K+n\lambda_nI_n)^{-1}\) の計算が実行不可能になるという形で現前する.しかし,Woodburyの公式から,低ランク近似が得られていれば,それを活用できる.一般にGram行列の固有値の減衰は速いことが知られており,この低ランク近似の戦略は筋が良いと言える.
1.について,まずSVMなどの教師あり学習の設定では,CVを使うことでカーネル選択をすることができる.が,教師なし学習では一般的な方法はない.特にカーネル主成分分析(次節の例).しかし,これを適応的に学習するというのは良いアイデアだろう.Multiple Kernel Learning (Gönen and Alpaydin, 2011) はカーネルの凸結合を学習し,Deep Kernel Learning (Wilson et al., 2016) はNNによってカーネルを学習する.
主成分分析を抽象的に理解すれば,分散が大きい方向に射影をすることで,「意味がある方向」を見つける手法なのであった.
主成分方向とは
\[ \max_{a\in\mathbb{R}^p:\|a\|=1}\sum_{i=1}^N(a^\top(X_i-\overline{X}))^2. \]
の解 \(a\in\mathbb{R}^p\) である.これは分散共分散行列の固有値問題を解くことに等価になる.
この手法を「カーネル化」するには,特徴空間で実行すれば良い.
\[ \max_{f:\|f\|_H=1}\sum_{i=1}^N\biggl(f\,\bigg|\,\Phi(X_i)-\overline{\Phi}(X)\biggr)^2 \]
この解も,データの特徴ベクトルの張る有限部分空間内で調べれば十分なのである!というのも,正確には,平均を引いた次の形のみを考えれば良いことが判る:
\[ f=\sum_{i=1}^Nc_i\biggl(\Phi(X_i)-\overline{\Phi(X)}\biggr) \]
実際には,中心化Gram行列の固有値問題に帰着する:
\[ \widetilde{K}_{ij}=k(X_i,X_j)-\frac{1}{N}\sum_{b=1}^Nk(X_i,X_b)\qquad\qquad \]
\[ \qquad\qquad-\frac{1}{N}\sum_{a=1}^Nk(X_a,X_j)+\frac{1}{n^2}\sum_{a,b=1}^Nk(X_a,X_b). \]
データ \(\{x_1,\cdots,x_n\}\subset\mathbb{R}^p\) が線型分離可能であるとき,ハードマージン法と呼ばれる手法を用いて,これを分離する最大マージン超平面 \[ H_\mathrm{max}:=\operatorname*{argmax}_{H\subset\mathbb{R}^p}\min_{1\le i\le n}d(x_i,H) \] を,凸二次計画問題を解くことによって見つけることができる.このとき,最大のマージンを達成する \[ d(x_{j},H)=\min_{1\le i\le n}d(x_i,H) \] ときの \(x_j\) (複数あり得る)をサポートベクトル といい,これが解 \(H_{\text{max}}\) を特徴付ける.
この問題において,特徴写像 \(\Phi:\mathbb{R}^p\to H_k\) を考えても,やはり解を \(n\) 次元部分空間 \[ v\in\left\{\sum_{j=1}^nc_j\Phi(x_j)\in H_k\;\middle|\;c_j\in\mathbb{R}\right\} \] 上で考えれば良いから, \[ \underset{v,\gamma}{\text{minimize}}\quad\|v\|^2_{H_k}=\sum_{i,j=1}^nc_ic_jk(x_i,x_j) \] \[ \text{subject to}\quad\lambda_i\left(\sum_{j=1}^nc_jk(x_i,x_j)+\gamma\right)\ge1\quad(i\in[n]) \] という,やはり凸二次計画問題を解けば良い.
歴史と題した第 1.2 節は (Ghojogh et al., 2021) も参考にした.
一方でここにきて,現代におけるDNNの最先端とも言えるTransformerをSVMとみなせる,という報告も出てきた (Tarzanagh et al., 2023)↩︎
このようにして構成される行列をGram行列と呼ぶ.↩︎
(Aronszajn, 1950) 参照.↩︎