トランスフォーマー
深層生成モデル1
2024-02-20
A Blog Entry on Bayesian Computation by an Applied Mathematician
$$
$$
深層学習とは,多層パーセプトロンを用いた機械学習の手法をいう.
(McCulloch and Pitts, 1943) は脳の神経回路を命題論理の枠組みで扱い,ニューロンの論理素子としての機能を考察した(McCulloch-Pitts の形式ニューロンや閾素子と呼ばれる).なお,パーセプトロンはシグモイド関数を活性化関数に用いた場合,Turing 完全である (Siegelmann and Sontag, 1991).
脳を模したモデルとして,当然学習能力をどうモデルに組み込むかが問題になる.これはシナプスの結合荷重の変化によるものだという仮設は古くからあったが,最も明確な形で表現したのが (Hebb, 1949) であった.
具体的には Hebb 則は,2つの正の相関を持つ(=共起しやすい)ニューロンの間の荷重は増強される,というものである.1 これは連想記憶のモデルとして提案された(第 2.7.1 節も参照).
パーセプトロンは,脳の記憶と認識のモデルとして,(Rosenblatt, 1958) が心理学の学会誌に発表した.2
複雑過ぎるものに対する理論解析は進まなかった.
そのような中で (Minsky and Papert, 1969) は線型分離不可能な問題に対しては線型単純パーセプトロンは解を見つけられないほど機能は劣り,かといって複雑なものは計算量が爆発するので,結局パーセプトロンは使い物にならないのではないかとの見方を示した (甘利俊一, 1989, p. 130).
現状の深層学習の成功を見ている者からすれば,これだけのことでパーセプトロンの研究が下火になってしまったことは驚くべきことに感じる.
(甘利俊一, 1989) はこの点を,次のように断罪している.
ミンスキーらは,自分たちの立てた問題は正しく解いた.しかし問題の立て方を誤ったのである.(甘利俊一, 1989, p. 132)
パーセプトロンの発明の時点で,深層学習のモデルとしてはすでに完成していた.ただ,(Minsky and Papert, 1969) の指摘の通り,計算複雑性や学習アルゴリズムの問題が残り続けた.
多層のパーセプトロンでは中間層を学習させることが課題であった.これに対しては,活性化関数に可微分なものを用いて確率的勾配降下法によって学習させることで解決できること (Amari, 1967) などは早い時期から議論されていた.この問題点は,局所解に囚われることであった.
多層のパーセプトロンに対して,局所解に囚われるなどの問題はあれど,極めて多くの場合で誤差逆伝播法が有効な学習法になることが広く周知されたのは,(Rumelhart et al., 1986), (Rumelhart et al., 1987) であり,これが深層学習の第二次ブームの着火剤となった.3
すぐさま英語の発音を学習させた研究 (Sejnowski and Rosenberg, 1987) の デモ も発表され,大きな波紋を呼び起こした.ここでも特徴的な内部表現が観察された.
局所解に囚われることが解決された訳ではない.技術的な問題点(特に,結局深層モデルの訓練はうまくいかないこと)はあれど,ニューラルネットワークは実用的に極めて簡単に使えるモデルであると知らしめたのである.
In short, we believe that we have answered Minsky and Papert’s challenge and have found a learning result sufficiently powerful to demonstrate that their pessimism about learning in multilayer machines was misplaced. (Rumelhart et al., 1987, p. 361)
現在は,ドロップアウト や区分的線型な活性化関数 ReLU を用いるなどの工夫がなされている (Goodfellow et al., 2014).
誤差逆伝播法をニューラルネットに使うことで,表現学習がなされることの発見 (Rumelhart et al., 1986) から,深層学習の分野は次の点で変化したという:
しかし,画像識別タスクに特化して結合構造を予め作り込むことで学習を容易にしてある畳み込みニューラルネットワーク (CNN) (LeCun et al., 1998) などを除いて,2層以上のニューラルネットワークの成功した応用例は殆どなかった.これは,勾配消失 により,どんなに多層なニューラルネットワークを構築しても,最後の2層程度しか意味のあるパラメータを学習できなかったためである.
そのために,多層のニューラルネットワークでは表現学習は難しいという認識が広まり,複雑なタスクに対しては,問題固有の特徴抽出技法が編み出されるのみで,一般的な解決法はなかった.
3層のニューラルネットワークも,隠れ層の幅が無限大の極限で,任意の連続関数を近似できるという普遍近似定理という抽象的な慰め (Hecht-Nielsen, 1989) があるのみであった.
そこで多くの研究者は,SVM (Cortes and Vapnik, 1995) やカーネル法,Gauss 過程に現実的な打開策を求め始めたのである.これは冬の時代とも呼ばれる.
(Wiesel and Hubel, 1959) は猫の視覚野には,単純細胞と複雑細胞の2種類の細胞があることを発見した.また,生後すぐの猫を一日交代で異なる片目を覆って成長した猫では,多くの視覚野の神経細胞は単眼性になる (Hubel, 1967).
これらの観察から,(von der Malsburg, 1973) や (Fukushima, 1975) は,特徴抽出細胞が自己形成するメカニズムを,自己組織化のキーワードの下で調べた.特に後者は コグニトロン というモデルを提案した.
(Fukushima, 1980) の ネオコグニトロン は初の深層モデルの例と言える.5 これは,単純細胞層と複雑細胞層を交互に深く重ねたネットワークである.
しかし 福島 は学習の問題を中心に扱った訳ではなかった.6 (LeCun et al., 1998) の畳み込みニューラルネットワーク LeNet は,ネオコグニトロンを誤差逆伝播法により教師あり学習させたものと言える.
このモデルは後に AlexNet としてダントツの性能で世界を驚かせることになる.
画像データはピクセルを節としたグラフデータとみなすこともでき,CNN を一般化する形で GNN (Graph Neural Network) も提案されている (J. Zhou et al., 2020), (Wu et al., 2021), (Veličković, 2023).
(Cottrell and Munro, 1988) は中間層の幅を小さくし,入力信号自身を教師信号として誤差逆伝播法により学習することで,隠れ層に入力の低次元表現が学習され,主成分分析に用いることが出来ることを報告した.
これは入力層と出力層の素子数を一致させ,出力が入力に近づくように訓練される.このようなモデルを 自己符号化器 (autoencoder) または 自己連想ネットワーク (auto-associative neural network) と呼ぶ.
内部表現を獲得するとされる中間層に対して,それより前半の層全体を符号化器,それ以降を復号化器と呼ぶ.7
(Baldi and Hornik, 1989) は活性化関数がない3層の場合,自己符号化器を訓練させることは主成分分析を実行することに等価であることを示した.
さらに層を増やすことで,非線型な次元圧縮が可能であることが (DeMers and Cottrell, 1992) で示された.この論文では,データの空間内の(非線型な)部分多様体の局所座標が学習されたり,人間の顔の写真のデータ圧縮が出来ることが実証されている.
自己符号化器はスタッキングが可能である (Ballard, 1987).このことが,次の節で述べる事前学習のアイデアに繋がる.
自己符号化器自体を符号圧縮と表現学習に用いることは,他の手法と比べて特別優れているという訳でもなかった.
しかし,深層ニューラルネットワークを 層ごとに事前に教師なし学習をする ことで,後の教師あり学習において勾配消失などの問題が回避できるというアイデア (Hinton and Salakhutdinov, 2006), (Hinton et al., 2006) は画期的であり,深層学習 (Deep Learning) という言葉が広まったのもこの頃であるという (Schmidhuber, 2015, p. 96).8
入力に近い方から,1層ごとに,前層の出力を入力として自己符号化器と見て訓練するのである (Bengio et al., 2006).(Larochelle et al., 2007) はこの事前学習によって,素性の良い局所解の近くにパラメータの初期値が調整されるということを実験的に示している.
この発見は深層模型の訓練を可能にするという大きなブレイクスルーを,教師なしの表現学習と教師あり学習による調整とに問題を分離して解くことによって成し遂げたと言える.
また,単純な自己符号化器の代わりに,ノイズが加えられたデータを入力しこれを復元するようにに学習する denoising autoencoder を用いた方が,深層モデルにより良い初期値を与える潜在表現を獲得できることが報告されている (Vincent et al., 2008).9
ImageNet データベース (Deng et al., 2009) を用いた判別コンテスト ILSVRC (the ImageNet Large Scale Visual Recognition Challenge) で,ダントツで優勝した AlexNet (Krizhevsky et al., 2012) が大きなターニングポイントとなった.
これも (LeCun et al., 1998) の CNN を基にした8層のモデルで,活性化関数には ReLU とドロップアウトによる正則化が用いられていた.学習も,NVIDIA 社の GPU を用いていた.
20 層以上の多層ニューラルネットワークの学習の困難さを初めて解決したのが (He et al., 2016) の Residual Network (ResNet) であった.10
このモデルは 152 層もあったが効率的に訓練することが可能で,2015 年の ILSVRC でダントツで優勝し,しかも初めて人間の誤答率 5% (Dodge and Karam, 2017) を下回ったのである.
そのアイデアは,各層の入力 \(x\) を出力に再度加算した形 \[ y=x+F(x) \] で各層をデザインし,現状の入力からの差分 \(F\) のみを学習するとすることで勾配消失を回避する,というものであった.実際,この層の微分は \[ \frac{d y}{d x}=1+F'(x) \] と表せる.
このテクニックは トランスフォーマー (Vaswani et al., 2017) などのモデルでも用いられている.
(Li et al., 2018) によると,残差レイヤーの追加は誤差関数を滑らかにし,近しい入力に対しても勾配が非常に大きくなってしまうことが効率的な学習を阻害してしまう問題 (shattered gradient problem) (Balduzzi et al., 2017) を解決している,という.
ニューラルネットワークは,内部に循環を持つかどうかで二分され,それぞれを Feedforward Network (FFN) と Feedback Network (FBN) と呼ぶ.11
FFN は 多層パーセプトロン (MLP) ともいう.12
Recurrent Neural Network (RNN) 2.4 や Hopfield ネットワーク 2.7.1 は FBN の例である.
多層パーセプトロンは分類や回帰などの統計学的な用途に主に用いられるが,FBN は学習機械として以外に,生物の神経機能のモデルとしてや,組合せ最適化ソルバーとしても用いられる.13
CNN はその畳み込み層に特徴付けられる画像に特化した FNN アーキテクチャである.
第 4 節で詳しく扱う.
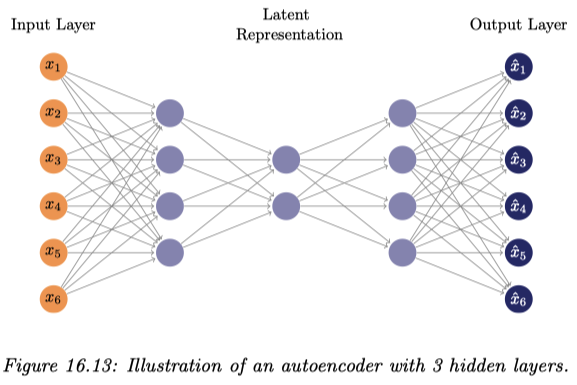
自己符号化器または自己連想ニューラルネットワーク (auto-associative neural network) 1.2.3 は図のような砂時計型の,入力 \(x\) と出力 \(y\) の次元数が一致したアーキテクチャを持ち, \[ \mathcal{L}(\theta)=\|y-x\|^2_2 \] などの入力の復元誤差を目的関数として訓練される.
再帰的な層を持ち,自己回帰モデル 3 を実装する FBN の例である.
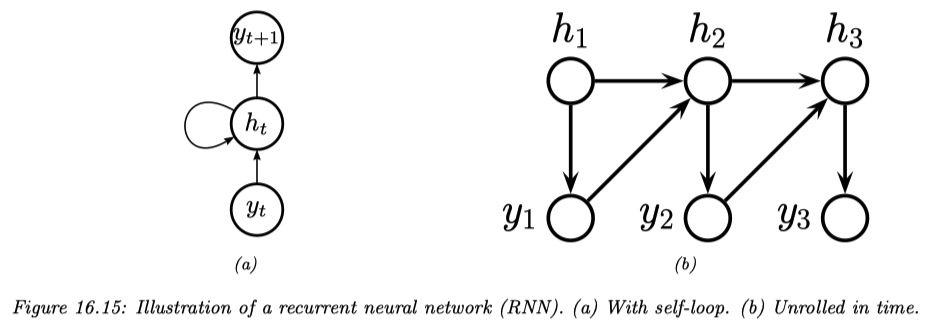
第 3.2 節でも詳しく扱う.
RNN の最大の難点は,隠れ次元 \(z_t\) が \(x_{1:t}\) までの入力の要約になっており,\(x_1\) などの最初の方の情報がどんどん薄れていく点にある.
そこで,時点 \(t\) でも \(x_1\) など以前の情報にワンステップでアクセスできるような機構である 注意機構 が考案された.これがエンコーダーのみのトランスフォーマーである.
デコーダーのみのトランスフォーマーは masked attenstion という技術を用いて \(x_{1:t-1}\) のみで条件づけて \(x_t\) を生成することができる.
一方で,入力全体で条件づけて,文章を生成することもでき,これが最初に (Vaswani et al., 2017) によって提案された,最も一般的な形の encoder-decoder トランスフォーマーである.
従来の NN は辺の存在しない退化したグラフに対するものだとして,NN を一般のグラフデータに対して拡張することが近年考えられている.
無向グラフが定めるニューラルネットワークは,エネルギーベースモデル (EBM: Energy-Based Model) で主に用いられる.
計算機の記憶と生物の記憶の相違点のうち,大きなものには連想性 (associativity) がある.アドレスで整理されているのではなく,内容で整理されているのである.1970 年代には,神経の連想記憶機能のモデルとしてのニューラルネットワークが多数提案された.
それには,ここまで議論してきた階層型のネットワークと異なり,ノード同士は 相互結合 しているものも含まれる.連想記憶のモデルとしては,特に相互結合で,どちらの方向に関する重みも同じであるもの(対称結合 ネットワーク)が多く,全結合の FBN である Hopfield network はその代表例である.14
(連続変数の)Hopfield network の学習則は,Hebb 則 (Hebb, 1949) に基づいて,各ニューロン \(x_j\in[0,1]\) についてその入力 \[ a_i:=\sum_{j}w_{ij}x_j \] を計算し,\(x_i\gets\tanh(a_i)\) と更新する.
実はこの学習則は必ず収束する.このことを,(Hopfield, 1982) はスピングラスのモデルと関連付けて示したことから,特に統計物理学の文脈で Hopfield network の名前がついた.15
神経回路網の解析,とくに連想記憶モデルの解析が,スピングラスを解析する方法を用いて実行できるのではないかという考えが出てきて,大量の物理学者が神経回路網に注目しだした.こうしたアイデアの火付け役がホップフィールドと言われる.(甘利俊一, 1989, p. 105)
対称結合のニューラルネットワークの学習則は,スピングラスと同様に,必ずポテンシャル関数が減少する方に動作するというのである.この連関を利用して,(Hopfield and Tank, 1985) は Hopfield ネットワークをアナログ回路に実装し,巡回セールスマン問題を解くという,最適化問題ソルバーとして利用してみせた.
単体 Hopfield Network (Burns and Fukai, 2023) という拡張もあり,パラメータ数は変わらずとも記憶容量が増える.
ボルツマンマシンは確率的 Hopfield ネットワークともいい,Hopfield ネットワークが統計物理のモデルとして近似するところの Gibbs 分布を,実際に持つ Markov 確率場 の一種である.16
これは,荷重を,確率 \(\frac{1}{1+e^{-2a_i}}\) で \(x_i=1\),そうでない場合は \(x_i=-1\) と定めることで得られる.
これは深層学習研究の皮切りになった確率的深層モデルである.
実際の神経細胞は 発火 という離散的なイベントを発生させ,その頻度やタイミングも大きな役割を持っている.これを取り入れたモデルを Spiking Neural Network (SNN) (Maass, 1997) と呼ぶ (岡島義憲, 2020).
SNN は現状の人工ニューラルネット (ANN: Artificial Neural Network) よりも,半導体上での計算を効率化することが出来る.そこで,SNN による深層学習が近年試みられている (Tavanaei et al., 2019).
Microsoft の BitNet (Wang et al., 2023) も計算効率性を目指すにあたってそのアイデアを等しくする.
良い汎化性能を得るためには,偏倚と分散のトレードオフ を乗り越える必要がある.
データセットに対してモデルの自由度が高すぎると,分散は小さくなれど,過学習を起こしてしまう.すなわち,大きなバイアスが導入され,汎化性能が悪くなる.一方で,モデルの自由度が低すぎると,平均的には正しい予測ができても,分散が大きくて役に立たない.
大規模なデータセットを用いることは一つの解決である.自由度の高いモデルを用いても過学習が起こりにくくなるためである.17
正則化とは,モデルの自由度を制限することで過学習を抑制することである.これは,「正しいモデルは十分に滑らかであるはずである」という帰納バイアスを導入することで,モデルの汎化性能を改善させていることに等しい.18
転移学習も一種の帰納バイアスの注入だと見れる.2つの異なるタスクの間に類似性が存在するという事前知識を注入することで,汎化性能を改善する手法だと思えるのである.
汎化性能の高いモデルを作るということは,人類が解きたいタスクに普遍的に共通する特徴を捉え,これを帰納バイアスの形でモデルに注入することに等しい.No free lunch theorem (Wolpert, 1996) から,19 一般に特定のタスクに対する性能向上は,他のタスクに対する性能低下を伴うものであることが予想されるが,例えば推定関数が十分滑らかであるというのは,人間の認識特性上,有意義な結果にはほとんど普遍的に必要な条件である.
(Gal and Ghahramani, 2016) などでは,
と説明される.
CNN は特に過学習しやすい上にサンプル効率性が悪い.その場合には,変分近似による Bayesian CNN は既存法と同等の性能を誇る (Gal and Ghahramani, 2016).
長さ \(T\) のデータベクトルをモデリングするとき, \[ p(x_{1:T})=\prod_{t=1}^Tp(x_t|x_{1:t-1}) \] という分解を用いることができる.このようなアプローチを機械学習では 自己回帰モデル という.20
しかし,このようなモデリング法は \(T\) が大きくなるにつれて,条件づける変数 \(x_{1:t-1}\) が高次元になるため,モデリングが難しくなる.
かと言って,\(\{x_t\}_{t=1}^T\) を Markov 連鎖とみなしてモデリングするわけにもいかない.
一つの解決法が 状態空間モデル / 隠れ Markov モデル によるものである.\(x_{1:t}\) はある状態変数 \(z_t\) にある既知の確率法則で圧縮できると仮定し,これのみを持ち越す方法である.
特に,\(X_{1:t-1}\to Z_t\) の対応が決定論的であるとき,これを多層パーセプトロンによってモデリングしたものを 再帰ニューラルネットワーク という.
\(x_t=f(z_{t-1},x_{t-1})\) の関係を学習した後は,\(x_1\) から再帰的に \(f\) に通すことでデータ \(x_{1:T}\) を生成する.
AR モデルは尤度を効率的に扱えるため,計算や最適化が簡単である.実際,RNN や CNN などの自己回帰モデルが,歴史上最初に発達したアーキテクチャである.
一方で,データの生成が逐次的であるために生成が遅いことや,内部で潜在表現を学習するということがないために表現学習に使うことができない点が欠点と言える.21
CNN はトランスフォーマーによりデータ間の関係を自動的に学習する枠組みが提案される前に,主に画像分野において,データの構造に関する事前知識をモデルに組み込んだ例として提案されたものである.
世界初の深層学習モデルによる席巻は,CNN により,画像認識の分野において達成された.
Computer Vision という問題の複雑性が,ニューラルネットワークのアーキテクチャの開発を後押しした歴史がある.
並行移動・拡大変換という2つの合同変換不変性に対して,画像の認識結果は不変であるべきである.
このような不変性,または 同変性 (equivariance) をモデルに取り入れる方法は大きく分けて4つある:
CNN は4番目のアプローチで歴史上最初に取られたものである.しかし,このどのアプローチも完全には不変性を取り入れることは出来ていないことも報告されている (Azulay and Weiss, 2019).
幾何学を種々の変換に対する不変性の研究と捉え直した Felix Klein の Erlangen program に倣い,種々の深層モデルの帰納バイアスとアーキテクチャを,幾何学的な変換から導出してシステマティックに理解する試み Geometric Deep Learning (Bronstein et al., 2021) がある(第 4.6 節).
CNN は画像の特徴を,階層的に学習出来るように誘導するような構造を持っている.
多くの例では,畳み込み層とプーリング層が交互に繰り返され,最後に全結合層を持つような構造を持っている.
最初の素子は,画像の局所的な一部のみを入力として取る.その範囲を 受容野 (receptive field) と呼ぶ.この素子の荷重を フィルター または カーネル という.
決まったカーネルに対して,この素子はカーネルの特徴にマッチした入力に対して,大きな出力を返す.
次に,このフィルターを畳み込むことで,画像内の異なる位置に存在する特徴を検出する.畳み込み層は,荷重を共有した疎結合層ということになる.
畳み込みを行うと,入力次元と出力次元が変わってしまうことがあるため,その場合は入力画像にパディングを施す.
出力次元を小さくして,畳み込み特徴写像で大きな次元削減を行いたい場合,strided convolution を用いる.
畳み込みの結果が,特徴の位置の変化に対して不変になるようにする設計に,プーリング層 または ダウンサンプリング層 (down-sampling / sub-sampling) がある.
プーリングも,受容野を持った素子と畳み込みからなるが,畳み込みに学習されるべきパラメータはなく,確定的な関数と畳み込まれる.
代表的なプーリング関数には 最大プーリング (Y. Zhou and Chellappa, 1988) や平均プーリング,\(l^2\)-プーリングなどがある.
プーリングは不変性の導入に加えて,畳み込み特徴のダウンサンプリングを行って,更なる次元削減を行う役割も果たす.
画像分類では,1枚の画像に対して1つのクラスの対応づけたが,1つのピクセルに1つのクラスを対応づけることで,画像をクラスごとに分類することが考えられる.
画像分類の問題では,最終的に全ピクセルから得た情報を1次元に圧縮することになる.一方で,十分な潜在表現を得たのちは up-sampling に転じる Encoder-Decoder 構造にすることで,最終的に元の画像サイズに戻しながら,画像分割問題を解くことが出来る (Long et al., 2015), (Noh et al., 2015), (Badrinarayanan et al., 2017).
(Badrinarayanan et al., 2017) は max-unpooling などの up-sampling 層の設計を考慮したが,これに学習可能なパラメータを増やした transpose convolution / deconvolution も提案された.
Pooling 層を一切用いず,down-sampling も up-sampling も畳み込み層のみによって行われる場合,これを 全畳み込みネットワーク (fully convolutional network) という (Long et al., 2015).
この encoder-decoder 構造は,分類に必要のない情報を自動的に削減し,モデルのサイズを小さくするのには効果的であるが,タスクによっては元の画像の情報量を保ちたい場合がある.
U-net (Ronneberger et al., 2015) は対応する down-sampling 層と up-sampling 層とを直接繋ぐ経路を追加することでこれを解決した.
プーリング層は並行移動不変性の概念を取り入れるが,回転や拡大などの変換に対する不変性を取り入れるにはデータ拡張に依るしかないのでは,CNN の学習はどうしても大規模なデータセットが必要になってしまう.
そこで,アーキテクチャによる解決を試みたのが,畳み込み層に加えて カプセル層 を取り入れた Capsule Network (Sabour et al., 2017) である.
CNN において,最初の方のレイヤーは局所的な特徴を捉えているが,後の方のレイヤーはスタイルなどの大域的な特徴を捉えている.
これを用いて,既存の画像の具体的な特徴を変えずに,他の画像からスタイルのみを転移する手法 Neural Style Transfer が提案された (Gatys et al., 2015), (Gatys et al., 2016).
以上,種々のタスクに種々のアーキテクチャが存在することを見てきた.この状況は,19 世紀の幾何学と似ていると (Bronstein et al., 2021) はいう.
これらのアーキテクチャがどのような帰納バイアスを導入する役割を果たしているかを,不変性や同変性といった第一原理から理解する試みが 幾何学的深層学習 である.
In this text, we make a modest attempt to apply the Erlangen Programme mindset to the domain of deep learning, with the ultimate goal of obtaining a systematisation of this field and ‘connecting the dots’. We call this geometrisation attempt ‘Geometric Deep Learning’, and true to the spirit of Felix Klein, propose to derive different inductive biases and network architectures implementing them from first principles of symmetry and invariance. (Bronstein et al., 2021, p. 2)
化学・生物・物理はいずれも対象の対称性をしっかり扱う理論を持っている.これらの分野に深層学習が広く取り入れられつつある今,深層学習の分野も対称性を第一原理として整理される脱皮が待たれているのである.
Mikhael Gromov によると,空間 \(X\) の解析学とは \(X\) 上の関数の研究で,\(X\) の幾何学とは \(X\) への関数の研究である (深谷賢治, 1997, p. 11).

同変性と共変性は,データ集合 \(X\) と群作用 \(\rho:G\times X\to X\) との組 \((X,\rho)\) を取り扱うから,確かに上述の定義に適っている.
物体認識 Section 4.2 は不変的で,画像分割 Section 4.3 は同変的な問題である.
ただし,不変性は,\(G\) の \(Y\) への作用が自明である場合の同変性と見れるため,同変性の方が一般的な概念であることに注意.
一般の群変換に対して,これを帰納バイアスとして取り入れる CNN である Group CNN (T. Cohen and Welling, 2016) が提案されており,医療画像解析での応用 (Lafarge et al., 2021) もなされている.
Steerable CNN ではチャンネルの間での対称性を取り入れることができる.
(Weiler et al., 2018) により最先端の性能が発揮されている.
もはやニューラルネットワークは,layered differentiable model (Oord et al., 2019) と呼んだ方がその数学的な存在をよく表すだろうと思う.
(MacKay, 2003, p. 506) など.↩︎
入力層と中間層と出力層の3層のみからなるものモデルを単純パーセプトロンと呼ぶが,それだけでなく,多層のものや,フィードバック結合のあるものも含む,一般的な形で考えていた.↩︎
オートエンコーダーを導入し,中間層で表現学習がなされること(最も幅の狭い中間層の活性化を通じてコンパクトに表現する,など)と,モーメンタムが学習を加速することを示している (Rumelhart et al., 1987, p. 330), (Schmidhuber, 2015).「バックプロパゲーションがこの流行の起爆剤となったとさえ言える」 (甘利俊一, 1989, p. 144).↩︎
(Schmidhuber, 2015), (Bishop and Bishop, 2024), (麻生英樹 et al., 2015) を参考.↩︎
教師なしの競合学習を試みたのみであった (麻生英樹 et al., 2015, p. 21).↩︎
三層の場合は,入力層を符号化器,出力層を復号化器とも言う.さらに中間層の幅が小さい場合,その形から hourgalss-type neural network とも呼ばれる (麻生英樹 et al., 2015, p. 91).↩︎
さらに,Hinton らが示した成功は,深層信念ネットワークは制約付き Boltzmann マシン (RBM) として各層が事前訓練されたが,これが denoising autoencoder と似たノイズへのロバスト性を示すために起こったものではないかと予想している (Vincent et al., 2008) 第6節.↩︎
当時の CNN で深かったものには,19 層の CNN である VGGNet (Simonyan and Zisserman, 2015) がある.↩︎
(MacKay, 2003, p. 505),(Murphy, 2023, p. 633) 16.3.1節など.↩︎
(Murphy, 2023, p. 632) 16.3.1節など.↩︎
(MacKay, 2003, p. 468) の導入も参照.↩︎
(MacKay, 2003, p. 503) 第42章,(麻生英樹 et al., 2015, p. 11) など.↩︎
「このため,物理学者はこの種のモデルのことを Hopfield モデルと呼ぶが,この命名は適切とは思えない」(甘利俊一, 1989, p. 97) としている.↩︎
“The popularity of the Boltzmann machine was primarily driven by its similarity to an activation model for neurons.” (Koller and Friedman, 2009, p. 126).↩︎
(Wolpert, 1996) は最適化の文脈での定理を示した.統計的機械学習の文脈での No free lunch theorem は,“Any classifier with finite sample error guarantees necessarily needs inductive bias: structural assumptions on either the function class or the sampling distribution.” と説明できる.(Shalev-Shwartz and Ben-David, 2014, p. 37) 定理5.1 も参照.↩︎
(Murphy, 2023, p. 811) 22章など.↩︎
(Murphy, 2023, p. 812) など.↩︎
tangent propagation (Simard et al., 1991) などがその例である.2の例とも見れる.↩︎
(福水健次, 2024), (Bronstein et al., 2021, pp. 15–16) など.または nLab も参照.↩︎