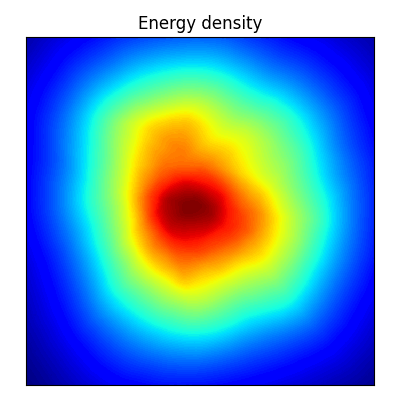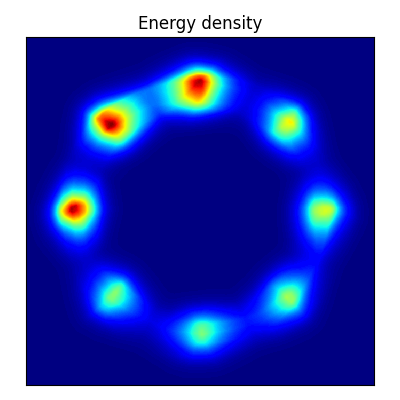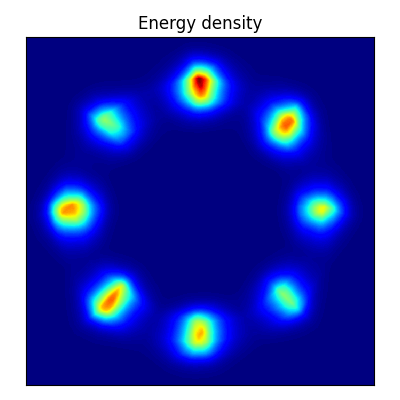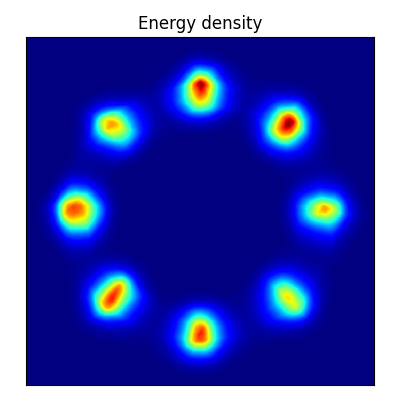
スコアマッチング
JAX によるハンズオン
2024-08-02
A Blog Entry on Bayesian Computation by an Applied Mathematician
$$
$$
エネルギーベースのモデル (EBM: Energy-based Model) とは,密度が \[ p(x,z)\,\propto\,e^{-H(x,z)} \] の形で与えられるモデルをいう.1
これは統計物理学的な系との対応が意識されているように,入力 \(z\) と出力 \(x\) の整合性 \(k(x,z)\) をエネルギー \(H(x,z)\) の言葉で与えているモデルであると見ることができ,このエネルギー \(H\) をニューラルネットワークによってモデル化するのである.
すると EBM の最尤推定とは,訓練データ \(\{x_i\}_{i=1}^n\) に対して最も低いエネルギーを割り当てるエネルギー関数 \(H_\theta\) を探すという基底状態探索の問題に対応する (LeCun et al., 2007).
これで EBM の概要は終わりであるが,このような極めて一般的な設定で有用な一般論が得られることは驚くべきことである.
VAE や 正規化流 などの生成モデルや,トランスフォーマー などの自己回帰モデルも EBM とみなせる.
特にこれらの生成モデルを事後調整しようと思うと,自然に EBM の構造が出てくる.例えば,LLM における RLHF などの事後調整は,生成モデル \(p(x|z)\) とある目的関数 \(\phi\) に関して \[ p'(x|z):=\frac{1}{Z(z)}p(x|z)\phi(z) \] によって分布を調整する営みであると見ると,やはり正規化定数を除いた分布族が定まる (Zhao et al., 2024).2
Markov 確率場などの無向グラフィカルモデルで定義される分布族や,正規化定数を除いて定義された確率分布族は,自然に EBM とみなせる.3
初期の研究 (Zhu and Mumford, 1998), (Zhu et al., 1998) では画像への応用を見据えて,浅い EBM を MCMC により推定している.
(Hinton and Teh, 2001) で論じられている通り,音声や画像などのデータに対する独立成分分析では,DAG などの有向グラフによるモデリングでは正確な推論ができないため,無向グラフによるより良いモデリング法が 積スパートモデル (PoE: Product of Experts) などを通じて探求されていた.
例えば Ising 模型の一種でもある Hopfield ネットワーク (Hopfield, 1982) と Boltzmann 機械 (Ackley et al., 1985) は最も有名な EBM の1つである.4
しかしこの場合,分配関数 \(Z_\theta\) の計算が難しく(ほとんどの統計力学模型の中心問題である),EBM を訓練することが難しかった.
このようなモデルに対する最初の実用的な訓練手法(というより SGD の目的関数)は,Boltzmann 機械に対して与えられた Contrastive Divergence (Hinton, 2002) であった.
これ以降正規化定数が不明である模型も効率的に訓練可能であることが周知され,ICA に応用した論文 (Teh et al., 2003) で “Energy-based Model” の名前が造語された.
制約付き Boltzmann 機械に対する greedy, layer-by-layer の事前学習を取り入れることで,深層化しても訓練が効率的に行われるようになった (Hinton et al., 2006), (Hinton and Salakhutdinov, 2006).
しかしこの方法により訓練されたモデルは深層信念機械というべきものであり,一般的な Boltmzmann 機械とは違った.深層 Boltzmann 機械の訓練法は (Salakhutdinov and Hinton, 2009) で確立された.
画像生成の分野においても,生成 CNN (generative ConvNet) (Xie et al., 2016) 以降,\(H_\theta\) のモデリングには深層の CNN が用いられるようになっていった.
エネルギーベースモデルでは,分布は正規化定数を除いて定まっており, \[ Z_\theta:=\int e^{-H(x,\theta)}dx \] も既知ではないとする.この点が EBM の表現力を支える自由度の高さであるが,5 EBM の訓練にあたっては \(Z_\theta\) の推定というタスクが増える.
これが 自己回帰モデル や フローベースモデル との最大の違いである.
また,GAN や VAE も含めた生成モデルでは,生成のタスクが念頭にあるためにモデルを有向グラフによって表現するが,EBM はより一般の状況も考える広いクラスだと言える.
\(Z_\theta\) の推定という追加のタスクには,典型的には MCMC が用いられ,最尤推定 2 が完遂させられるが,近年スコアマッチング(第 3 節)や ノイズ対照学習 などの新たな手法が提案されている.
仮に,2つの学習済みモデル \(p_1(x),p_2(x)\) が EBM の形で得られており,それぞれのエネルギーが \(H_1,H_2\) で与えられるとする.この際,\(H:=H_1+H_2\) をエネルギーにもつ EBM は \(p\,\propto\,p_1p_2\) であり,このモデルは \(p_1\) でも \(p_2\) でも高確率であるような \(x\) を高く評価することになる.
このようにして得るモデル \(p\) を 積スパートモデル (PoE: Product of Experts) (Hinton, 2002) という.6 (Hinton, 2002) は引き続き,対照分離度 (contrast divergence) 2.3 による訓練法を提案している.
例えば (Murphy, 2023, p. 840) では,タンパク質構造の生成モデルを作りたいとして,\(p_1\) を「常温で安定であるタンパク質」の生成モデル,\(p_2\) を「COVID-19 のスパイクタンパク質に結合するタンパク質」の生成モデルとして説明している.
従ってこの \(H\) は,データの好ましさを表すパラメータと考えられ,他モデルへの移転にも使えることが期待される.\(H\) は,contrast function, value function, 負の対数尤度などとも呼ぶ (LeCun et al., 2007, p. 193).
2次元の密度推定に対して,FCE (Flow Contrastive Estimation, 第 4.5 節) により学習させた EBM は,正規化流 よりも遥かに小さいネットワークサイズで高い性能を示した (Gao et al., 2020).
Contrastive Divergence 2.3 は漸近的に消えないバイアスを持つ (Carreira-Perpiñán and Hinton, 2005) が,SM 3 と NCE 4 は一致推定量である.
CD 2.3 は最尤推定を SGD によって実行するために建てられた代理目標である.
近似が入っているために消えないバイアスがある.
スコアマッチング(第 3 節)のアイデアは,データ分布の密度 \(p(x)\) とモデル \(p_\theta(x)\) とのスコア関数をマッチングさせることを狙う: \[ \nabla_x\log p(x)=\nabla_x\log p_\theta(x). \] このとき,両辺を積分すると,正規化条件から \(p(x)=p_\theta(x)\) が従う.
この考え方は EBM だけでなく,尤度の評価は困難でも対数尤度の評価は可能である文脈で普遍的に有効である.
例えば 自己符号化器 においても用いられるアイデアである (Vincent, 2011), (Swersky et al., 2011).
NCE 4 は,表現学習や深層距離学習で用いられる 対照学習 を,特にノイズと対照させることで最尤推定に応用したものである.
EBM は,データの分布との KL 乖離度,または等価なことだが対数尤度の期待値 \[ \operatorname{E}[\log p_\theta] \] を最小化することによって学習することが考えられる (LeCun et al., 2007).
しかし尤度の評価は正規化定数 \(Z_\theta:=\int e^{-H_\theta(x)}\,dx\) の評価が必要であるため,一般の設定では実行できないが,勾配 \[ \nabla_\theta\log p_\theta(x)=-\nabla_\theta H_\theta(x)-\nabla_\theta\log Z_\theta \tag{1}\] は近似できる.\(\nabla_\theta H_\theta(x)\) はニューラルネットワークの自動微分で計算することができ,2項目は \[ \nabla_\theta\log Z_\theta=-(p_\theta|\nabla_\theta H_\theta) \] の関係を用いて,\(p_\theta\) からのサンプルを用いた Monte Carlo 推定量で評価できる (Younes, 1999).
正規化定数の不明な密度 \(p_\theta\) からのサンプリングといえば,MCMC と SMC である.この Monte Carlo 近似を通じて,確率的勾配降下法によって最尤推定が実行できる.
この際の Monte Carlo 推定には,多少バイアスがあっても高速に収束してくれる MCMC が欲しい.そこで提案されたのが 確率勾配 Langevin 動力学 である.
これは (Hyvärinen, 2005) のスコア関数7 \[ \nabla_x\log p_\theta(x)=-\nabla_x H_\theta(x) \tag{2}\] の値から情報を得て,\(x\) の空間上で効率的な Markov 連鎖のダイナミクスを構成する方法である.
\(H_\theta\) の勾配が急であればあるほど高速に収束するが,Zig-Zag サンプラー などの PDMP 手法の方が高速に収束する.
SGD の各ステップに Monte Carlo 推定が必要であるが,毎度 MCMC を十分な数だけ回して,十分に分散が小さい勾配の推定量を得る必要はない.
このように,系統的に MCMC を打ち切って,手早く計算された勾配の推定量を通じて SGD により最尤推定を行う方法 (short-run MCMC) の代表的なものに,対照分離度 (CD: Contrastive Divergence) (Hinton, 2002) がある.
CD による訓練では,バッチごとに提供された訓練データ \(x_n\) を開始地点として,一定の回数 \(T\) だけ MCMC を回す.多くの場合 \(T=1\) でさえある (CD-1 algorithm).
(Hinton, 2002) は Gibbs サンプリングが可能な潜在変数を持つ EBM モデルである制限付き Boltzmann マシン (RBM) について CD を提案した.
特に簡単な binary RBM は,次のエネルギーが定める Markov 確率場である: \[ H_w(x,z)=\sum_{d\in[D],k\in[K]}x_dz_kW_{dk}+\sum_{d=1}^Dx_db_d+\sum_{k=1}^KZ_kx_k. \] 観測 \(x_d\) を入力して学習させたとき,\(z_k\) も似たような値だった場合,それが強化されるように \(W_{dk}\) が更新されるというように,Hebb 則に則った学習が行われる.
このとき, \[ \frac{\partial }{\partial w_{dk}} H_w(x,z)=z_dz_k \] より,対数尤度の勾配 (1) の期待値は \[ \operatorname{E}[\nabla_w\log p_w(x)]=-\operatorname{E}[xz^\top]-(p_\theta(x)|xz^\top). \]
第一項はデータ \(x_n\) に対して \(x_n\operatorname{E}[z|x_n,W]^\top\) によって,第二項は \(x_n\) を初期値として \(T\) 回 MCMC を回して得られたサンプル \(x_n'\) を用いて \(x_n'\operatorname{E}[z|x_n',W]^\top\) によって推定される.
この手続きは,\(p_0\) をデータ \(\{x_i\}_{i=1}^n\) の分布として, \[\newcommand{\CD}{\operatorname{CD}} \CD_T:=\operatorname{KL}(p_0,p_\infty)-\operatorname{KL}(p_T,p_\infty) \] を最小化することに相当している.
データ点を取り替えるごとに \(p_0\) を取り替えるのではなく,\(p_0\) を以前の MCMC の終わり値から定めた場合の CD の変形を PCD (Persistent Contrastive Divergence) (Tieleman, 2008), (Tieleman and Hinton, 2009) という.
確かにバッチごとに \(\theta\) がアップデートされるため,MCMC の目標分布 \(p_\theta\) は取り替える必要があるから,CD-\(T\) のように毎回新たな MCMC を回す必要があるように思えるかもしれない.しかし,\(\theta\) の更新は総じて大変小さなものであるとすると,真のモデル分布 \(p_\theta\) からはずれていくかもしれないが,1つの収束した MCMC からサンプリングし続けた方が良い可能性がある.
更に,完全に同じ MCMC を走らせ続けるというところから,リサンプリングを取り入れて \(\theta\) のアップデートに収束性を保ちながら対応することで,GAN に匹敵する性能と,分布の峰を正確に再現できるという GAN にはない美点を獲得できるという (Du and Mordatch, 2019).
一方で,正しい \(p_\theta\) によく収束する short-run MCMC が CD 法により訓練できたならば,これは効率的な生成モデルとなるかもしれない.
(Nijkamp et al., 2019) は,MCMC が EBM モデルに対置されている analysis by synthesis スキーム (Grenander and Miller, 1994) と見て,この short-run MCMC をよく学ぶことに特化したアプローチ Short-Run MCMC as Generator or Flow Model を提案した.
このアプローチでは,MCMC は毎回同じ初期分布(ノイズの分布)からスタートさせ,\(T\) の値も固定する.このようなスキームで学習された EBM は全く良い性能を持たないが,EBM から返ってくる Hyvärinen スコアを持った勾配 MCMC 法は,生成モデルとして良い性能を持つという (Nijkamp et al., 2019).
(Du et al., 2021) は,この MCMC に情報を与える Hyvärinen スコアの変化が CD 訓練の重要な要素であり,これを正確に扱うことがを安定化させることを報告した.
特にこれは,従来 CD フレームワークの目的関数が捨象していた「第三項」 \[ \frac{\partial q_\theta}{\partial \theta}\frac{\partial \operatorname{KL}(q_\theta,p_\theta)}{\partial q_\theta} \] を目的関数に含めることとして捉えられる (Du et al., 2021).ただし,\(q_\theta\) は真のデータ分布を初期分布として \(T\) ステップ MCMC を実行して得られる分布とした.
尤度 \(p_\theta\) の評価を迂回するため,GAN にヒントを得た (Finn et al., 2016),2つのネットワークを対置させて行う敵対的な学習も考えられている (Kim and Bengio, 2016).
EBM のスコア関数 (2) を \[ s_\theta(x):=\nabla_x\log p_\theta(x)=-\nabla_xH_\theta(x)\tag{2} \] と定め,データ分布 \(p\) との Fisher 乖離度を最小化するスキームが (Hyvärinen, 2005) の スコアマッチング 目的関数である: \[ D_F(p,p_\theta)=\frac{\|s-s_\theta\|_{L^2(p)}^2}{2}=\operatorname{E}\left[\frac{1}{2}\biggl|\nabla_x\log p(X)-\nabla_x\log p_\theta(X)\biggr|^2\right]. \tag{3}\]
この際,データ分布のスコア \(s(x)=\nabla_x\log p(x)\) の計算を回避することが焦点になる.
次が成り立つことがあり得る: \[\begin{align*} D_F(p,p_\theta)&=\operatorname{E}\left[\frac{1}{2}\lvert s_\theta(X)\rvert^2+\operatorname{div}(s_\theta(X))\right]+(\theta\;\text{に依らない定数})\\ &=\operatorname{E}\left[\frac{1}{2}\lvert\nabla H_\theta(X)\rvert^2-\mathop{}\!\mathbin\bigtriangleup H_\theta(X)\right]+(\theta\;\text{に依らない定数}) \end{align*}\]
この右辺はデータのスコアを含まないので,\(p_\theta\) の2階微分が計算可能ならば計算できるが,データの次元 \(d\) に関するスケールは悪い.
加えて,\(D_F(p,p_\theta)\) をここから \(\theta\) に関して微分することが困難である.独立成分分析モデルを除いて,(Köster and Hyvärinen, 2007), (Köster et al., 2009) などのニューラルネットワークモデルにも応用されたが,画像などの実データに直接適用することは困難であった.特に,\(H_\theta\) の勾配と Laplacian を解析的に計算してから実装していた.
画像データなどの量子化されたデータの密度 \(p(x)\) は可微分ではない上に,有限な台を持ってしまうためスコア \(s\) は well-defined ではない.
このような量子化されたデータ \(x\) に対して,Gauss ノイズを加えたもの \[ \widetilde{x}=x+\epsilon,\qquad\epsilon\sim\operatorname{N}(0,\sigma^2I) \] は連続なデータに変貌する(Gauss 核が軟化子として働く).
この \(\epsilon\) だけ摂動されたデータの分布 \(\widetilde{p}\) に対して,スコアマッチング目的関数 (3) は \[\begin{align*} D_F(\widetilde{p},p_\theta)&=\operatorname{E}\left[\frac{1}{2}\lvert\nabla H_\theta\rvert^2-\mathop{}\!\mathbin\bigtriangleup H_\theta+\frac{\sigma^2}{2}\|D^2H_\theta\|^2_2\right]+O(\epsilon^2)\\ &=D_F(p,p_\theta)+\frac{\sigma^2}{2}\operatorname{E}\biggl[\|D^2H_\theta\|_2^2\biggr]+O(\epsilon^2) \end{align*}\] と表せる (Kingma and LeCun, 2010).
この \(D_F\) は,Hessian \(D^2H\) の非対角項を対角項で近似し,結局は元の目的関数に対して正則化項 \[ \lambda\mathop{}\!\mathbin\bigtriangleup H_\theta,\qquad\lambda\approx\frac{\sigma^2}{2} \] を加えたもので近似できる.
これを目的関数の用いる方法が 正則化スコアマッチング (RSM: Regularized Score Matching) (Kingma and LeCun, 2010) である.
さらに (Kingma and LeCun, 2010) は,従来のように,解析的に微分が計算可能な \(H_\theta\) を採用するのではなく,誤差逆伝播を2回行う Double Backpropagation (Drucker and Le Cun, 1992) によってこの目的関数の勾配 \(\frac{d D_F(p,p_\theta)}{d \theta}\) を自動微分で計算する方法を提案した.
RSM の場合と違い,次のような表示もできる (Vincent, 2011): \[ D_F(\widetilde{p},p_\theta)=\frac{1}{2}\operatorname{E}\left[\left\|s_\theta(\widetilde{X})-\frac{X-\widetilde{X}}{\sigma^2}\right\|^2_2\right]+\mathrm{const.} \]
すなわち,ノイズ消去方向のベクトル \(\frac{x-\widetilde{x}}{\sigma^2}\) に一致するようにモデルのスコア \(s_\theta\) を学習することが考えられる.
こうすることで,\(D^2H_\theta\) の計算を回避することができる.
ただし,RSM と DSM に共通することであるが,あくまで \(D_F(\widetilde{p},p_\theta)\) はノイズの入ったデータ分布を学習してしまうのであり,\(\sigma\to0\) が志向されるが,\(\sigma\) が小さいほど \(D_F(\widetilde{p},p_\theta)\) に関する推定は不安定になる.8
SSM (Sliced Score Matching) (Song et al., 2019) ではスコアマッチング目的関数 (3) 自体を,sliced Fisher 乖離度 \[\begin{align*} D_{SF}(p,p_\theta)&=\operatorname{E}\left[\frac{1}{2}\biggr(V^\top s(X)-V^\top s_\theta(X)\biggl)^2\right]\\ &=\operatorname{E}\left[\frac{1}{2}\sum_{i=1}^d\left(\frac{\partial H_\theta(X)}{\partial x_i}V_i\right)^2+\sum_{i,j=1}^d\frac{\partial ^2H_\theta(X)}{\partial x_i\partial x_j}V_iV_j\right]+\mathrm{const.} \end{align*}\] で Monte Carlo 近似する.ただし,\(V\) はランダムな \(\mathbb{R}^d\) 上のベクトルである.9
やはり \(D^2H_\theta\) が登場しているように思えるが, \[ \sum_{i,j=1}^d\frac{\partial ^2H_\theta}{\partial x_i\partial x_j}V_iV_j=\sum_{i=1}^d\frac{\partial }{\partial x_i}V_i\sum_{j=1}^d\frac{\partial H_\theta}{\partial x_j}V_j=\sum_{i=1}^d\frac{\partial }{\partial x_i}V_i(DH_\theta|V) \] の表示により,一度内積 \((DH_\theta|V)\) を計算してしまえば,以降,この項は自動微分を通じて \(O(d)\) のオーダーで計算できる.
なお,\(V\sim\operatorname{N}_d(0,I_d)\) と取った際の目的関数 \(D_{SF}\) は,元の Fisher 乖離度による目的関数に対して,Hutchinson の跡推定量(正規化流でも出てきた)により Jacobian \(Ds_\theta\) を推定したものとも同一視できる.
SSM の最大の美点は,ノイズが印加された分布 \(\widetilde{p}\) を学習してしまう DSM と違って真の分布 \(p\) を学習できることである.一方で,自動微分の分だけ,4倍ほど計算量が必要になる.
スコアマッチングの目的関数 \(D_F(p,p_\theta)\) は,Contrastive Divergence のある極限に一致する (Hyvarinen, 2007).
ステップサイズ \(\epsilon>0\) の Langevin Monte Carlo 法により \(p_\theta\) からサンプリングした場合の対数尤度の期待値は \[ \operatorname{E}[\nabla_\theta\log p_\theta]=\frac{\epsilon^2}{2}\nabla_\theta D_F(p,p_\theta)+o(\epsilon^2) \] と Monte Carlo 近似されるという (Hyvarinen, 2007).
ここで de Bruijin の関係 \[ \frac{d }{d t}\operatorname{KL}(\widetilde{p}_t,\widetilde{p}_{\theta,t})=-\frac{1}{2}D_F(\widetilde{p}_t,\widetilde{p}_{\theta,t}) \] に似た消息が生じている (Lyu, 2009).なお,\(\widetilde{p}\) とは,\(p,p_\theta\) の分散 \(t^2\) を持った Gaussian i.i.d. ノイズによる摂動とする.
既知の密度 \(p_n\) と対置させ,これをノイズとしてデータ分布 \(p\) との識別を繰り返すことで学習を行う.
\(Y\sim\mathrm{Ber}\left(\frac{\nu}{1+\nu}\right)\) に関する混合を \[ \widetilde{X}:=YX+(1-Y)N,\qquad N\sim p_n,X\sim p, \] と定め,これに対して混合分布族 \[ p_{n,\theta}:=\frac{1}{1+\nu}p_n+\frac{\nu}{1+\nu}p_\theta \] を KL-乖離度の意味でマッチさせることを目指す.
重点サンプリング法の提案分布のように,\(p_n\) は真のデータ分布 \(p\) に近ければ近いほどよい (M. U. Gutmann and Hirayama, 2011).
従って多くの方法では,\(p_n\) を適応的に選ぶことが考えられる.
\(p_n\) を \(p\) の摂動 \[ p_n(x):=p(x-v) \] とした場合,\(\|v\|_2\to0\) の極限において,\(V\) に関するスライススコアマッチングの目的関数 3.5 に一致する (M. U. Gutmann and Hirayama, 2011), (Song et al., 2019).
ノイズ対照学習は,距離学習や埋め込み,特に word2vec (Mikolov, Chen, et al., 2013), (Mikolov, Sutskever, et al., 2013) などの言語の埋め込みに応用される.
ノイズ対照推定のノイズ分布を,正規化流 を用いて敵対的に高難易度にしていく.この状況で,EBM とフローベースモデルを同時に学習することを考える手法である.
Stein 乖離度は,Fisher 乖離度の1つの \(s_\theta\) を動かして得るダイバージェンスである: \[ D_S(p,p_\theta):=\sup_{f\in\mathcal{F}}\operatorname{E}\left[s_\theta(X)^\top f(X)+\operatorname{div}(f(X))\right]. \]
Fisher 乖離度の難点は発散項の計算が \(O(d^2)\) の計算量を持ってしまうことであった.Stein 乖離度はこれをカーネル法の方法で迂回することができる.
\(\mathcal{F}\) がある RKHS の単位閉球であった場合,発散項は定数になる (Chwialkowski et al., 2016), (Q. Liu et al., 2016).
(Murphy, 2023) 24.5.3 も参照.
Energy-based model は独立成分分析の研究 (Teh et al., 2003) において命名され,スコアマッチングの (Hyvärinen, 2005) も非線型独立成分分析の大家である.
Awesome-EBM レポジトリは,種々の EBM のリストを与えている.
系統的なイントロダクションには (Bishop and Bishop, 2024) 14.3節,(Murphy, 2023) 24章が良い.
訓練方法について (Song and Kingma, 2021) が詳細なサーベイを与えている.上の2つの教科書の記述も多くはこのサーベイに基づいている.
non-normalized probabilistic model ともいう (Song and Kingma, 2021).この形の分布族を 正準分布 または Gibbs 分布 (Koller and Friedman, 2009, p. 108), (Friedli and Velenik, 2017, p. 25),または Boltzmann 分布 (Kim and Bengio, 2016), (Mézard and Montanari, 2009, p. 23), (Chewi, 2024) ともいう.物理の用語では \(e^{H(z)}\) を Boltzmann 因子と呼ぶのみであるようである (田崎晴明, 2008, p. 107).(J. S. Liu, 2004, p. 7) ではどちらも掲載している.正準集団は,NVT 一定集団ともいう.↩︎
今回の表示は特に SMC と相性が良く,(Zhao et al., 2024) では \(p'(x|z)\) を段階的に近似する列を通じた twisted SMC という手法を提案している.↩︎
だが,正規化定数 \(Z\) が評価できないという前提で EBM の理論は進むため,有向グラフで定義される VAE などのモデルを EBM とみる積極的な理由はない.↩︎
なお,2つの Hamiltonian \(H\) の形は同じで温度が違うのみである.加えて,用途も違う:Hopfield ネットワークは連想記憶のモデル,Boltzmann 機械はデータ分布の(生成)モデリングに用いられる (Carbone, 2024, p. 4).↩︎
MoE (Mixture of Expert) (Jacobs et al., 1991) と並んで使う用語である.↩︎
通常,スコア関数といったとき,微分はパラメータ \(\theta\) について取ることに注意.↩︎
\(D_F(\widetilde{p},p_\theta)\) を近似する Monte Carlo 推定量の分散が大きくなる.↩︎
(Song et al., 2019) では \(V\sim\operatorname{N}_d(0,I_d)\) とすることで Monte Carlo 近似による追加の誤差を回避している.↩︎