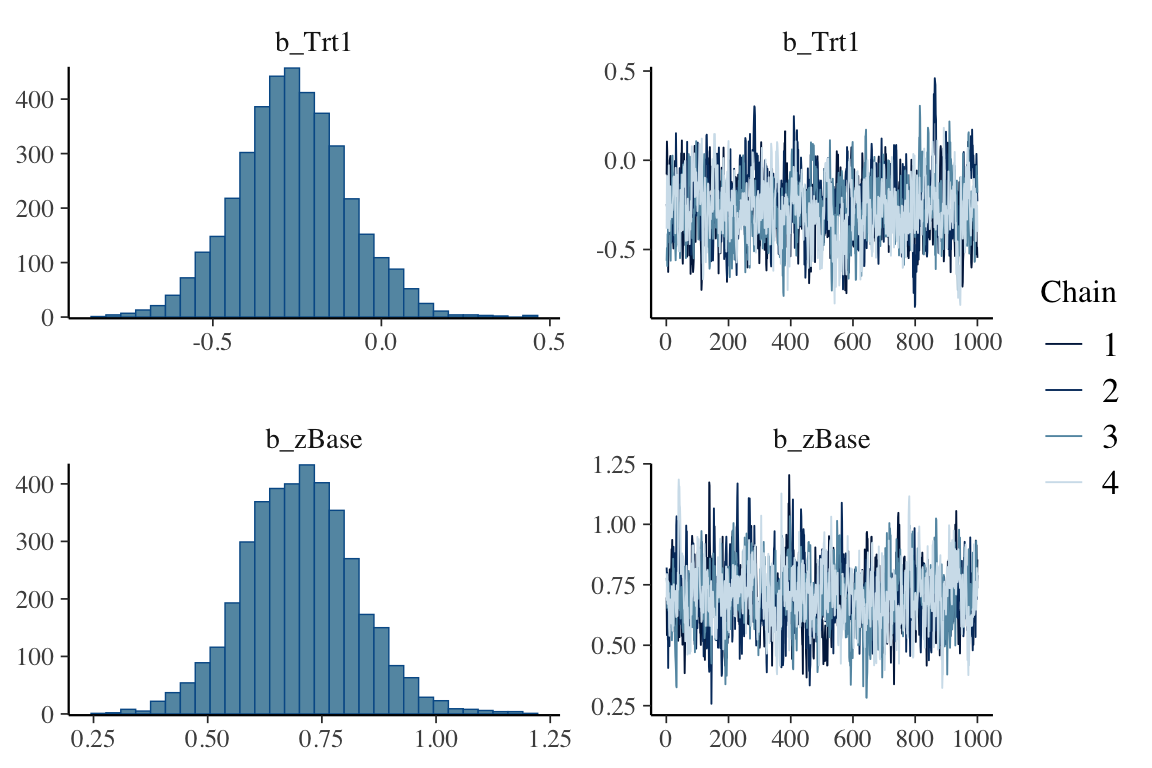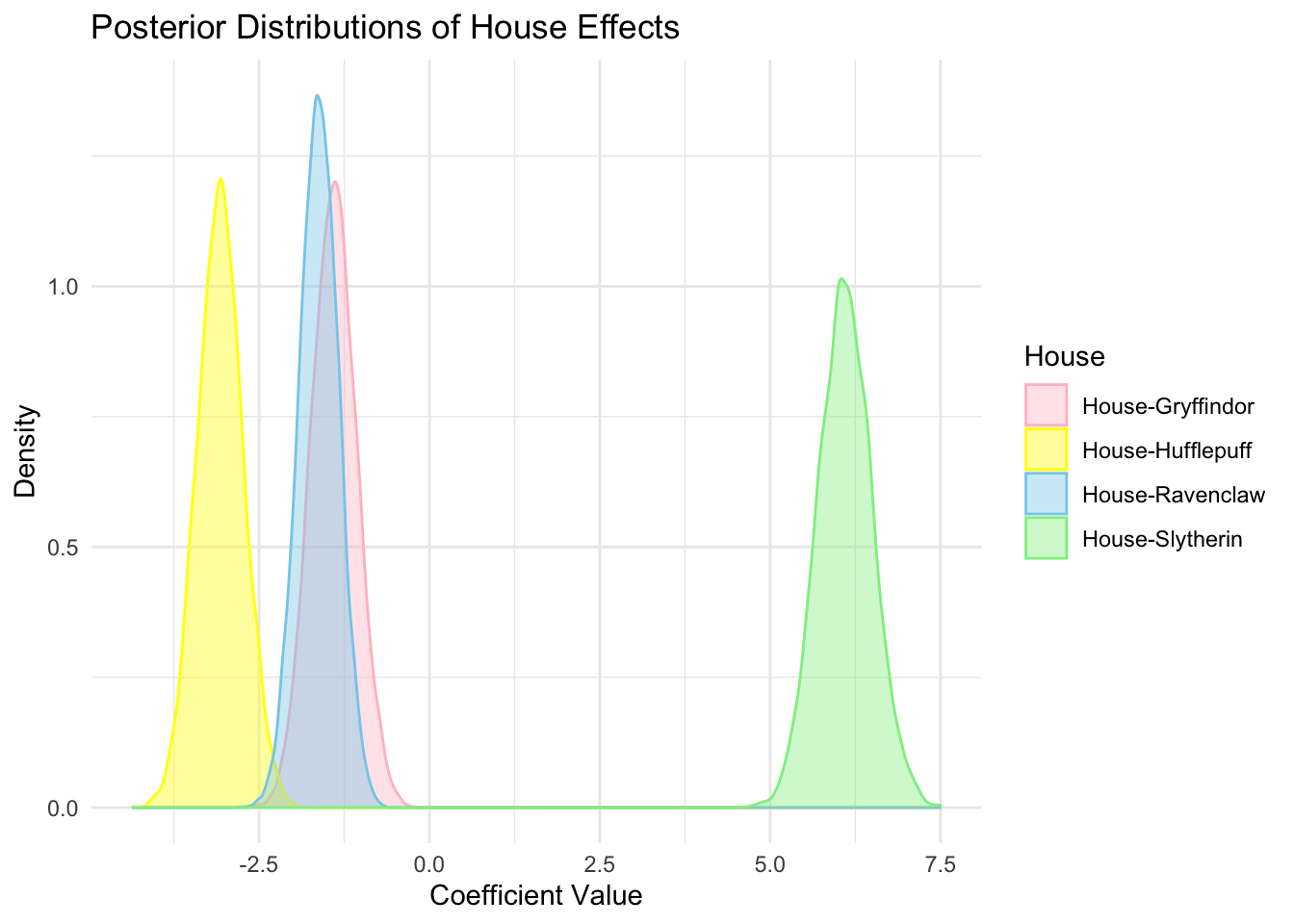
ベイズ分散分析のモデル解析
心理学実験を題材として
2024-09-24
心理学などの人間を対象にする研究では変数の数が多く,正しいモデルを見つけるために分散分析 (ANOVA) が広く用いられる. しかし古典的な ANOVA 解析手法である F-検定や t-検定は,データの一側面しか伝えない. これらの問題点を解決策としてベイズの方法を導入し,ベイズ ANOVA,ベイズ推論とモデル比較が ANOVA の発展として得られることをみる. この拡張は,ANOVA の線型モデルとしての解釈を通じてなされ,ANOVA の「同じ係数を共有するクタスタ構造の特定手法」というより広い理解へ導かれる.
A Blog Entry on Bayesian Computation by an Applied Mathematician
$$
$$
分散分析 (ANOVA: Analysis of Variance) は標本がある因子 \(A,B,\cdots\) によって層別されている場合に,層間の平均効果 \(\mu_i\) に差があるかどうかを検定する手法である: \[ H_0:\mu_1=\cdots=\mu_p\quad\text{v.s.}\quad H_1:\exists_{i,j\in[p]}\;\mu_i\ne\mu_j. \]
因子 \(A,B,\cdots\) の総数に応じて,\(A\) のみの場合を一元配置分散分析,\(A,B\) の場合を二元配置分散分析などという.
多くの場合,観測のモデルには 線型 Gauss の仮定が置かれる.例えば一元配置である場合, \[ Y_{ij}=\mu_i+\epsilon_{ij},\qquad i\in[p],j\in[n_i],\epsilon_{ij}\sim\operatorname{N}(0,\sigma^2), \tag{1}\] というモデルを仮定し,パラメータ \(\mu_i\) に関して検定を行う.
二元配置では \[ Y_{ij}=\mu+\alpha_i+\beta_j+\epsilon_{ij} \] となり,集団は2つの軸 \(A,B\) で層別されており(分割表の状態),それぞれの因子からの効果 \(\alpha_i,\beta_j\) が説明変数に加法的に加えられる.
分散分析では観測 \(Y_{ij}\) の変動のうち,\(H_0\) の仮定の下で説明されなかった部分(残差) \(R_1^2\) と,そもそも線型 Gauss 模型 (1) では説明しきれない部分 \(R_0^2\) とに関して, \[ F:=\frac{(R^2_1-R^2_0)/q}{R^2_0/(n-r)} \] を考える.ただし,\(r:=\operatorname{rank}(X)\) はデータの自由度とした.
この \(F\) は,各群への所属表すダミー変数を用いた回帰分析の残差 \(R_0\) と,各群への所属を考慮しない回帰分析による残差 \(R_1\) とを,自由度を考慮して比を取った形をしている.
この \(F\) は一般に非心 F-分布に従い,仮定 \(H_0\) が成り立つときのみ 中心 F-分布 \(\mathrm{F}(q,n-r)\) に従う.これは各群への所属情報に何の情報量もない場合には,\(F\) が同じ平均を持つ正規確率変数の自乗和の比になるためである.
換言すれば,非心パラメータ \[ \delta:=\frac{1}{\sigma^2}\sum_{i=1}^pn_i(\mu_i-\overline{\mu})^2 \] に関して \(H_0:\delta=0\) を検定することに等しい (Bertolino et al., 1990), (Solari et al., 2008).
この \(F\) (または等価な \(t,\delta\))を検定統計量として仮設検定を実行するのが (repeated measures) ANOVA である.
「標本が正規分布に従う母集団からの独立標本である」という帰無仮説を持つ検定に,(Shapiro and Wilk, 1965) の検定などがある.
探索的な方法には Q-Q plot などがある.(van den Bergh et al., 2020) も参照.
等分散の仮定をチェックする検定には (Mauchly, 1940) の検定や (Brown and Forsythe, 1974) の検定などがある.
仮にこれらの仮定が破られた場合は,(Kruskal and Wallis, 1952) 検定などのランクベースの ANOVA 手法を用いることができる.1
ただし,検定はデータの一側面しか伝えていない.例えば,データが帰無仮説をどれほど支持しているかの尺度は検定では得られない.
それゆえ,ANOVA などのモデルの仮定を確認するためには,検定だけでなく他の探索的手法と組み合わせることが推奨される.(Tijmstra, 2018) も参照.
一方で ANOVA を含めた検定は一面のみを強調する構造となっており,一連の統計解析の中で自然な位置付けを持つものでない.
特に,\(p\)-値による仮設検定は「データが不十分であることにより判断ができない」ことと,「データと帰無仮説は激しく矛盾する」こととを区別できない.この意味でも限定的な情報量しか持たない.
例えば \(p\)-値が小さく帰無仮説が棄却されたとしても,\(p\)-値はモデルの変化に対して頑健ではないかもしれず,実際はほとんど帰無仮説が成り立つことが真実かもしれない.
このような全貌を探索的に捉えるためには,検定を金科玉条とするのではなく,広くモデル比較・モデル選択の観点からアプローチすることが大切である.同様のことが (Rouder et al., 2016) でも論じられている.
ANOVA は,特に大規模なものが,現在でも実験心理学などの分野で広く用いられている.これは心理学では多くの因子 \(A,B,C,\cdots\) が存在し,それぞれが複雑な関係にあるためである.
しかし推定法も従来の \(F\)-検定を用いたのではその力を十分に発揮できない.解決は丁寧な階層モデリングとベイズによる探索的な解析にある.2
”if you have a complicated data structure and are trying to set up a model, it can help to use multilevel modeling”—not just a simple unitswithin-groups structure but a more general approach with crossed factors where appropriate. This is the way that researchers in psychology use ANOVA, but they are often ill-served by the classical framework of mean squares and F-tests. We hope that our estimation-oriented approach will allow the powerful tools of Bayesian modeling to be used for the applied goals of inference about large numbers of structured parameters. (Gelman, 2005, p. 53)
ベイズ分散分析 (Rouder et al., 2012), (Rouder et al., 2016) では,(1) などの線型モデルに対して,パラメータが零ベクトルであることに対する検定の代わりに,帰無仮説を表現するモデルに対する Bayes 因子を用いたモデル比較を行う.
つまり,ベイズ分散分析と言った場合,「分散分析」の概念は完全に線型回帰モデルのベイズ推論に回収される.より正確には,階層モデルのベイズ推論は「分散分析」の正統な後継である (Gelman, 2005).
In this sense, ANOVA is indeed a special case of linear regression, but only if hierarchical models are used. (Gelman, 2005, p. 2)
(Rouder et al., 2012) はその際の標準的な事前分布の選択について議論している(第 2.4 節).
(Rouder et al., 2016) が指摘するように,分散分析がベイズ化される過程で,検定がモデル比較に置き換わっている.
ベイズ的な仮設検定は (Jeffreys, 1961) に源流を持つ.一般に,位置母数の事前分布に Cauchy 分布を用いることは (5.3節 Jeffreys, 1961) に源流を持つ.このことについては (Robert et al., 2009) も参照.
同一の単位を繰り返し測定し, \[ Y_i\overset{\text{i.i.d.}}{\sim}\operatorname{N}(\mu,\sigma^2),\qquad i\in[n], \] に従って何らかの処置効果 \(Y_i\) 観測するとし,帰無仮説 \(\mu=0\) の妥当性を議論したいとする.
この際,まずは効果サイズ (effect size) (Cohen, 1988) \(\delta:=\mu/\sigma\) という無次元量にパラメータを変換し,これを Cauchy 分布と比較することを考える: \[ M_0:\delta=0\quad\text{v.s.}\quad M_1:\delta\sim\mathrm{C}(0,1) \]
実際,この Cauchy 分布というのは変換 \(J(\nu,\sigma):=\frac{\mu^2}{\sigma^2}\) を通じて \(\mathbb{R}\) 上の Jeffreys 事前分布(この場合は Lebesgue 測度に一致)に(ほとんど)等価になる.
この2つのモデル \(M_0,M_1\) の残りの仮定は共通の Jeffreys の事前分布 \(p(\sigma^2)\,\propto\,\sigma^{-2}\) で共通とし,Bayes 因子を算出する.
この値を検定統計量のように扱うとき,これを Jeffreys の名前に (Zellner and Siow, 1980) を加えて JZS 因子 (Bayarri and García-Donato, 2007) という.あるいは上述の事前分布の選び方を JZS 事前分布という.
JZS 因子は,事前のモデル確率 \(p(M_0),p(M_1)\) に依らずに算出できる.
JZS 因子は \(p\)-値と比較して,サンプルサイズが大きいほど保守的になる傾向がある.(Wetzels et al., 2011) は 2007 年に特定の実験心理学雑誌に投稿された 855 件の t-検定に対して,JZS 因子と \(p\)-値との値を報告してこれを観察している.
(van den Bergh et al., 2023) は実例を用いて,特に複雑な心理学実験において,2つの解析手法はときに全く違う結論を導くことを例証している.
また JZS 因子は \(N\to\infty\) の極限で,\(\delta\ne0\) であった場合は \(\infty\) に発散し,\(\delta=0\) であった場合は \(1\) に収束するという性質を持つ.
1元配置 ANOVA のモデルを次のように表す: \[ \boldsymbol{Y}=\mu\boldsymbol{1}_n+\sigma\boldsymbol{X}\boldsymbol{\theta}+\boldsymbol{\epsilon},\qquad\boldsymbol{\epsilon}|\sigma^2\sim\operatorname{N}(\boldsymbol{0},\sigma^2I_n). \tag{2}\] 各水準 \(i\in[p]\) に属するデータの数を \(n_i\) とすると \[ \boldsymbol{X}=\begin{pmatrix} \boldsymbol{1}_{n_1} & \boldsymbol{0} & \cdots & \boldsymbol{0}\\ \boldsymbol{0} & \boldsymbol{1}_{n_2} & \cdots & \boldsymbol{0}\\ \vdots & \vdots & \ddots & \vdots\\ \boldsymbol{0} & \boldsymbol{0} & \cdots & \boldsymbol{1}_{n_p} \end{pmatrix},\qquad\boldsymbol{\theta}=\begin{pmatrix} \mu_1\\ \mu_2\\ \vdots\\ \mu_p \end{pmatrix}. \] となる.
このとき,定数項 \(\mu\) をすでに括り出しているので,\(\boldsymbol{\theta}=0\) の場合のモデルが帰無仮説に対応する.
対立仮説としては,\(\boldsymbol{\theta}\) 上に次の \(g\)-prior を定める: \[ \boldsymbol{\theta}\sim\operatorname{N}(\boldsymbol{0},G),\qquad G=\mathrm{diag}(g_1,\cdots,g_p),\qquad g_i\overset{\text{i.i.d.}}{\sim}\chi^{-2}(1). \] これは各 \(\mu_i\) に対して独立な Cauchy 事前分布を仮定している.
(Zellner and Siow, 1980) の事前分布 \[ \boldsymbol{\theta}|g\sim\operatorname{N}(\boldsymbol{0},g(\boldsymbol{X}^\top\boldsymbol{X}/n)^{-1}I_p) \] や一般の \(g\)-prior との違いとして,スケール因子 \((\boldsymbol{X}^\top\boldsymbol{X}/n)^{-1}\) がない形であるのは,ANOVA の説明変数 \(\boldsymbol{X}\) が離散変数であるためである.
以上のモデルを,帰無仮説に対立させる「デフォルトモデル」として提案したのが (Rouder et al., 2012) である.
特に \(G=gI_p\) の場合は,結果として得られるベイズ因子は1次元の積分のみを含むため,簡単な数値積分アルゴリズムによって計算可能である.
多くの場合,被説明変数に関連すると予期される因子は複数存在する.ここでは2元配置の場合を考える.それぞれの因子が \(a,b\) 水準を持つとき,フルモデルは \[ \boldsymbol{Y}=\mu\boldsymbol{1}+\sigma\biggr(\boldsymbol{X}_\alpha\alpha+\boldsymbol{X}_\beta\beta+\boldsymbol{X}_{\gamma}\gamma\biggl)+\boldsymbol{\epsilon}, \] と表せる.
詳しくは (Section 8 Rouder et al., 2012) を参照.
ベイズ因子を含め,周辺尤度 \(p(\theta|y)\) (エビデンスともいう)を用いた指標は,モデルの仮定に対して感度が高い (Robert, 2016), (Kamary et al., 2018).
そのため「モデルのデータへの当てはまりの良さを1つの指標にまとめた値」としては少し心許ない.
加えて,帰無仮説に対立させる仮説を構成して,二項対立の構造に持ち込むことは,自然なデータ解析のワークフローに必ずしも入ってこない.
ベイズ推論の仮定で得られる事後分布から,特定の仮説 \(H:\theta=\theta_0\) がまともかを評価する方法の方が,探索的データ解析の観点からは含意が多いことも多い.
ANOVA とベイズ ANOVA の究極的な目標は,平均が一致する \[ H_0:\mu_1=\cdots=\mu_p \] という仮説がデータからどれほど支持されるか/されないかを評価することにある.
最も直接的な方法は,パラメータ空間上に描かれる事後分布を見ることである.信用区間を報告し,帰無仮説がそのどこに位置するかを見ても良いだろう.
このように,ベイズ事後分布やそのサンプルを通じたモデル検証方法は posterior predictive check (Gelman and Shalizi, 2013) と呼ばれ,これを多角的に行うことが一つの理想形とされている (Gelman et al., 2020).
同様に (Kruschke, 2015) では,モデル (2) の形を一般化線型モデルの特別な場合と見て推定し,ANOVA をモデル比較の観点から適切に実行する方法を論じている.
このように,ANOVA を適切に扱うには,階層モデルとしての取り扱いが欠かせない.同様の議論は (Gelman, 2005) でも展開されている.
ここでは,以下の節で帰無仮説 \(H_0\) の妥当性を詳細に評価するための方法を見ていく.
Bayes 因子の他に,検定統計量に対するベイズ事後予測分布を導出し,その裾確率を評価して \(p\)-値の代替とする方法もある.
これは 事後予測 \(p\)-値 (posterior predictive \(p\)-value) (Gelman et al., 2014, p. 146) と呼ばれる.
ROPE は帰無仮説 \(H_0\) と区別がつかないとする区間である.
帰無仮説が \(H_0:\theta=\theta_0\) という形をしていた場合,ほとんどの場合 \(\theta=\theta_0+0.1\) でも事実上変化はない.
このように,帰無仮説と同一視してしまう範囲を ROPE (Kruschke, 2015, p. 336) という.
この ROPE が 95% 最高密度信用領域 (HDR: Highest Density Region) と互いに素になるときに,「棄却」されたとする.
ただし,最高密度信用領域とは 95% 信用区間=95% の事後確率を持つ領域のうち,面積が最も小さいもののことを言う.
この方法では,逆に HDR が ROPE を完全に含む場合,帰無仮説を「採択」するという積極的な意思決定も可能である.
ROPE と同様の考え方は,ベイズによる実験計画法でも range of equivalence (Freedman et al., 1984), (Spiegelhalter et al., 1994) の名前で用いられてきた歴史がある.
または,事後確率分布が ROPE 内にどれほどの確率を与えるかを見ることもできる (Kruschke, 2018).
ROPE の応用と実装は (Kelter, 2022) も参照.
ベイズの方法の特徴は,検定・モデル比較と推論とに区別がないことである.
加えて純粋に検定・モデル比較のための手続きを作るより(ベイズ因子など),推定の一種として扱った方がより多くの情報を引き出せるため,ワークフローとしては好ましい (Kruschke, 2011).
(Robert, 2016), (Kamary et al., 2018) では検定の対象となっているモデル \[ M_1:x\sim f_1(x|\theta_1)\quad\text{v.s.}\quad M_2:x\sim f_2(x|\theta_2) \] を,混合モデル \[ M_\alpha:x\sim\alpha f_1(x|\theta_1)+(1-\alpha)f_2(x|\theta_2) \] の成分の1つとみなし,その荷重 \(\alpha\) の事後分布を推定し,これを検定に用いるという方法が提案されている.
同様の発想により,ベイズ因子の計算と推論によるモデル比較とを,より大きなハイパーモデルを立てることで同時に実行することもできる.
(Kruschke, 2011, p. 308) や (O’Neill and Kypraios, 2016) などで考えられている.
応用分野の研究者に対する「なぜベイズを使うのか?」に対する端的な回答として,「統計的有意性」などの「わかりやすい」指標に飛びついた結果,真のデータの声を聞かずに自分の見たいものを見始めてしまうと言うことが少なく,「自己欺瞞に陥りにくい」という美点があることは,ベイズ機械学習の稿 でも触れた.
\(p\)-値はそのような欺瞞を生む代用例であり,使用を禁止すべきとの声 (Blakeley B. McShane and Tackett, 2019) もある.その論拠は大まかに次のとおりである.
そもそも \(p\)-値とは,「帰無仮説を採用したモデルはデータへの当てはまりの度合いが悪い」ということを言っているだけであり,\(p\)-値が十分に低ければそれ以上の情報は引き出せない.
当然 \(p\)-値が \(0.01\) であることと \(0.00001\) であることは質的に全く変わらない (Gelman et al., 2014, p. 150).
そのことに加え \(p\)-値は必ずしも頑健な指標ではなく,帰無仮説を少し摂動させただけで \(p\) 値が大きくなってしまうかもしれない.そのような場合は結局ほとんど帰無的であり,「統計的有意性」はほとんど無意味になってしまう.同様の議論が (Gelman and Stern, 2006) で展開されている.
このような現状への対処として,応用分野の研究者にもベイズ統計学は根本的な解決法として広く推奨される (Dienes and Mclatchie, 2018).(Wagenmakers et al., 2016) はその旨を2つの実例を通じて簡潔に実証しており,同時にベイズ統計学の考え方に対する洗練された導入を行なっている.
(van den Bergh et al., 2020) は分散分析をベイズの方法によって実行する手引きを,特に JASP を用いて実演している.
JASP のベイズ ANOVA のエンジンは R パッケージ BayesFactor (CRAN / GitHub) を用いている.BayesFactor では大規模な \(M\)-元配置 ANOVA モデルにおいても Bayes 因子を用いたモデル比較を行うことができる.
ベイズ ANOVA の R パッケージとしては bayesanova (CRAN / GitHub) (Kelter, 2022) もある.これは検定に似た行為を根本的に排除して Gauss 混合モデルとして Gibbs サンプラーによるベイズ推定を実行し,ROPE (Region of Practical Equivalence) (Kruschke, 2015, p. 336) (Kruschke, 2018) を用いたモデル比較を行う.
もちろんこのような完全なモデリングを行うことが理想かもしれないが,従来の ANOVA になれきっている研究者にとっては,Bayesian ANOVA に手を伸ばしてみることが次のステップとして大変良いだろう.
また別の角度からの「ベイズを使うべき理由」としての説得的な議論としては,ベイズ階層モデリングは ANOVA の正統進化という理解 (Gelman, 2005) ができるという向きもある.
以上の立場は (Gelman et al., 2014) や (Kruschke, 2015) などの標準的なベイズデータ解析の教科書でも一貫している.
F-検定については (吉田朋広, 2006) と (Solari et al., 2008) を参考にした.
ANOVA の歴史については (Tweney, 2014) を参照.(repeated measures) ANOVA は多重線型回帰のうち説明変数が離散変数である場合に相当するという理解は,一般化線型モデルの発展と普及に伴って理解が広がった.
もちろん,Stan などの確率的プログラミング言語を用いた完全なベイズモデリングはいつでも実行可能である.↩︎
そして因子分析を通じて,記述統計学の正統進化であるということもできる!? ANOVA の歴史については (Tweney, 2014) も参照.↩︎